







进程是什么?
进程是资源分配的最小单位
线程是什么?
线程是操作系统能够运行调度的最小单位,它被包含在进程之中,是进程中的实际操作单位。
线程和进程与堆栈的关系?
与线程绑定的是栈,用于存储自动变量。每一个线程建立的时候,都有新建一个默认栈与之配合。
堆则是与进程有关,用于存储全局性的变量。进程建立的时候,会建立默认的堆。
于是每个线程都有自己的栈,然后访问共同的堆。
线程和进程的区别?
线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。每个进程拥有自己的地址空间,而线程共享进程的地址空间,所以线程可以访问进程中定义的共享变量(同时这也是为什么在多线程环境下需要互斥保护共享变量的原因)。
Java中线程的实现方式?
实现方式有四种,平时用到的大多为两种。
1.继承Thread类创建线程(本人用的比较少,缺点是Java的单继承的局限)
这种方式没什么,直接举例:
public class MyThread extends Thread {
public MyThread() {
}
public void run() {
for(int i=0;i<10;i++) {
System.out.println(Thread.currentThread()+":"+i);
}
}
public static void main(String[] args) {
MyThread mThread1=new MyThread();
mThread1.start();
}
}
需要注意的是,start()方法只能被调用一次,调用两次会抛异常,注意点就行了
2.实现Runnable接口创建线程
public class MyThread implements Runnable{
public void run() {
for(int i=0;i<10;i++) {
System.out.println(Thread.currentThread()+":"+i);
}
}
public static void main(String[] args) {
MyThread Thread1=new MyThread();
Thread mThread1=new Thread(Thread1,"线程1");
mThread1.start();
}
}
3.通过Callable接口实现多线程
实现方式其实和实现Runnable的方式其实差不多,但是功能多了很多,可以根据自己的需求选择
相比Runnable的优点:可以在任务结束后提供一个返回值,call方法可以抛出异常,而且可以通过运行Callable得到Fulture对象监听目标线程调用call方法的结果,得到返回值
public class MyCallable<String> implements Callable<String> {
private int tickt=10;
@Override
public String call() throws Exception {
// TODO Auto-generated method stub
String result;
while(tickt>0) {
System.out.println("票还剩余:"+tickt);
tickt--;
}
result=(String) "票已卖光";
return result;
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
MyCallable<String> mc=new MyCallable<String>();
FutureTask<String> ft=new FutureTask<String>(mc);
new Thread(ft).start();//申请调用io,cup等资源
String result=ft.get();
System.out.println(result);
}
4.线程池
因为在实际操作中,线程池还是重点使用的,所以本文对线程池会重点讲述
线程池的概念?
线程池其实就是一种对象池,用于管理线程资源,执行任务前,将线程从线程池中拿出,执行完,再放回去,反复利用,可以有效避免直接创建线程导致的资源浪费等等问题。
线程池的好处?
1.降低资源消耗,线程本身是一种资源,线程的创建和销毁是一种非常耗时的操作,会占用CUP资源,和占用内存
2.提高响应速度,可以不用创建完线程再去执行任务
3.提高线程的可管理性。线程不能无限制地创建,需要进行统一的分配、调优和监控。
不使用线程池的坏处?
1.线程的数量无节制,太多导致资源的极大的浪费,和线程频繁切换的压力,线程太少,CPU得不到足够的利用,而且任务执行速度跟不上
2.频繁的线程创建和销毁,导致CPU和内存都会有很大的压力
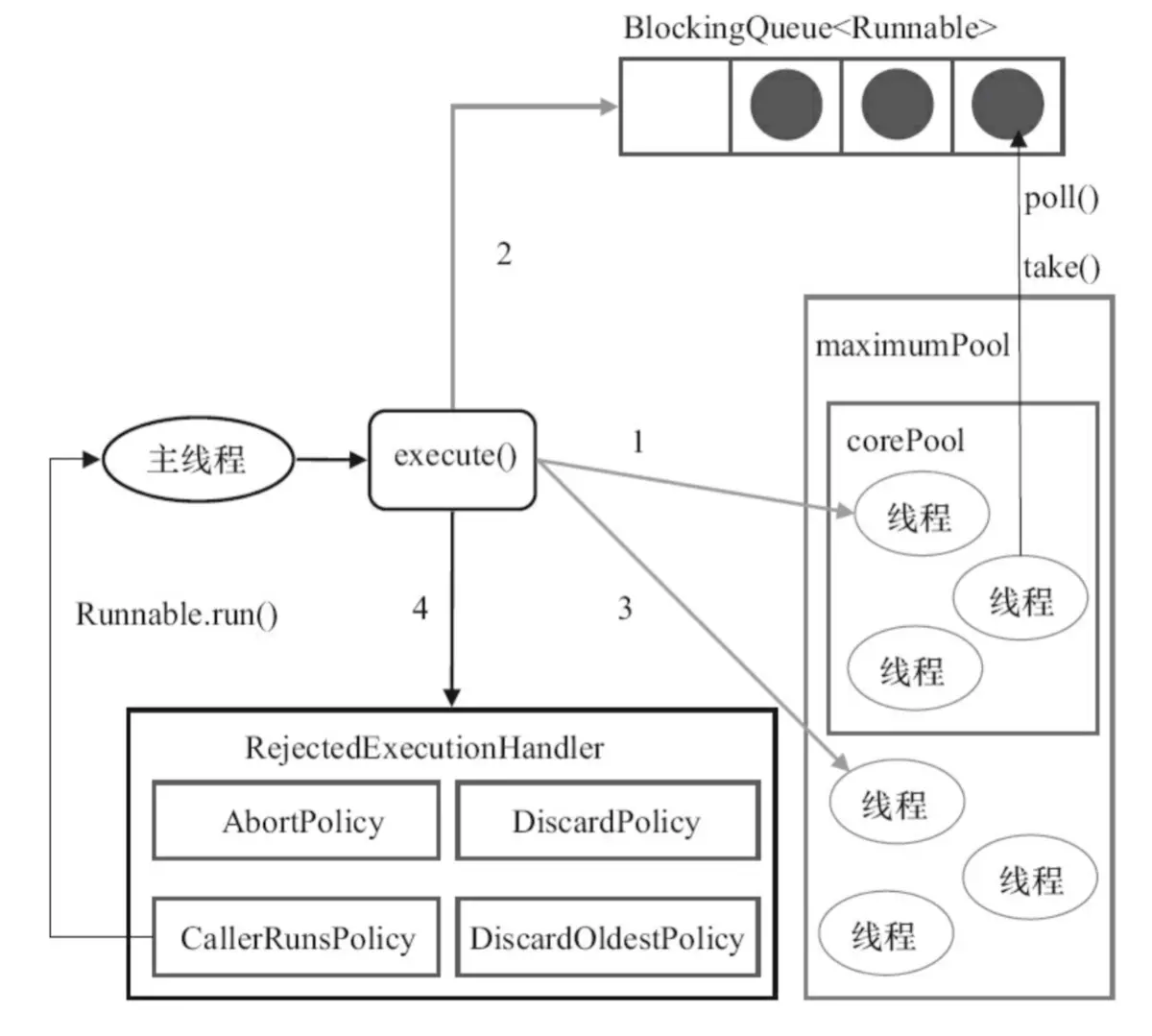
线程池的实现原理?(借用别人的一张图)
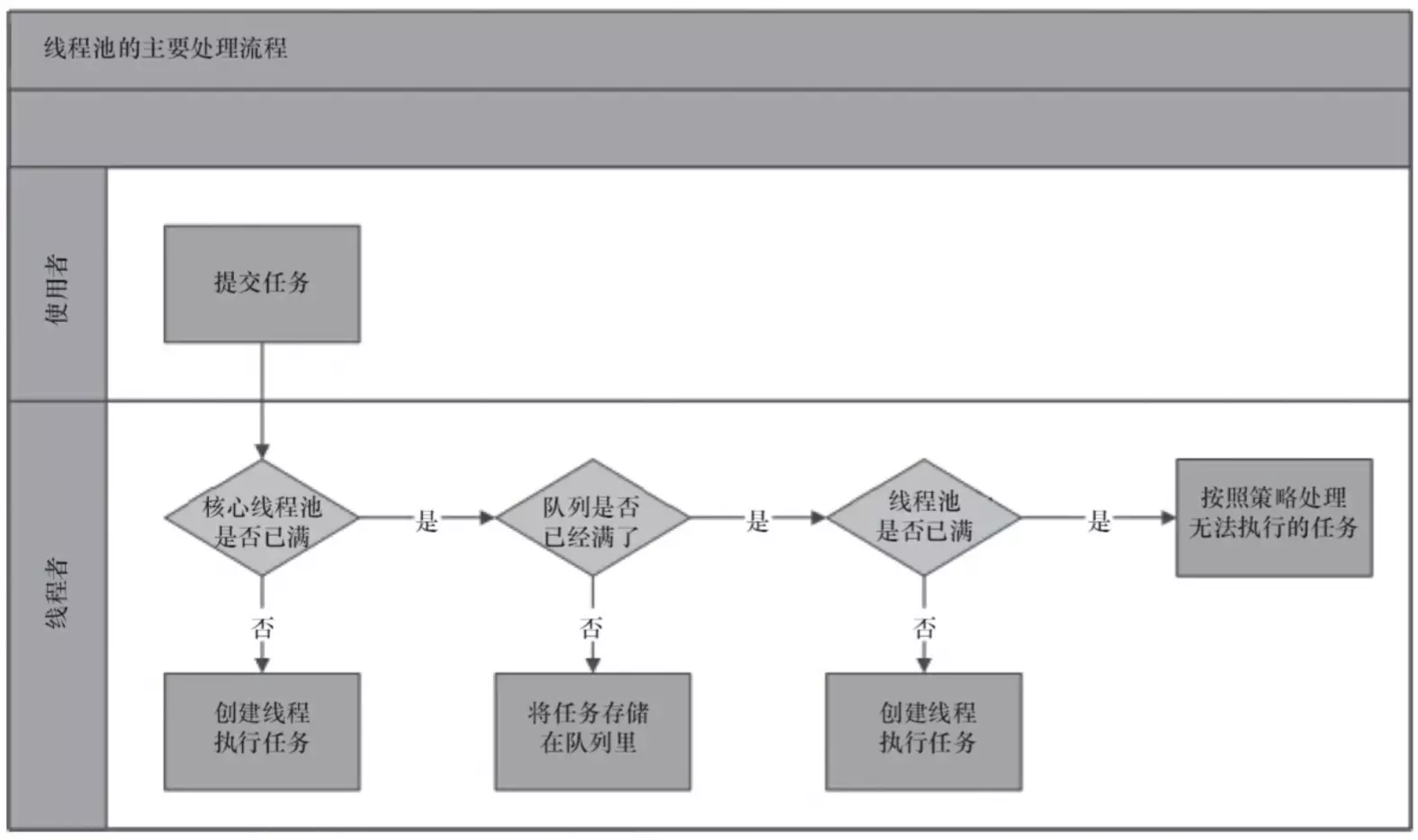
参照线程池的创建方法看图
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) 1.corePoolSize 核心线程池的大小
2.maximumPoolSize 线程池的最大值
3.keepAliveTime 线程存活时间
4.unit 时间单位
5.workQueue 任务队列(队列方案后面再说)
6.ThreadFactory 线程工厂
7.handler 拒绝策略(就是添加任务到队列失败以后如何处理)
线程池处理流程大概是这个样子
JAVA的四种线程池,和是否推荐
1.newCachedThreadPool
创建一个可缓存式线程池,如果线程池长度超过所需要的,可回收空闲线程,若没有可回收的,可以创建新的线程。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以看到maximumPoolSize 为Integer.MAX_VALUE,允许创建线程数基本为无限大,可能会导致oom的情况出现2.newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数量,超出的线程在队列中等待
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}源码分析可知,允许的请求队列的长度为Integer.MAX_VALUE,可能会堆积大量请求,从而导致OOM
3.newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行.
不推荐理由和newCachedThreadPool差不多
4.newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
不推荐理由和newFixedThreadPool差不多
如果可以还是建议手动创建线程池,因为Java本身提供的线程池并不是一定就那么适合我们的项目,当然如果不用考虑那么极端的情况,也是能够使用的,毕竟方便,哈哈哈
手动创建线程池
创建方法为:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) 主要需要了解的两个参数就是队列和拒绝策略,以便更加方便来手动创建线程池
等待队列 workQueue主要为三种
ArrayBlockingQueue
ArrayBlockingQueue是基于数组的有界缓存等待队列,可以指定缓存的队列大小,当正在执行的线程数等于corePoolSize时,多余的元素缓存在ArrayBlockingQueue队列中等待有空闲的线程时继续执行,当ArrayBlockingQueue已满时,加入ArrayBlockingQueue失败,会开启新的线程去执行,当线程数已经达到最大的maximumPoolSizes时,再有新的元素尝试加入ArrayBlockingQueue时会报错。
举例说明:
此时创建一个线程池,corePoolSize为2, maximumPoolSizes设置为5,此时队列为 new ArrayBlockingQueue(2),此时缓存队列为2,任务数目设置为10个, 此时任务1,任务2,会先在核心线程中执行,然后任务3,4会在缓存队列中,任务5,6,7,8,9.10进来的时候,此时发现没有空余线程,而且也没有达到最大线程数,然后新建线程去处理5,6,7,此时达到最大线程数,此时8,9,10进不了缓存队列,也无法新建线程去执行,没办法只能去执行拒绝策略
LinkedBlockingQueue
LinkedBlockingQueue是基于链表实现的可以为无界,可以为有界的阻塞队列,如果没有指定大小为无界(很多文章都直接默认为无界是有问题的,看源码可以看到的)。当前执行的线程数量达到corePoolSize的数量时,剩余的元素会在阻塞队列里等待。(所以在使用此阻塞队列时maximumPoolSizes就相当于无效了),每个线程完全独立于其他线程。生产者和消费者使用独立的锁来控制数据的同步,即在高并发的情况下可以并行操作队列中的数据。
SynchronousQueue
SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
LinkedBlockingQueue和ArrayBlockingQueue的两者之间的差异选择
LinkedBlockingQueue可以为无界的,而且生产者和消费者之间锁不是一样的,生产者的锁putLock,消费者的锁takeLock,
LinkedBlockingQueue会具有更好的吞吐量,因为它用2个diff锁进行put和take,并且仅在边缘条件下同步,而且占用大小应该和自身大小一致,但是删除的节点可能会变成垃圾,影响性能
ArrayBlockingQueue 中添加元素应该更快,因为它意味着只设置对后备object数组元素的引用,但是数组会占用大的内存块
怎么使用,看个人需求了。
ThreadFactory线程工厂
源码为:
public interface ThreadFactory {
/**
* Constructs a new {@code Thread}. Implementations may also initialize
* priority, name, daemon status, {@code ThreadGroup}, etc.
*
* @param r a runnable to be executed by new thread instance
* @return constructed thread, or {@code null} if the request to
* create a thread is rejected
*/
Thread newThread(Runnable r);
}
没啥,就是建线程的东西。
RejectedExecutionHandler线程池拒绝策略
1.AbortPolicy --- 当任务添加到线程池中被拒绝时,它将抛出 RejectedExecutionException异常(默认为)
2.CallerRunsPolicy --- 当任务添加到线程池中被拒绝时,会在线程池当前正在运行的Thread线程池中处理被拒绝的任务。(注意,在达到最大线程数,而且队列阻塞的情况下,可能会强制主线程来执行,慎用)
3.DiscardOldestPolicy --- 当任务添加到线程池中被拒绝时,线程池会放弃等待队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
4.DiscardPolicy --- 当任务添加到线程池中被拒绝时,线程池将丢弃被拒绝的任务。















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









