







目录
1.训练集和测试集划分
将数据集划分为训练集和测试集,通常是80%的数据用于训练,20%用于测试。评估模型在未见过的数据上的性能,检查模型是否过拟合或欠拟合
2.交叉验证
将训练集划分为K个折叠(folds),模型训练K次,每次使用K-1个折叠作为训练数据,1个折叠作为验证数据。


注意交叉验证通常是在训练集上进行的。
3.Confusion Matrix-混淆矩阵
混淆矩阵(Confusion Matrix)是在分类问题中用于评估模型性能的一种表格,它展示了模型在测试集上的分类结果与实际类别之间的关系。混淆矩阵以四个重要的指标为基础,这些指标是真正例(True Positive,TP)、真负例(True Negative,TN)、假正例(False Positive,FP)和假负例(False Negative,FN)。例如:
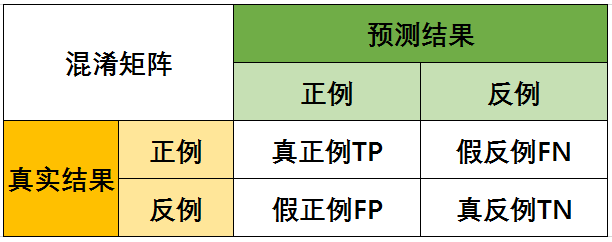
- 真正例(True Positive,TP): 模型正确地将正类别样本预测为正类别。
- 真负例(True Negative,TN): 模型正确地将负类别样本预测为负类别。
- 假正例(False Positive,FP): 模型将负类别样本错误地预测为正类别。
- 假负例(False Negative,FN): 模型将正类别样本错误地预测为负类别。
基于混淆矩阵,可以计算多种性能指标:

例如:

在Mnist手写数据集中,预测是不是5的任务,其混淆矩阵为:

4.ROC曲线
接收者操作特征曲线(Receiver Operating Characteristic,ROC)和曲线下面积(AUC):
用于二分类问题,绘制真正例率(True Positive Rate)和假正例率(False Positive Rate)的曲线。衡量分类模型在不同阈值下的性能,并计算AUC评估整体性能。
TPR = TP / (TP + FN) (Recall)
FPR = FP / (FP + TN)
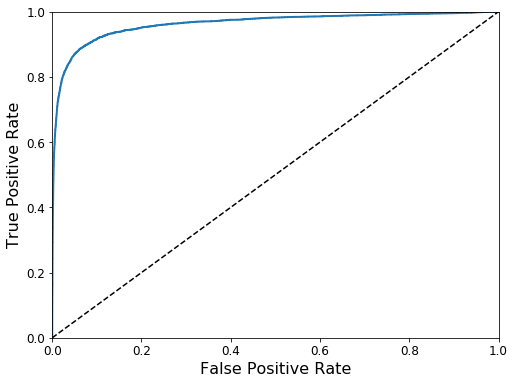
虚线表示纯随机分类器的ROC曲线,一个好的分类器尽可能远离该线(朝左上角)。
比较分类器的一种方法是测量曲线下面积(AUC)。完美分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。















 2760
2760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











