







CEPR: A Collaborative Exploration and Periodically Returning Model for Location Prediction
Abstract
Question
①目前的很多研究都是用Hadamard product、inner product等简单的方法来计算特征交互,对特征的重要性关注较少。
②不同的特征对目标任务有不同的重要性。例如,当我们预测一个人的收入时,特征职业比特征爱好更重要。
Method
引入了一个压缩激励网络(SENET)来动态地学习特征权值。此外,特征交互作用是CTR预测领域的一个关键挑战,许多相关工作采用Hadamard product、inner product等简单方法计算特征交互作用。本文提出了一种计算特征与双线性函数相互作用的新方法。
Model
本文提出了一种新的特征重要度和双线性特征交互网络模型FiBiNET,用于动态学习特征重要度和纹理特征交互。
Squeeze
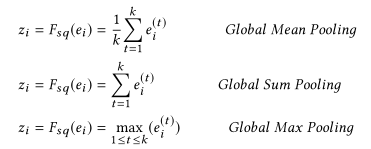
Excitation
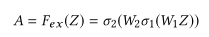
Re-Weight
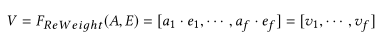
Contribution
①受计算机视觉领域SENET成功的启发,我们利用SENET机制动态地学习特征的权值。
②我们引入了三种类型的双内交互层,以fine-grained的方式学习特征交互。这也与之前的工作形成了对比,后者计算了与Hadamard积或内积的特征交互作用。
③结合SENET机制和双线性特征交互,我们的浅层模型实现了最先进的浅层模型,如在Criteo和Avazu数据集上的FFM。
④为了进一步提高性能,我们将经典的深神经网络(DNN)组件与浅模型相结合,成为一个深模型。在Criteo和Avazu数据集上,deep FiBiNET始终如一地优于其他最先进的deep模型。
Introduction
作者为什么研究这个课题?
①不同的特征对于目标任务具有不同的重要性,要充分考虑特征对于预测结果的重要程度。
②特征交互是CTR预测领域的一个关键挑战,许多相关的工作都是用一种简单的方法来计算特征交互,如哈达玛积和内积。
参考模型介绍
Squeeze-and-Excitation network

归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理。

SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。


双线性特征交互
Bilinear-Interaction Layer

Field-All Type
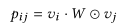
Field-Each Type
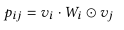
Field-Interaction Type
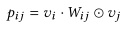
不同类型的双线性交互层的性能取决于数据集。 原因?
相关工作
与现有工作的区别
提出的模型由以下部分组成:稀疏输入层、嵌入层、SENET层、双内交互层、组合层、多重隐藏层和输出层。
①稀疏输入层和嵌入层与DeepFM[4]相同
②交叉特征被合并双线性交互层输出的组合层连接起来。
后续deep part更换DA-RNN,但是第一阶段的注意力机制可以改为之前浅层模型的输出。
Abstract of 《A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction》
非线性自回归外生序列模型(Nonlinear autoregressive exogenous (NARX) model)通过时间序列的以往值以及多重驱动(exogenous)序列的当前值和过去值预测时间序列的当前值,已经研究了几十年。尽管NARX模型已经发展了很多,但很少有模型能够恰当地捕捉到长期的时间依赖性并选择相关的驾驶序列进行预测。在本文中,我们提出一种基于注意力的双阶段递归神经网络(DA-RNN)来解决这两个问题。在第一阶段,我们引入输入注意机制,根据之前编码器的隐藏状态,自适应地提取每个时间步长对应的驱动序列(即输入特征)。在第二阶段,我们使用时间注意机制来选择相关的编码器隐藏状态跨越所有的时间步长。采用这种双阶段注意模式,我们的模型不仅能有效地进行预测,而且易于解释。















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









