







作为使用最广泛的数据库查询语言,SQL 最初由 IBM 研究人员在上个世纪 70 年代基于关系模型开发,它是关系模型的第一个商业实现,同时也是最成功的一个实现。
随着互联网与大数据的发展,数据库领域出现了各种非关系模型,例如文档模型(MongoDB)、图模型(Neo4j)等。基于这些新型模型的数据库不遵循传统关系型数据库的数据模型啊,同时还拒绝了使用 SQL 查询接口,并且提出了 NoSQL(Not Only SQL)的口号。
不过,随着时间的验证,虽然非关系模型可以对关系模型形成很好的补充,但是 SQL 仍然是独一无二的数据库查询语言。尽管 SQL 源自关系模型,但是它早就不再局限于关系模型,无论是面向对象特性(例如复合类型、自定义类型)、文档数据存储(例如 XML、JSON 类型和函数)、复杂事件和流数据处理、数据科学中的多维数组以及图存储(属性图查询语言)等都已经成为 SQL 标准中的一部分。
始于关系
关系模型由Edgar Frank Codd博士于1970年提出,以集合论中的关系概念为基础,无论是现实世界中的实体对象还是它们之间的联系都使用关系表示。我们在关系型数据库中看到的关系就是二维表(Table),由行(Row)和列(Column)组成。因此,也可以说关系表是由数据行构成的集合,一个数据库则包含了多个关系表。
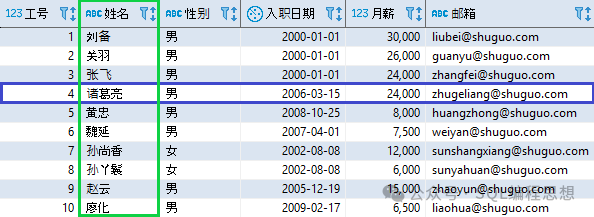
根据定义,关系模型由关系数据结构、关系操作集合以及关系完整性约束三部分组成。SQL 是访问和操作关系型数据库的标准语言,所有的关系型数据库都可以使用SQL语句进行数据访问和控制。主要的 SQL 语句通常被分为以下几个类别:
-
DQL(Data Query Language,数据查询语言)。DQL 也就是 SELECT 语句,用于查询数据和信息。
-
DML(Data Manipulation Language,数据操作语言)。DML 用于对表中的数据进行插入(INSERT)、更新(UPDATE)、删除(DELETE)以及合并(MERGE)操作。
-
DDL(Data Definition Language,数据定义语言)。DDL 用于定义数据库中的对象(例如表或索引),包括创建(CREATE)、修改(ALTER)和删除(DROP)对象等操作。
-
TCL(Transaction Control Language,事务控制语言)。TCL 用于管理数据库中的事务,包括开始一个事务(START TRANSACTION)、提交事务(COMMIT)、撤销事务(ROLLBACK)和事务保存点(SAVEPOINT)等。
-
DCL(Data Control Language,数据控制语言)。DCL 用于控制数据的访问权限,包括授予权限(GRANT)和撤销权限(REVOKE)。
SQL 语句非常接近自然语言(英语),我们只需要掌握几个简单英文单词的作用,例如 SELECT、INSERT、UPDATE、DELETE 等,就可以完成绝大部分的数据库操作。例如,以下是一个简单的查询语句:
SELECT emp_id, emp_name, salary
FROM employee
WHERE salary >= 10000
ORDER BY emp_id;
即便对于没有学过 SQL 的初学者,我们只要知道几个英文单词的意思就不难理解该语句的作用。该语句查找员工表(employee)中月薪(salary)大于等于10000的员工,返回了员工的工号(emp_id)、姓名(emp_name)以及月薪(salary),并且按照工号进行排序显示。
可以看出,SQL语句非常简单直观,因为它在设计之初就考虑了非技术人员的使用需求。SQL是一种声明式的语言,我们只需要说明想要的结果(What),而不需要指定怎么做(How),具体的操作交由数据库管理系统完成。
超越关系
为了适应技术发展的需求,SQL 标准于 2016 年增加了以下 JSON 功能:
-
JSON 对象的存储与检索。
-
将 JSON 对象表示成 SQL 数据。
-
将 SQL 数据表示成 JSON 对象。
如今,主流关系型数据库都增加了原生 JSON 数据类型和相关函数的支持,使得我们可以将 SQL 的强大功能与 JSON 文档存储的灵活性相结合。当我们需要为应用程序增加文档存储功能时,可以考虑直接在现有的关系型数据库中使用 JSON 数据类型。

以下是一个使用 JSON 字段存储员工信息的示例:
-- Oracle 21c
CREATE TABLE employee_json(
emp_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
emp_info JSON NOT NULL
);
-- MySQL
CREATE TABLE employee_json(
emp_id INTEGER AUTO_INCREMENT PRIMARY KEY,
emp_info JSON NOT NULL
);
-- Microsoft SQL Server
CREATE TABLE employee_json(
emp_id INTEGER IDENTITY PRIMARY KEY,
emp_info VARCHAR(MAX) NOT NULL CHECK ( ISJSON(emp_info)>0 )
);
-- PostgreSQL
CREATE TABLE employee_json(
emp_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
emp_info JSONB NOT NULL
);
-- SQLite
CREATE TABLE employee_json(
emp_id INTEGER PRIMARY KEY,
emp_info TEXT NOT NULL CHECK ( JSON_VALID(emp_info)=1 )
);
我们可以使用 INSERT 语句将文本数据插入 JSON 字段:
INSERT INTO employee_json(emp_info)
VALUES ('{"emp_name": "刘备", "sex": "男", "dept_id": 1, "manager": null, "hire_date": "2000-01-01", "job_id": 1, "income": [{"salary":30000}, {"bonus": 10000}], "email": "liubei@shuguo.com"}');
其中,income节点是一个数组,包含了salary和bonus两个对象。
使用 SQL 语句查询 JSON 字段的方式与普通字段相同,SQL 标准使用 JSON_VALUE 函数查询 JSON 元素的值,使用 JSON_QUERY 函数查询元素中的对象和数组。 例如,以下语句从 emp_info 字段中获取员工的姓名和月薪:
-- Oracle和Microsoft SQL Server
SELECT emp_id,
JSON_VALUE(emp_info, '$.emp_name') emp_name,
JSON_VALUE(emp_info, '$.income[0].salary') salary,
JSON_VALUE(JSON_QUERY(emp_info, '$.income[0]'),'$.salary') salary
FROM employee_json
WHERE JSON_VALUE(emp_info, '$.emp_name') = '刘备';
emp_id|emp_name|salary|salary
------|--------|------|------
1|刘备 |30000 |30000
-- MySQL和SQLite
SELECT emp_id,
JSON_EXTRACT(emp_info, '$.emp_name') emp_name,
JSON_EXTRACT(emp_info, '$.income[0].salary') salary
FROM employee_json
WHERE JSON_EXTRACT(emp_info, '$.emp_name') = '刘备';
-- MySQL
emp_id|emp_name|salary
------|--------|------
1|"刘备" |30000
-- SQLite
emp_id|emp_name|salary
------|--------|------
1|刘备 | 30000
-- PostgreSQL
SELECT emp_id,
JSONB_EXTRACT_PATH_TEXT(emp_info, 'emp_name') emp_name,
JSONB_EXTRACT_PATH_TEXT(emp_info, 'income', '0', 'salary') salary
FROM employee_json
WHERE JSONB_EXTRACT_PATH_TEXT(emp_info, 'emp_name') = '刘备';
emp_id|emp_name|salary
------|--------|------
1|刘备 |30000
SQL 标准还定义了各种操作 JSON 数据的函数,具体可以参考特定数据库的实现。
2019 年 9 月 17 图形查询语言(GQL)成为了继 SQL 之后另一种新的 ISO 标准数据库查询语言。同时,最新的 SQL:2023 中增加的一个全新部分:Property Graph Queries (SQL/PGQ)。这个新功能支持使用图数据库的方式查询表中的数据。
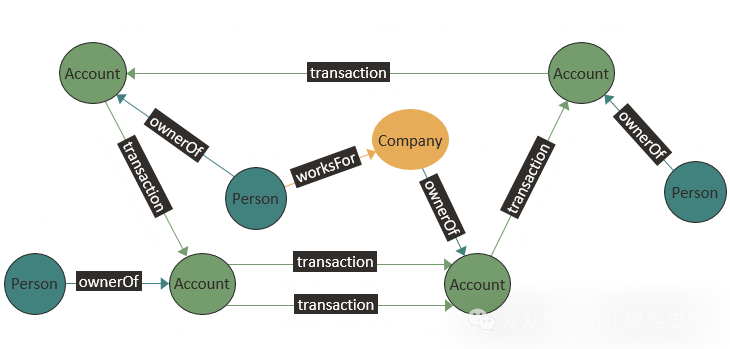
目前,MariaDB(OQGRAPH)、Oracle、Microsoft SQL Server、PostgreSQL(Apache AGE)等关系型数据库都提供了图结构存储支持。上图是 Oracle 中一个金融交易系统的图形数据库示例,其中 Account、Person 和 Company 是顶点,ownerOf、worksFor 和 transaction 是边;另外,name 和 number 是顶点的属性,amount 是边的属性。
基于这些表可以创建以下属性图形:
CREATE PROPERTY GRAPH financial_transactions
VERTEX TABLES (
Accounts LABEL Account,
Persons LABEL Person PROPERTIES ( name ),
Companies LABEL Company PROPERTIES ( name )
)
EDGE TABLES (
Transactions
SOURCE KEY ( from_account ) REFERENCES Accounts
DESTINATION KEY ( to_account ) REFERENCES Accounts
LABEL ( transaction ) PROPERTIES ( amount ),
PersonOwnerOfAccount
SOURCE Persons
DESTINATION Accounts
LABEL ownerOf NO PROPERTIES,
CompanyOwnerOfAccount
SOURCE Companies
DESTINATION Accounts
LABEL ownerOf NO PROPERTIES,
PersonWorksForCompany
SOURCE Persons
DESTINATION Companies
LABEL worksFor NO PROPERTIES
);
接下来我们就可以直接使用 SQL 语句查询图结构,例如以下语句查找所有和名叫 Nikita 的人有过交易的人员和信息:
SELECT owner.name AS account_holder, SUM(t.amount) AS total_transacted_with_Nikita
FROM MATCH (p:Person) -[:ownerOf]-> (account1:Account)
, MATCH (account1) -[t:transaction]- (account2) /* match both incoming and outgoing transactions */
, MATCH (account2:Account) <-[:ownerOf]- (owner:Person|Company)
WHERE p.name = 'Nikita'
GROUP BY owner
其中,MATCH 子句用于遍历图形结构并返回匹配的模式,语法和 Neo4j 的 Cypher 查询语言中的 MATCH 子句非常类似。以上查询返回的结果如下:
+----------------+------------------------------+
| account_holder | total_transacted_with_Nikita |
+----------------+------------------------------|
| Camille | 1000.00 |
| Oracle | 4501.00 |
+----------------+------------------------------+
随着 SQL/PGQ 的发布,我们可以存储属性图结构数据,并且在 SQL 中进行属性图模式匹配,例如最短路径查找和最佳路径查找;SQL/PGQ 的另一个优势就是可以支持分组(GROUP BY)、聚合(AVG、SUM、COUNT 等)、排序(ORDER BY)以及许多其他的 SQL 功能。

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









