









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种基于度量学习的小样本学习算法(TapNet),其特点是设计了一个与任务相关的分类空间,在该空间内进行距离度量,而且每个类别的参考向量
Φ
\Phi
Φ是通过学习更新得到的,而不是根据训练样本的特征向量计算得到的,这与PN和MN算法有明显的不同。整个算法的处理过程如下图所示。
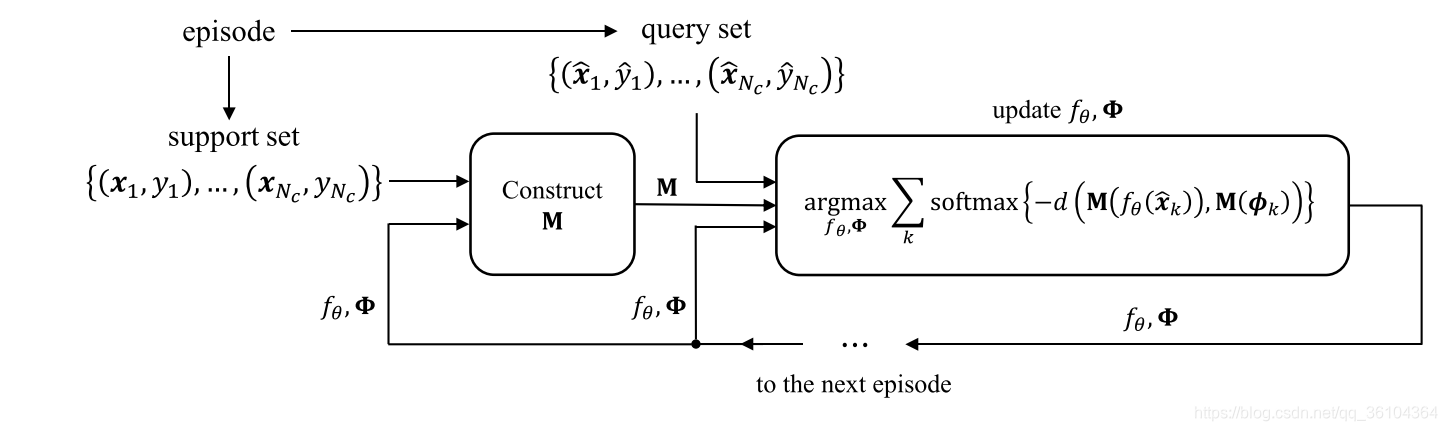
与所有的采用Episode训练方式的算法一样,训练集包含支持集
{
(
x
1
,
y
1
)
,
.
.
.
,
(
x
N
c
,
y
N
c
)
}
\left \{(x_1,y_1),...,(x_{N_c},y_{N_c})\right \}
{(x1,y1),...,(xNc,yNc)}和查询集
{
(
x
^
1
,
y
^
1
)
,
.
.
.
,
(
x
^
N
c
,
y
^
N
c
)
}
\left \{(\hat{x}_1,\hat{y}_1),...,(\hat{x}_{N_c},\hat{y}_{N_c})\right \}
{(x^1,y^1),...,(x^Nc,y^Nc)}两部分。整个网络分成三个部分:特征提取网络
f
θ
f_{\theta}
fθ,每个类别参考向量的集合
Φ
\Phi
Φ和映射矩阵
M
M
M,用于将特征向量映射到一个与任务相关的分类空间。其中
Φ
=
[
ϕ
1
;
.
.
.
;
ϕ
N
c
]
\Phi=[\phi_1;...;\phi_{N_c}]
Φ=[ϕ1;...;ϕNc]是一个由参考向量构成的矩阵,每一个行向量对应一个类别。输入图像经过特征提取网络得到特征向量
f
θ
(
x
^
k
)
f_{\theta}(\hat{x}_k)
fθ(x^k),该类别对应的参考向量为
ϕ
k
\phi_k
ϕk,与其他的度量学习算法直接计算
f
θ
(
x
^
k
)
f_{\theta}(\hat{x}_k)
fθ(x^k)与
ϕ
k
\phi_k
ϕk之间距离的方式不同,本文首先利用一个映射矩阵
M
M
M,将其投影到一个与任务相关的分类空间中,得到
M
(
f
θ
(
x
^
k
)
)
M(f_{\theta}(\hat{x}_k))
M(fθ(x^k))和
M
(
ϕ
k
)
M(\phi_k)
M(ϕk),再度量二者之间的欧氏距离,并利用softmax函数将其转化为分类概率,如下式:
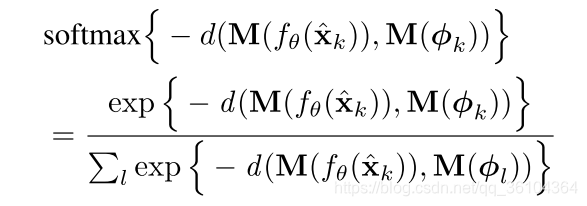
然后利用分类损失对特征提取网络
f
θ
f_{\theta}
fθ和参考向量的集合
Φ
\Phi
Φ进行更新,将更新后的
f
θ
f_{\theta}
fθ和
Φ
\Phi
Φ用于下一个Episode的训练中。测试时,训练得到的
f
θ
f_{\theta}
fθ和
Φ
\Phi
Φ是固定的,但映射矩阵
M
M
M会根据任务进行自适应调整,然后根据距离度量结果进行类别预测。
最后介绍一下映射矩阵
M
M
M是怎样构建的,该矩阵的目的是希望将特征向量
f
θ
(
x
^
k
)
f_{\theta}(\hat{x}_k)
fθ(x^k),和参考向量
ϕ
k
\phi_k
ϕk映射到一个分类空间中,而且在这个空间里特征向量
f
θ
(
x
^
k
)
f_{\theta}(\hat{x}_k)
fθ(x^k)与对应类别的参考向量
ϕ
k
\phi_k
ϕk之间的距离尽可能的小,而与其他类别的参考向量
ϕ
l
(
l
≠
k
)
\phi_l(l\neq k)
ϕl(l=k)之间的距离尽可能的大。作者利用一个简单的不需要训练的线性映射就解决了该问题,首先在考虑到其他类别参考向量的影响后,得到一个修正后的类别
k
k
k对应的参考向量
ϕ
~
k
\tilde{\phi}_{k}
ϕ~k,计算过程如下
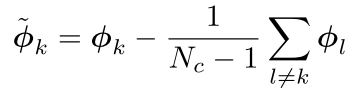
然后,用
c
k
c_k
ck表示类别
k
k
k的样本特征向量的平均值,就可以计算
ϕ
~
k
\tilde{\phi}_{k}
ϕ~k与
c
k
c_k
ck的偏差值
ε
k
\varepsilon_k
εk,计算过程如下
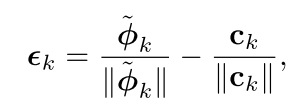
那么映射矩阵
M
M
M的目标就是让将映射后的偏差值为0,即
ε
k
M
=
0
\varepsilon_kM=0
εkM=0。换句话说
M
M
M就是偏差
ε
k
\varepsilon_k
εk的一个线性零解(linear nulling)
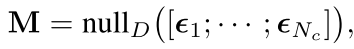
式中
D
D
D表示
M
M
M的列数,求解上述问题的一个方法就是计算
ε
k
\varepsilon_k
εk的奇异值分解:
ε
k
=
U
Σ
V
T
\varepsilon_k=U\Sigma V^T
εk=UΣVT式中
Σ
\Sigma
Σ是一个对角矩阵,且除了对角线上的前
N
c
N_c
Nc个值之外其他的值均为0,因此只要取右奇异值矩阵
V
T
V^T
VT的从第
N
c
+
1
N_c+1
Nc+1列到第
N
c
+
D
N_c+D
Nc+D列共
D
D
D个列向量,其构成的矩阵
M
M
M就是所求。并且只要偏差
ε
k
\varepsilon_k
εk的长度
L
≥
N
c
+
D
L\geq N_c+D
L≥Nc+D,映射矩阵
M
M
M就一定存在。
实现过程
网络结构
特征提取网络采用ResNet-12结构。
损失函数
损失是根据距离度量结果计算的,计算方法如下
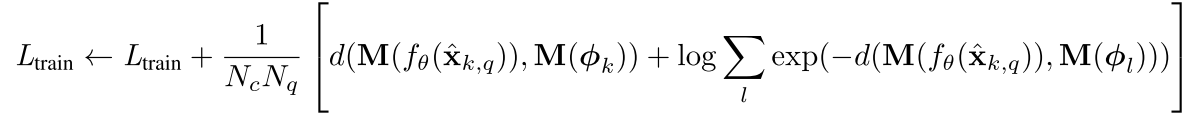
训练策略
整个网络的训练策略如下图所示

创新点
- 利用映射矩阵将特征向量和参考向量映射到一个与任务相关的分类空间中,其能够根据任务中包含的样本类别进行自适应的调整、
- 参考向量利用分类损失进行更新,而与输入样本无直接关系
算法评价
本文算是对度量学习的进一步探索吧,与PN,MN相比他的变化主要有两点,第一不是直接在特征空间中进行距离度量,而是设计了一个与任务相关的分类空间,三种算法的对比如下
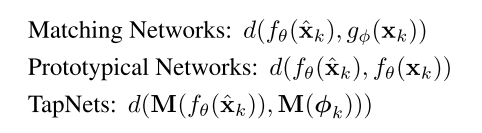
其次,每个类别对应的参考向量,并不是PN算法中通过求平均值的方法进行计算,而是由一个初始值通过逐步迭代更新的方式来计算,文中并没有介绍初始值选择的方式,可能是一个随机初始化的方式。此外作者也在文中提到,本文的方法其实与基于外部记忆的MANN算法有些相似,本文中映射矩阵
M
M
M其实就扮演了MANN中外部记忆矩阵
M
e
M_e
Me的角色。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











