









核心思想
该文提出一种将神经网络强化学习算法和视觉伺服相结合的方法,本质上还是一种选择模式的控制器,当满足一定条件时切换为视觉伺服控制器,不满足条件时就选择强化学习控制器。本文采用了两种强化学习算法Q-learning和 SARSA,并且将神经网络与强化学习相结合,具体的结合方式就是用一个神经网络取代了Q-learing中的Q-table查表的过程,将状态和动作作为输入,直接输出对应的Q值,并且利用误差损失来更新神经网络的权重参数。损失函数如下
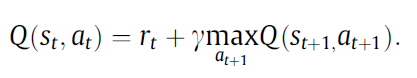
神经网络既需要计算Q值,又需要计算损失,因此需要一个数据集来帮助神经网络的训练,数据集是由当前样本和之前看到过的样本构成的,每个样本都包含当前的状态,动作,更新后的状态,及对应的回报等信息。每迭代一次就有一个新的样本被添加到数据集中,并且与之最相似的那个样本会被取代,这样就避免了数据集无限扩张的问题,相似性计算方法如下
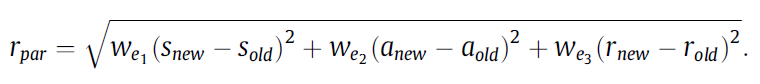
基于神经网络的Q-learning学习过程如下图所示,SARSA与之类似,只是Q值更新的方式不同

整个智能控制器的处理流程如下图所示
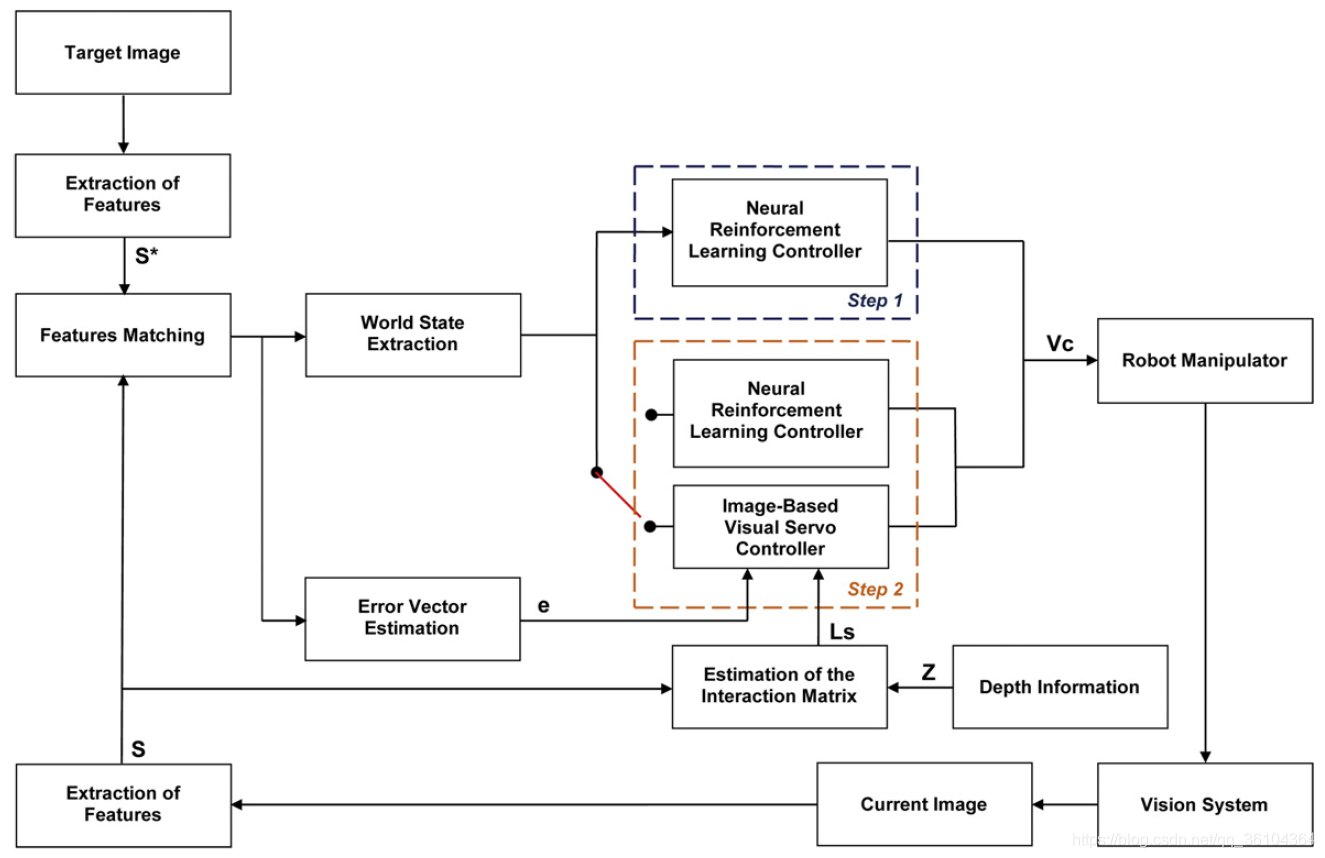
该文提出一种两步法的混合控制器,在第一步时,只使用基于神经网络的强化学习控制器;在第二步时,则根据条件选择使用基于神经网络的强化学习控制器或者基于图像的视觉伺服控制器。如何区分这两个步骤呢?作者将相机视野图像划分为以下区域
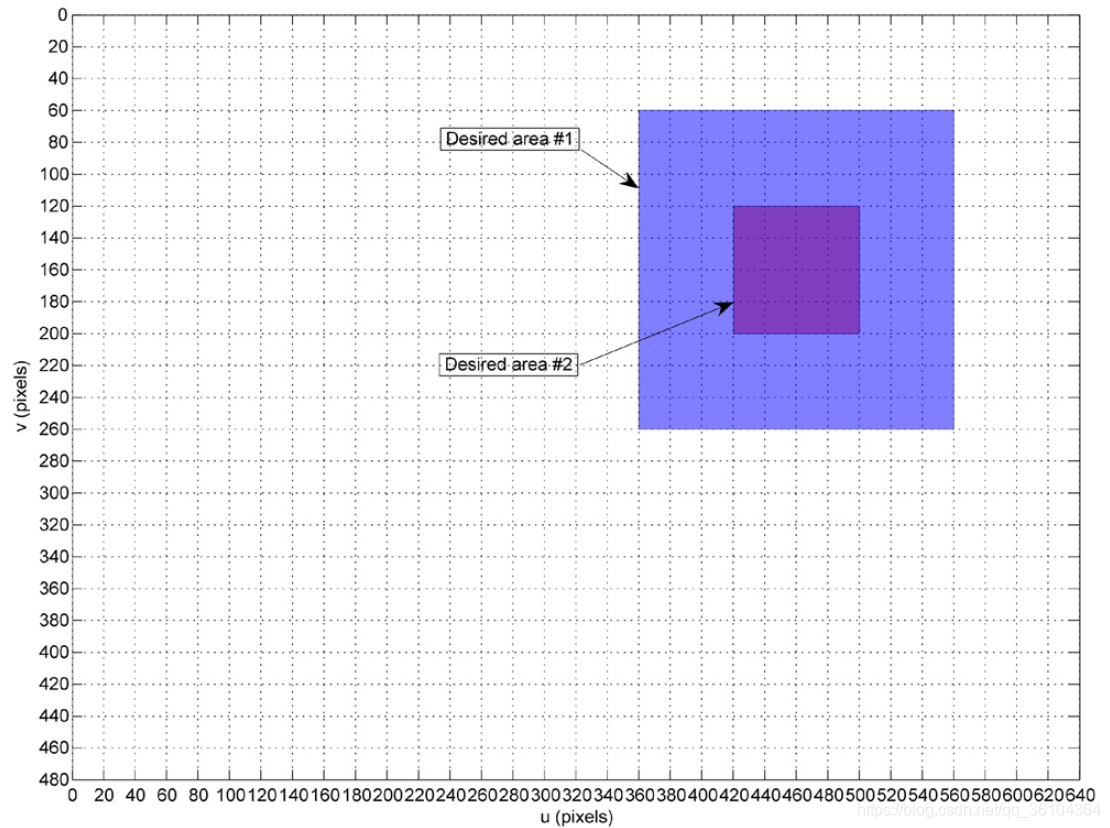
其中较大的蓝色矩形表示第一期望区域,较小的紫色矩形表示第二期望区域。如果目标特征点处于第一期望区域之外,也就是白色的位置,则处于第一步骤,使用强化学习控制器完成控制操作;如果目标特征点处于第一期望区域内,则根据是否在第二期望区域来选择控制器,如果在第二期望区域内采用视觉伺服控制器,否则采用强化学习控制器。
创新点
- 提出一种融合强化学习和视觉伺服的混合控制器
- 提出一种基于神经网络的强化学习算法,并定义了数据集和更新方法
算法评价
这篇文章我觉得并没有很大的突破,将神经网络和强化学习相结合不是他的原创思路,而这种两步法,根据特征点的位置来选择控制器的思路,其实和之前读的一篇文章《A Hybrid Visual Servo Controller for Robust Grasping by Wheeled Mobile Robots》也没有本质上的差别,还是把强化学习与视觉伺服进行了机械的组合,而不算是深度融合。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











