









 文章介绍基于深度学习的视觉伺服算法,从视觉伺服到直接视觉伺服,再到基于CNN的视觉伺服,通过最小化图像差异找最优位姿。利用神经网络学习完成优化,输入图像输出变换矩阵,用PBVS求速度控制律,确定了该算法范式,后续多在此基础改进。
文章介绍基于深度学习的视觉伺服算法,从视觉伺服到直接视觉伺服,再到基于CNN的视觉伺服,通过最小化图像差异找最优位姿。利用神经网络学习完成优化,输入图像输出变换矩阵,用PBVS求速度控制律,确定了该算法范式,后续多在此基础改进。
核心思想
该文应该是基于深度学习的视觉伺服算法中比较经典的一篇文章了,基本奠定了基于深度学习的视觉伺服算法的雏形。文章首先介绍了从视觉伺服(VS)到直接视觉伺服(DVS)的变化过程,其实就是将视觉伺服从一个利用几何关系和动力学关系求解控制律的过程,过渡到一个优化问题,通过最小化期望位置图像和当前位置图像之间的差异,来寻找最优的期望位姿。
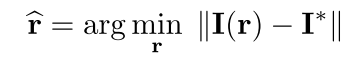
而进一步发展到基于深度学习(CNN)的视觉伺服,就是利用一个神经网络,通过学习的方式来完成上述的优化过程,网络的输入是当前位置的图像和参考位置图像,输出则是两幅图像位姿之间的变换矩阵
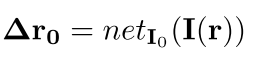
Δ
r
0
\Delta r_0
Δr0就表示变换矩阵
c
0
T
c
^{c_0}T_c
c0Tc
对于视觉伺服任务而言,要求得当前位置到期望位置的变换矩阵
Δ
∗
r
\Delta ^*r
Δ∗r也非常简单
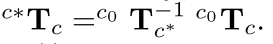
这里不理解为什么非要用一个参考图像过渡一下,直接计算期望位置图像和当前位置图像之间的变换矩阵不好吗?网络的目标函数也很简单
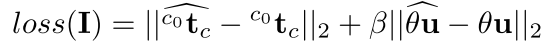
在求得变换矩阵之后利用经典的PBVS算法就可求得速度控制律了,且这个过程是全局渐近稳定的,即无论是怎样的初始位姿和期望位姿,整个系统都会收敛。
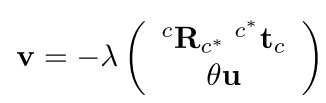
文中还介绍了网络的训练和数据集生成的过程,这里不再赘述了。
算法评价
这篇文章最重要的贡献在于确定了一种基于深度学习的视觉伺服范式,输入当前位置图像和期望位置图像,输出两个图像之间的位姿变换矩阵,利用PBVS求解控制律。后面很多文章基本都是在其基础上进行改进,但并没有跳出这个框架。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。


















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











