









核心思想
本文提出一种基于运动一致性(Montion Coherence)的特征匹配方法(CODE),从全局的层面来看,正确匹配点更倾向于拥有一致的运动,而错误匹配点通常随机的散落在不同位置。本文提出一种非线性回归技术,从包含噪声的匹配点中获得运动一致性的估计函数。然后用该函数输出匹配点的一致性得分,并将其作为正确匹配的概率值。最后,将一致性得分超过一定阈值的点判断为正确匹配点。
现有的特征匹配方法,通常利用Ratio Test方法筛选掉误匹配点,但这种方法有两个问题:如果选择较高的阈值,会导致很多正确匹配点也被筛除了;而如果降低阈值标准,误匹配点数量会快速增加。作者认为正确匹配点在两幅图像之间的运动具备一致性,也就是相邻的点的运动情况是一致的,而误匹配点的运动情况是随机变动的。所以运动的一致性可以作为判断正确/错误匹配点的一个指标,下面的问题就是如何利用匹配点的位置坐标以及坐标变化等信息来计算运动一致性。作者提出一种基于运动一致性的非线性回归方法,用于获得运动一致性得分计算函数
f
(
p
)
:
p
→
q
f(\mathbf{p}):\mathbf{p}\rightarrow q
f(p):p→q。该函数是
K
K
K个平滑函数的线性集合
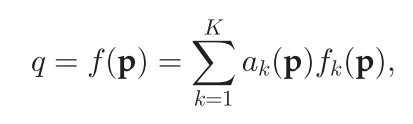
其中
p
\mathbf{p}
p是位置与运动描述向量,
q
q
q可以表示一致性得分,
a
k
a_k
ak表示第
k
k
k个函数的权重。实际的观测值通常包含一定的噪声,则上式可写为
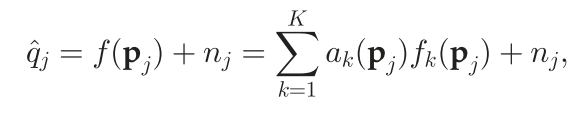
其中
n
j
n_j
nj表示噪声。每一个平滑函数
f
k
f_k
fk都由两项构成
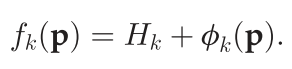
其中
H
k
H_k
Hk是一个未知的标量偏移,
ϕ
k
\phi_k
ϕk是使用运动一致性作为平滑惩罚项评估的平滑函数,该平滑惩罚项如下
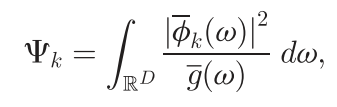
ϕ
ˉ
k
\bar{\phi}_k
ϕˉk表示
ϕ
k
\phi_k
ϕk的傅里叶变换,
g
ˉ
\bar{g}
gˉ表示高斯函数的傅里叶变换,上式通过惩罚高频项来实现平滑。
当前的目标是希望根据已知的数据点集合
{
p
,
q
^
}
\{\mathbf{p},\hat{q}\}
{p,q^},来获得最平滑的函数
f
k
f_k
fk,按照能量最小化原则,上述目标可表述为下式
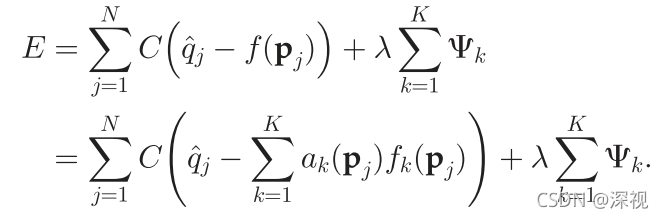
其中
C
(
⋅
)
C(\cdot)
C(⋅)表示Huber函数
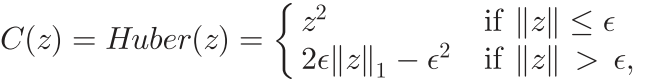
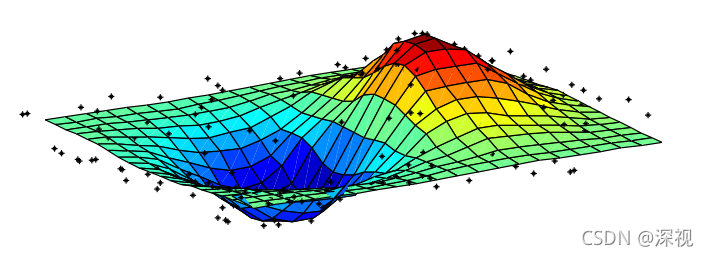
上述的能量函数也很好理解,第一项就是希望回归得到的函数输出的估计值和真实观察值尽可能接近,这是回归过程的核心诉求;第二项则是前面介绍的平滑项,希望函数尽可能平滑。这里的平滑也就反映出位置特征接近的点其运动情况也相对一致,而不平滑的点则是由于误匹配点的随机运动导致的,通过增加平滑惩罚项就是为了减少误匹配点对于回归过程的影响。下图描述了回归计算得到的二维曲面和数据点之间的关系。
为了计算能使能量函数达到最小值的函数
f
k
f_k
fk,对能量函数求导,并令导数为零
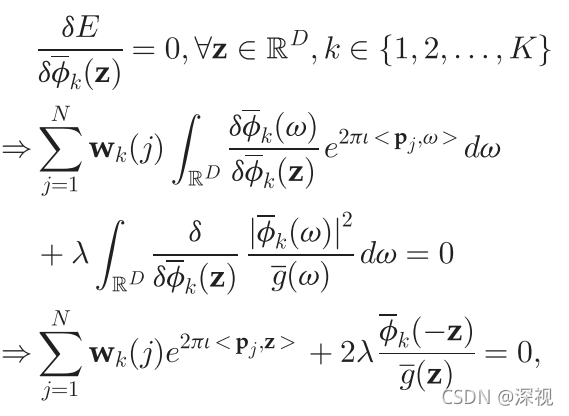
其中
w
k
\mathbf{w}_k
wk表示一个
N
×
1
N\times1
N×1维的向量,
N
N
N表示用于函数回归的数据点的个数。整理上式可得
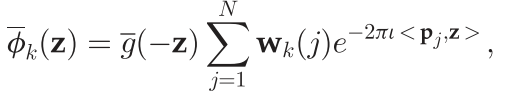
对其进行傅里叶反变换可得
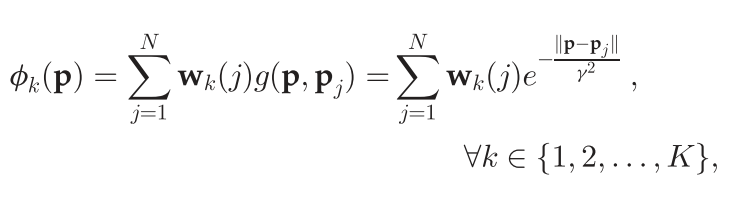
其中
g
(
p
,
p
j
)
g(\mathbf{p},\mathbf{p}_j)
g(p,pj)表示高斯径向基函数,
w
k
\mathbf{w}_k
wk则是一个未知变量。将上式代入到惩罚项函数中,可得
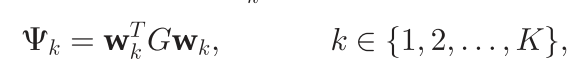
其中
G
G
G是一个对称矩阵,其元素为
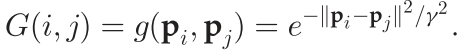
则将
ϕ
k
\phi_k
ϕk和
Ψ
k
\Psi_k
Ψk带回到能量函数中可得
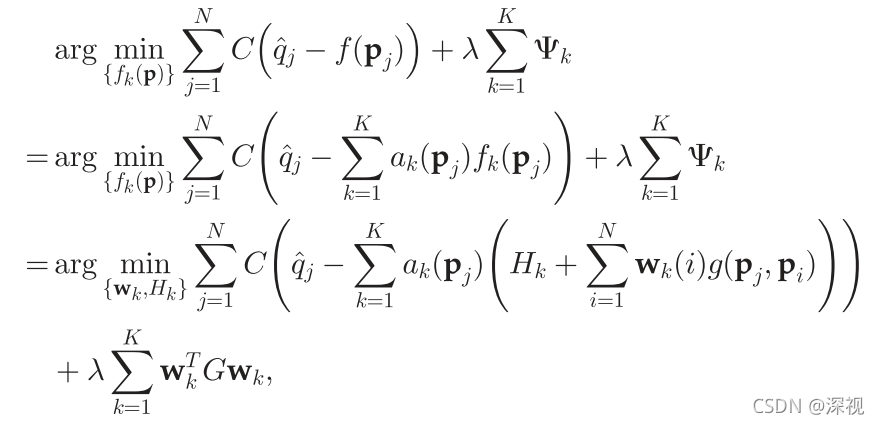
通过求解上式就能够得到使得能量函数达到最小值的函数
f
k
f_k
fk,其可以用
w
k
\mathbf{w}_k
wk和
H
k
H_k
Hk两个参数来描述。因为上式是一个凸函数,因此利用梯度下降法可以寻找到全局最小值。根据计算得到的
w
k
\mathbf{w}_k
wk和
H
k
H_k
Hk两个参数,回归函数
f
(
p
)
f(\mathbf{p})
f(p)可表示为
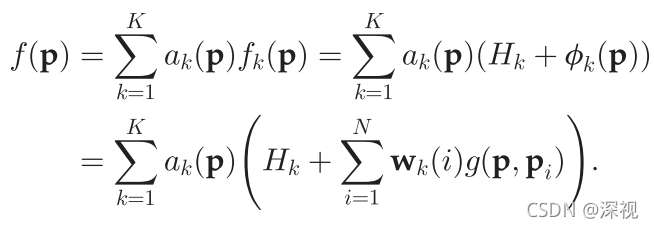
值得注意的是,参数
w
k
\mathbf{w}_k
wk的维度与用于回归计算的数据点的数量
N
N
N一致,因此当数据点较多是计算量较大。为解决这个问题,作者提出一种近似计算方法,简单来说就是用K-means聚类方法,将
N
N
N个数据点压缩至
M
M
M个聚类中心点,然后再进行上述计算过程。
下面作者将上述基于运动一致性的回归方法用于图像特征匹配中,首先使用A-SIFT+FLANN等方法获得大量匹配点,并用Ratio Test方法筛除部分误匹配点,这里的阈值标准设定较低(
τ
=
0.86
\tau=0.86
τ=0.86),目的是尽可能的保留更多的正确匹配点。然后使用候选匹配点回归得到一个运动一致性回归模型,并用该模型计算所有匹配点(
τ
=
1.0
\tau=1.0
τ=1.0)的运动一致性得分,将得分低于设定阈值的点视作误匹配点筛除掉。具体而言,作者计算了两个回归模型,并将二者级联起来得到较好的匹配结果。过程如下图所示
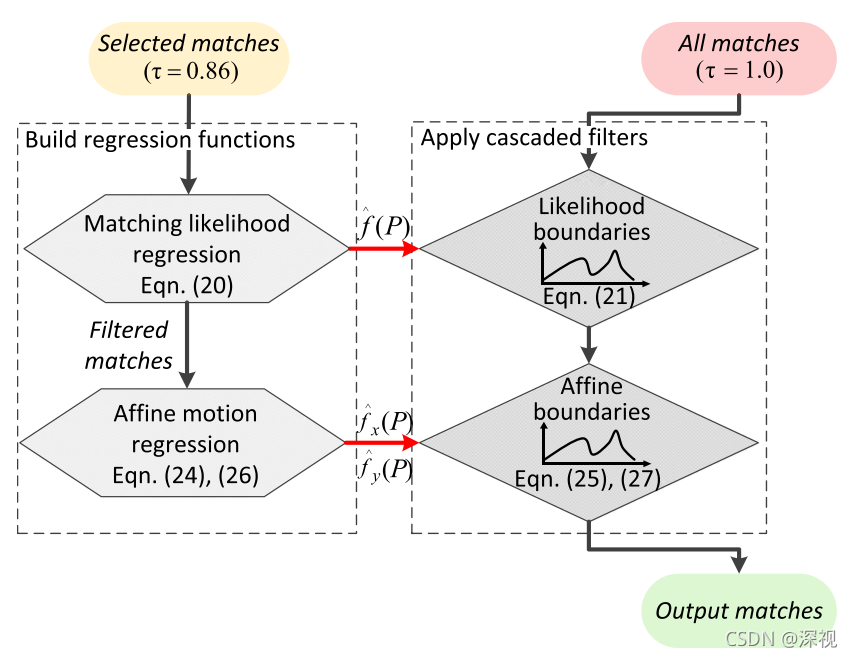
第一个回归模型叫做“匹配可能性边界”(Matching Likelihood Boundaries),其数据点定义如下
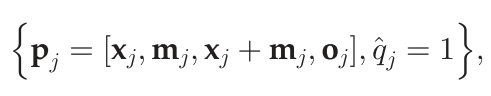
其中在位置
p
j
\mathbf{p}_j
pj处每个索引值为
j
j
j的匹配点其对应的
q
^
j
\hat{q}_j
q^j值假定为1,
x
j
\mathbf{x}_j
xj表示点的图像坐标,
m
j
\mathbf{m}_j
mj表示运动向量,
o
j
\mathbf{o}_j
oj表示仿射变换方向向量,使用这几个向量来作为位置描述向量的原因有三点:1.能够保留不连续的平面(Discontinuity Preservation),对于图像中不连续的两个平面(如相邻的两个物体)其位置坐标可能非常接近,但其运动情况可能差别很大(如一个物体运动而另一个物体静止),因此也可能不具备运动一致性。作者将运动向量引入,就避免了仅仅依赖位置坐标而导致错误估计的问题。2.仿射平滑性(Affine Smoothness),作者将仿射变换向量引入是为了更好的处理旋转运动。3.对称性(Symmetry),作者引入
x
j
+
m
j
\mathbf{x}_j+\mathbf{m}_j
xj+mj是为了保证左右图像之间的数学对称性。
在该模型中设置
K
=
1
K=1
K=1,
H
k
=
0
H_k=0
Hk=0,
a
k
=
1
a_k=1
ak=1,则按照前面叙述的回归过程,可得到匹配可能性函数
f
~
(
p
)
\widetilde{f}(\mathbf{p})
f
(p)
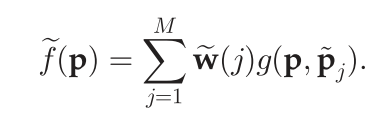
其中
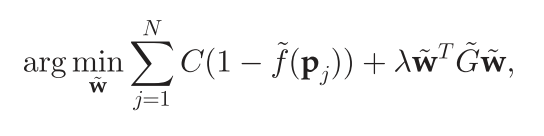
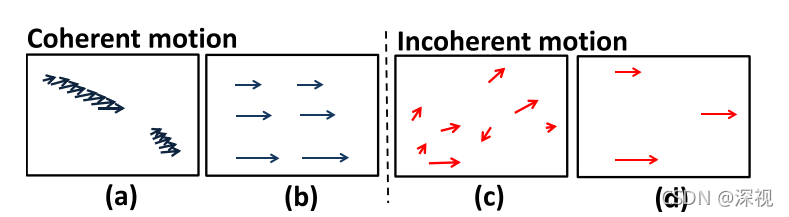
当存在一簇临近的匹配点时,其对应的匹配可能性会接近于1,另外当一个很大范围内的多个点都有相同的运动时,其对应的匹配可能性也会接近于1,如下图(a)、(b)所示
因此,将设定一个匹配可能性阈值
ϵ
\epsilon
ϵ,将匹配可能性大于阈值的点保留下来
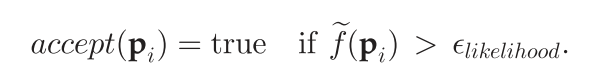
第二个模型叫做“双边变化仿射运动边界”(Bilaterally Varying Affine Motion Boundaries),其对X和Y两个方向分别建模,该模型的思想是处于这样一个判断,正确的运动不仅聚类,而且倾向于近似分段平滑变化仿射模型。对于X方向而言,其数据点的定义如下
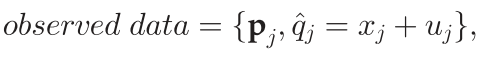
数据点的输入
p
\mathbf{p}
p与第一个模型的定义相同,
K
=
3
K=3
K=3,
a
1
(
p
)
=
x
a_1(\mathbf{p})=x
a1(p)=x,
a
2
(
p
)
=
y
a_2(\mathbf{p})=y
a2(p)=y,
a
3
(
p
)
=
1
a_3(\mathbf{p})=1
a3(p)=1,则得到可能性函数
f
~
x
(
p
)
\widetilde{f}_x(\mathbf{p})
f
x(p)
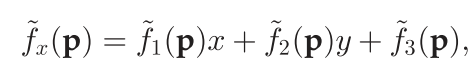
其中
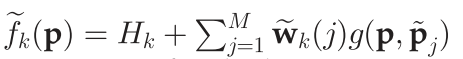
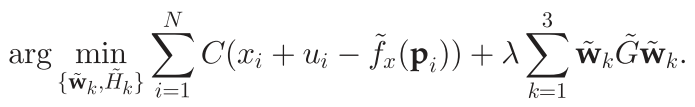
对于Y方向其过程是类似的不再赘述。最后同样是设定阈值,并保留空间差异大于阈值的点
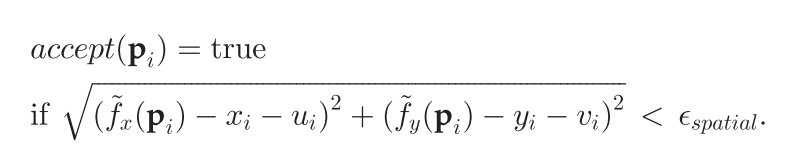
如上文所说,第一个模型的匹配精确性不如第二个模型,而第二个模型的鲁棒性不如第一个模型,因此全部的候选匹配点依次经过两个模型的过滤,得到最终的匹配点。
创新点
- 提出一种基于运动一致性的非线性回归模型
- 根据运动一致性回归模型设置了匹配可能性边界和双边变化仿射运动边界,以此来滤除错误匹配点
算法评价
该方法的基本假设是建立在正确匹配点的运动一致性上,根据这一假设设计了回归模型用于计算匹配点之间的运动一致性,并设计了上下两个边界,实现误匹配的滤除的基础上,更多的保留了正确匹配点。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











