







arXiv Paper CXL论文阅读笔记整理
问题
在探索利用CXL的可组合内存系统时,需要克服超大规模下的障碍。超大规模采用基于软件的内存(解)压缩技术,减轻了内存容量、存储和网络限制,但需要更多的计算CPU周期。作为CXL社区的关键指南,制定了开创性的开放计算项目(OCP)超大规模CXL分层内存扩展器规范。如果实施,此规范将降低TCO障碍,从而在超大规模和企业级别实现多样化的CXL部署。
OCP规范呼吁采用一种可持续、透明和成本效益高的方法,在各种计算平台上使用多种内存技术压缩CXL Type 3设备上的内存。OCP规范要求在250ns内访问压缩块中的缓存线,访问压缩块的缓存线的尾延迟<1us,包括最坏情况下的查找延迟、解压缩、电源状态转换。此外,46GB/s的解压缩速度必须与4通道1867MT/s的压缩数据相匹配,具有4kB/1kB的块。但现有的解决方案无法满足这些要求。
本文方法
本文提出了一个CXL集成解决方案,与OCP规范保持一致,引入了一种节能、可扩展、硬件加速、无损压缩内存CXL层。通过在缓存线粒度上实现专有的(解)压缩算法,以及开源LZ4算法的双硬件加速器实现,在纳秒内提供2-3倍的CXL内存压缩,为最终客户提供20-25%的TCO降低,而不需要额外的物理插槽。
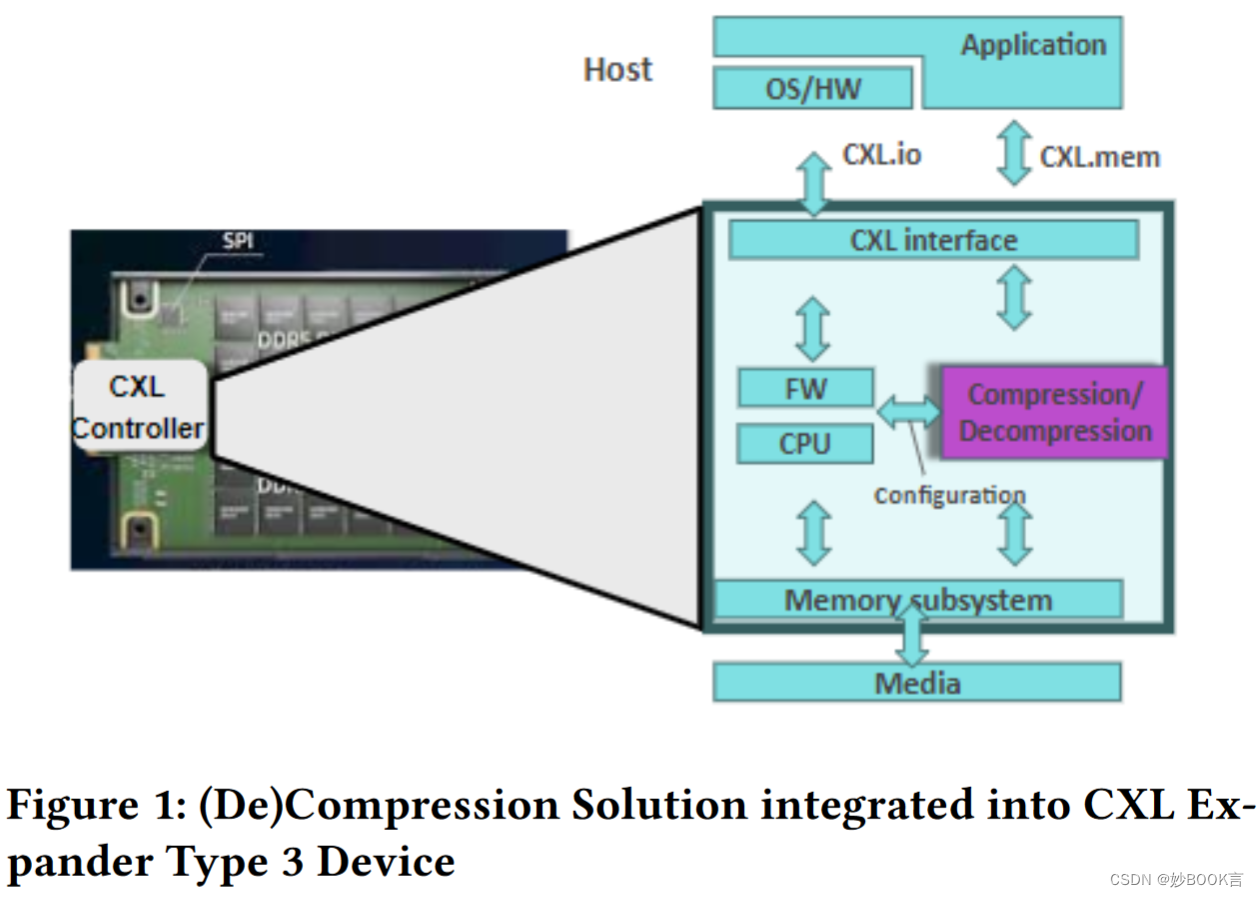
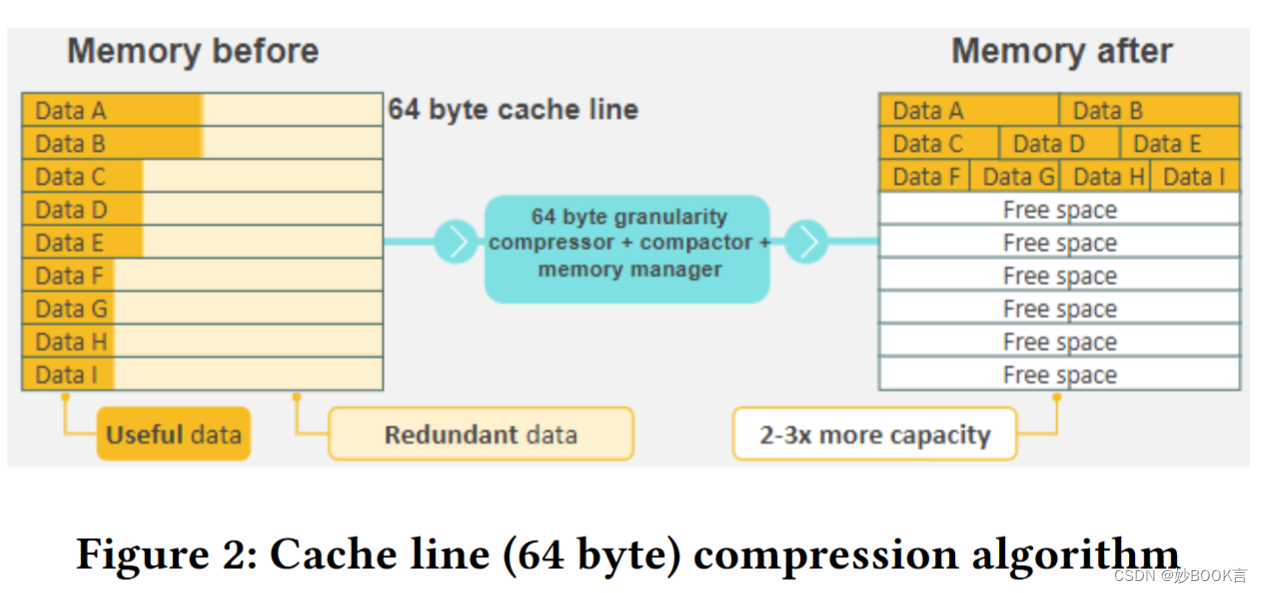
在本文的讨论中,确定了CXL社区内的协作创新领域,以加快CXL分层内存扩展的软件/硬件进步。此外,深入研究了Pooled部署中尚未解决的挑战,并探索了潜在的解决方案,共同致力于使CXL应用于超大规模。
总结
本文针对将CXL应用于超大规模的需求,介绍了一种CXL集成解决方案,与现有OCP超大规模CXL分层内存扩展器规范相符。引入了一种节能、可扩展、硬件加速、无损压缩内存CXL层。通过在缓存线粒度上实现专有的(解)压缩算法,以及开源LZ4算法的双硬件加速器实现,在纳秒内提供2-3倍的CXL内存压缩,为最终客户提供20-25%的TCO降低,同时不需要额外的物理插槽。
















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











