







背景
数据量的增长和对高性能数据处理的需求推动存储体系结构的创新。传统方法受限于集中处理和频繁数据移动,面临性能限制和高成本[9,10,44]。为此,供应商提出了近存储数据处理设备,使处理能力更接近存储[11,15,28],利用加速器和主机处理器来增强处理能力,并减少数据移动和相关开销。
在近存储加速器上使用内存缓冲区对于减轻延迟和带宽的影响至关重要。近存储存储器提供了局部性和高带宽等优势,但近存储的内存容量通常小于主机 RAM。因此,需要协同使用设备和主机的内存和处理器,最大限度地减少存储层和主机层之间的数据移动,从而加快数据处理和常规 I/O 操作(如读、写)。
挑战
目前的近存储设计已经探索了各种加速 I/O 和数据处理的方法,包括:使用存储作为原始块设备[33],近存储键值存储[13,17,24,34],近存储文件系统[9,21,31],应用程序定制技术[37,39]。
虽然近存储设计提高了I/O或数据处理性能,但仍面临一些挑战:
-
缺乏内存缓存支持[9,31,33],导致无法利用近存储内存进行I/O和数据处理,增加主机和设备之间的存储访问和数据移动。例如:DiskANN 和RocksDB 有95%请求是未对齐的,产生写放大。
-
无法利用设备级内存与主机级内存协作进行缓存[17,24,44],导致应用程序因缓存驱逐延迟而暂停。
-
先前的设计使用简单化的指标来卸载数据处理(例如,计算能力),而不考虑以存储为中心的指标(例如,数据分布、I/O 与处理的比率、数据移动带宽和排队成本),导致次优性能。
本文方法
本文提出了 OmniCache,用于近存储加速器的新型缓存设计,结合近存储加速器、主机 CPU、各自的内存,来加速 I/O 和数据处理。
-
近缓存 I/O:同时利用主机缓存(HostCache)和设备缓存(DevCache)优化 I/O 性能,提高了各种 I/O 访问模式的缓存利用率,只将应用程序请求的数据大小而不是整个块从存储器传输到主机。
-
用于并发 I/O 的协作缓存:在分层缓存方法中,DevCache 是 HostCache 的子集,HostCache 满时线程必须等待缓存驱逐。OmniCache 采用水平缓存,两个cache不完全重叠,允许线程更新 DevCache,减少应用程序停滞。为了定位存储在缓存或磁盘上的数据,引入了 OmniIndex,可扩展、主机管理的索引机制,利用配备了细粒度范围锁的每个文件间隔树,使线程能够同时访问主机和设备缓存中的非冲突块[7]。
-
动态卸载的协同处理:提出了由卸载模型驱动的动态卸载机制,监控硬件和软件指标,协同利用 HostCache 和 DevCache 来加速数据处理,实现了主机和设备之间的并发数据处理,并使用缓存缓冲中间处理状态。
-
利用 CXL.mem 功能:利用具有 CXL.mem 的 CXL 来协调主机和设备缓存,降低数据移动成本和排队延迟。
开源代码:GitHub - rimimadision/omnicache-fast24-artifacts
实验结果表明,OmniCache 使 I/O 工作负载的性能提升高达3.24倍,数据处理工作负载的性能提升高达3.06倍。
架构概览
架构:
-
Omnilib 支持 posix API,提供预定义的 I/O 和数据处理函数
-
OmniIndex,cache 索引,提供跨主机和设备的统一 cache 视图,运行在主机上,提供了细粒度的并发控制
-
OminiDynamic,支持动态卸载请求到主机和设备。动态获取主机和设备的数据:要执行数据在 cache 上的比率、平均执行时间、传输带宽、排队延迟,根据信息计算理论上主机和设备的执行时间,将请求卸载到执行时间少的部分执行。
-
近存储设备上的文件系统,可以处理 I/O 和数据处理请求,还可以管理文件数据和元数据
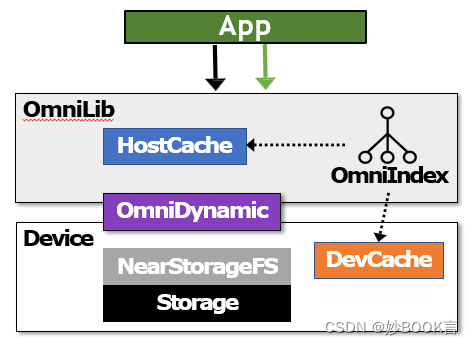
执行流程:
-
请求通过 OmniLib 查找 OmniIndex,定位要使用的数据在 HostCache(蓝色) 还是 DevCache(绿色)。
-
若在 HostCache,则在 HostCache 中查找,随后由 OmniDynamic 决定在 Host、Dev 或协同执行。
-
若在 DevCache,则将数据请求发送到 Dev,在 DevCache 中更新,随后由 OmniDynamic 决定在 Host、Dev 或协同执行。

实验
实验环境:双插槽64核至强可扩展CPU @ 2.6GHz,512GB Intel Optane DC NVM模拟近存储的文件系统。模拟方法:使用一个专用设备线程来处理I/O请求、增加所有I/O操作的PCIe延迟、降低设备CPU(和内存带宽)的CPU频率。
数据集:Microbenchmark,YCSB,KNN
实验对比:吞吐量,延迟
实验参数:线程数、顺序/随机的读/写,I/O大小,缓存大小,
总结
针对协同使用主机和近存储加速器的系统,如何协同利用主机和设备的cache和计算能力,提升整体I/O和数据处理性能。本文提出 OmniCache,结合近存储加速器、主机 CPU、各自的内存,来加速 I/O 和数据处理。包括三个创新点:(1)近缓存 I/O:水平缓存设计,同时利用主机缓存和设备缓存,提高 I/O 的缓存利用率,降低读写放大。(2)用于并发 I/O 的协作缓存:允许应用单独使用主机缓存或设备缓存,减少缓存驱逐导致的停滞。为了定位数据位置,引入了 OmniIndex,主机管理的索引机制,使用细粒度范围锁的每个文件间隔树,使线程能够同时访问主机和设备缓存中的非冲突块。(3)动态卸载的协同处理:通过监控硬件和软件指标,计算主机和设备上的执行时间,将请求卸载到执行时间少的部分执行,使用缓存缓冲中间处理状态。
















 3993
3993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











