









Towards Generative Aspect-Based Sentiment Analysis

摘要
【ACL2021】基于方面的情感分析(ABSA)最近受到越来越多的关注。 大多数现有工作以区分方式处理 ABSA,为预测设计各种特定于任务的分类网络。 尽管它们很有效,但这些方法忽略了 ABSA 问题中丰富的标签语义,并且需要广泛的特定于任务的设计。 在本文中,我们建议在统一的生成框架中处理各种 ABSA 任务。 两种类型的范式,即注释式和提取式建模,旨在通过将每个 ABSA 任务制定为文本生成问题来实现训练过程。 我们在多个基准数据集上对四个 ABSA 任务进行了实验,我们提出的生成方法几乎在所有情况下都取得了最新的最新结果。 这也验证了所提出框架的强大通用性,该框架可以轻松适应任意 ABSA 任务,而无需额外的特定于任务的模型设计。
针对问题:
现有的研究忽略了标签的语义,比如知道“食物质量”和“餐厅氛围”的含义,就更容易识别出前者更有可能是有关方面“披萨”的正确类别。标签的这种语义对于多个情感元素的联合抽取更有帮助,因为这些情感元素之间的交互比较复杂。
另一个问题是,现有研究都针对不同的ABSA问题提出了不同的分类模型,使得模型难以相互适应。
解决思路:
受语言理解问题的启发,如命名实体识别,问题回答,文本分类等作为生成任务,在本文中,我们建议用统一的生成方法来解决各种ABSA问题。过将自然语言标签编码到目标输出中,可以充分利用丰富的标签语义。此外,这个统一的生成模型可以无缝地适应多个任务,而无需引入额外的特定任务模型设计。
为了实现基于生成方面的情感分析(Generative Aspect-based emotion analysis, GAS),我们定制了标注风格和抽取风格两种建模范式,将原始任务转换为生成问题。
给定一个句子,标注风格在句子上添加注释,在构建目标句子时包含标签信息;而抽取风格直接采用输入句子所期望的自然语言标签作为目标。
2 Generative ABSA (GAS)
Aspect Opinion Pair Extraction (AOPE)

在注解式范式中,为了表示方面和意见术语之间的成对关系,我们以[方面|意见]的形式在每个方面术语上附加相关的意见修饰语来构建目标句子。对于抽取式范式,我们以期望的情感对为目标,类似于直接抽取期望的情感元素,但采用生成的方式。
Unified ABSA (UABSA)
任务是提取方面术语,同时预测它们的情感极性。致力于抽取两对儿: (Salads, positive) and (server, positive). 类似地,我们将每个方面术语替换为注释风格公式下的[方面|情感极性],并将所需的对作为抽取风格范例中的目标输出,将UABSA任务重新表述为文本生成问题。
Aspect Sentiment Triplet Extraction (ASTE)
旨在发现更复杂的(aspect, opin-
ion, sentiment polarity)三联体

如图,我们用括号中包裹的情感三联体来注释每个方面术语,[方面|意见|情感极性]用于注释式建模。对于提取样式的范例,我们只是将所有三元组连接起来作为目标输出。
Target Aspect Sentiment Detection (TASD)
任务是检测(aspect term, aspect category,sentiment polarity) triplets对于给定的句子,aspect category是预定义的。

同样,我们将每个方面术语、它所属的方面类别和它的情感极性打包到括号中,以构建标注式方法的目标句子。
【注意】如示例中所示,一些三元组可能没有明确提到方面术语,因此我们使用“null”来表示它,并将这样的三元组放在目标输出的末尾。
对于抽取式范式,我们将所有期望的三联句(包括带有隐式方面术语的三联句)连接起来,作为序列到序列学习的目标句。
2.2Generation Model
给定输入句子x,我们生成一个目标序列y’,我们从y‘里解码情感对儿或情感三元组。具体来说,对于annotation-style的建模,我们从y‘中提取括号“[]”中包含的内容,用竖条“|”分离不同的情感元素。
我们采用预训练的T5模型(Raffel et al.,2020)作为生成模型,通过将这些ABSA任务表述为文本生成问题,我们可以在一个统一的顺序到顺序框架中处理它们,而无需特定任务的模型设计
2.3 Prediction Normalization
我们提出了一种预测规范化策略,以改进由此导致的错误预测。对于每个表示元素e类型的情感类型c,如方面项或情感极性,我们首先构造其对应的词汇集Vc。对于方面术语和意见术语,vc包含当前输入句子x中的所有单词;对于方面类别,Vc是数据集中所有类别的集合;对于情感极性,vc包含所有可能的极性。然后,对于情感类型c的一个预测元素e,如果它不属于对应的词汇集Vc,则使用与e有最小Levenshtein距离(Levenshtein, 1966)的¯e∈Vc来替换e
3实验
我们在四个流行的基准数据集(包括Laptop14、Rest14、Rest15和Rest16)上评估了提出的GAS框架
实验详情:我们采用T5基础模型,T5紧跟Transformer模型原有的编解码器架构,略有不同,如不同的位置嵌入方案。
我们以16批大小训练模型,并每两批累积梯度。学习率设置为3e-4。模型在AOPE、UABSA和ASTE任务中训练了20个周期,在TASD任务中训练了30个周期。
实验结果:
对于我们所提议的GAS框架,我们也展示了未使用所提议的预测规范化策略(后缀为“-R”)的原始结果。
我们提出的方法,基于注释风格或抽取风格的建模,在几乎所有情况下都建立了新的最先进的结果。
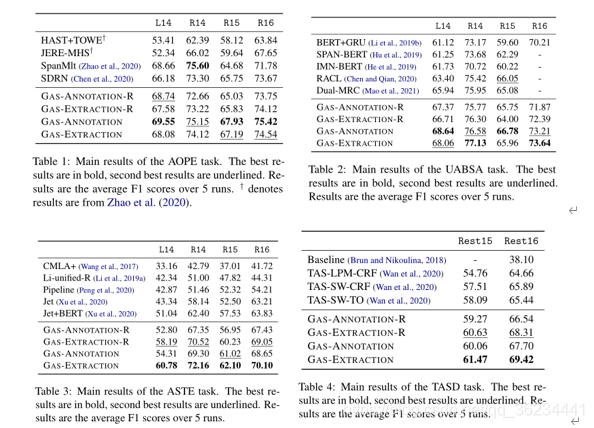
我们可以看到,我们的方法在ASTE和TASD任务上表现特别好,所提出的提取风格的方法在这两个任务上分别比之前最好的模型高出7.6和3.7个平均F1分数(跨不同数据集)。这意味着整合标签语义并适当建模情感元素之间的交互对于解决复杂的ABSA问题至关重要。
3.3讨论
Annotation-style & Extraction-style
如结果表所示,在AOPE和UASA任务上,注释风格的方法通常比提取风格的方法执行得更好。但是,在更复杂的ASTE和TASD任务上,前者的性能不如后者。一个可能的原因是,在ASTE和TASD任务中,注释式的方法在目标句子中引入了过多的内容,如方面类别和情感极性等,增加了序列到序列学习的难度。
Why Prediction Normalization Works
为了更好地理解所提出的预测归一化策略的有效性,我们从ASTE任务中随机抽取一些具有不同的原始预测和标准化预测(即通过我们的策略修正)的实例。
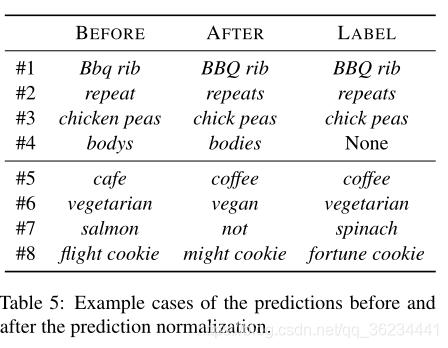
我们发现规范化主要在两种情况下起作用:第一种是词形变化,即两个词有微小的词汇差异。例如fixes “Bbq rib” to “BBQ rib” (#1) and “repeat” to “repeats” (#2)
另一种情况是正字法替代,模型可能生成词源相同但单词类型不同的单词,例如它输出“vegetarian”而不是“vegan”(#6)
当然了,如果原始预测在词汇上或语义上与黄金标准标签有很大的不同,我们的预测策略可能会失败。可能的解释是:困难并不来自于执行预测规范化的方式,而是来自于接近事实的标签的生成,特别是对于包含隐含方面或观点的例子。
我们提出的预测标准化,即通过Levenshtein距离从对应的词汇集中找到替换项,是一种简单而有效的缓解这一问题的策略。
结论:
在本文中,我们在一个新的生成框架中处理各种ABSA任务。通过使用我们提出的注释风格和抽取风格的范式构建目标句子,我们用统一的生成模型解决多个情感对或三重句抽取任务。在四个ABSA任务的多个基准上进行的大量实验表明了我们提出的方法的有效性。
本文贡献:
我们的主要贡献是:1)我们以一种新颖的生成方式处理各种ABSA任务;2)我们提出了两种范式,将每个任务定义为生成问题和优化生成输出的预测规范化策略;3)我们在四个ABSA任务的多个基准数据集上进行了实验,我们的方法在几乎所有情况下都超越了以前的最先进的技术。具体来说,我们在挑战性的ASTE和TASD任务上分别获得7.6和3.7的平均增益。














 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









