








来源:ACL 2022
论文认为存在的问题:
当前的NER任务被转换为MRC任务,但是存在以下问题:
- 每次一个问题只能抽取到一种类型的实体,效率不够高
- 不同实体之间抽取是分割,没有考虑到实体之间的依赖性
- 问题构造依赖于外部知识库,当存在上百个实体,MRC模式很难应用于
因此,提出了PIQN(Parallel Instance Query Network)模型,设定全局和可学习的实例查询语句,同时可并行从句子抽取各类实体。
方法对比:

这里的 Instance Query 并不是真实的句子文本,而是query id映射的embedding ,
如:[[0, 1,2,3,4,5,…],[0,1,2,3,4,5,…]]
但是query是隐性的,如何将query与entity对应起来,作者提出了把标签分配问题看作:
one-to-many Linear Assignment Problem (LAP)
代表一个entity可以匹配到多个query
LAP:
先了解一下分配任务:
分配问题也称指派问题,是一种特殊的整数规划问题,分配问题的要求一般是这样的:
n个人分配n项任务,一个人只能分配一项任务,一项任务只能分配给一个人,将一项任务分配给一个人是需要支付报酬,如何分配任务,保证支付的报酬总数最小。
简单的说:就是n*n矩阵中,选取n个元素,每行每列各有一个元素,使得和最小。
主要解决方法为:匈牙利算法
其实,分配问题也可以看作二分图求最大匹配,work与job进行分配
最大匹配 给定一个二分图G,在G的一个子图M中,M的边集中的任意两条边都不依附于同一个顶点,则称M是一个匹配.
选择这样的边数最大的子集称为图的最大匹配问题(maximal matching problem)
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。 求二分图最大匹配可以用最大流或者匈牙利算法。
scipy.optimize.linear_sum_assignment

线性分配问题也叫做二分图中的最小权重匹配,存在一个matrix C,C[i,j]代表着work与job的匹配的成本,目标是找到work与job匹配的最小代价。
定义了一个bool矩阵,X[i,j]=1 代表第i行分配给j列。X是方阵,每一行恰好分配给一列,每一列恰好分配给一行。
此函数还可以解决成本矩阵为矩形的分配问题的推广,如果它的行多于列,则不需要将每一行分配给一列,反之亦然。
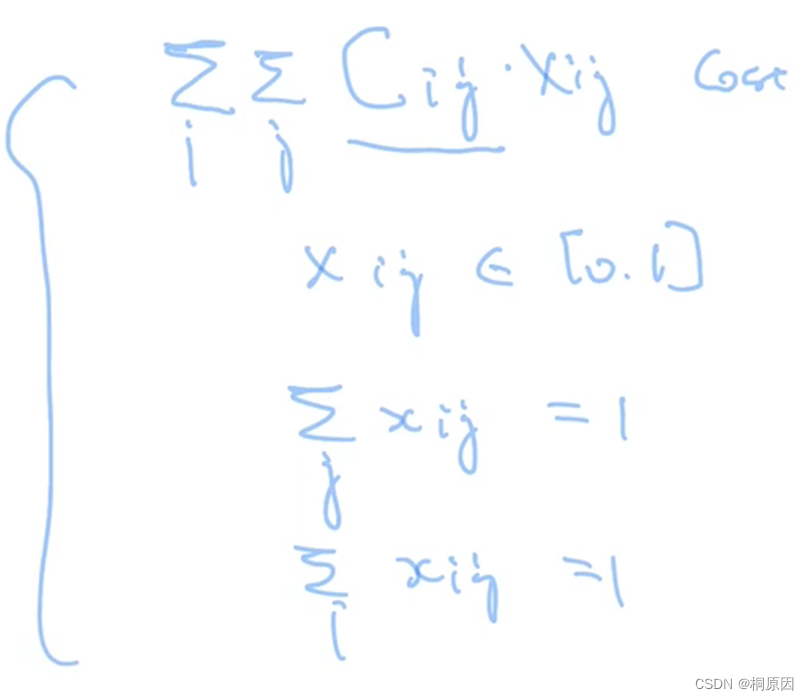
其中X需要满足的约束,每一行恰好分配给一列,每一列恰好分配给一行。
举例:

模型架构图
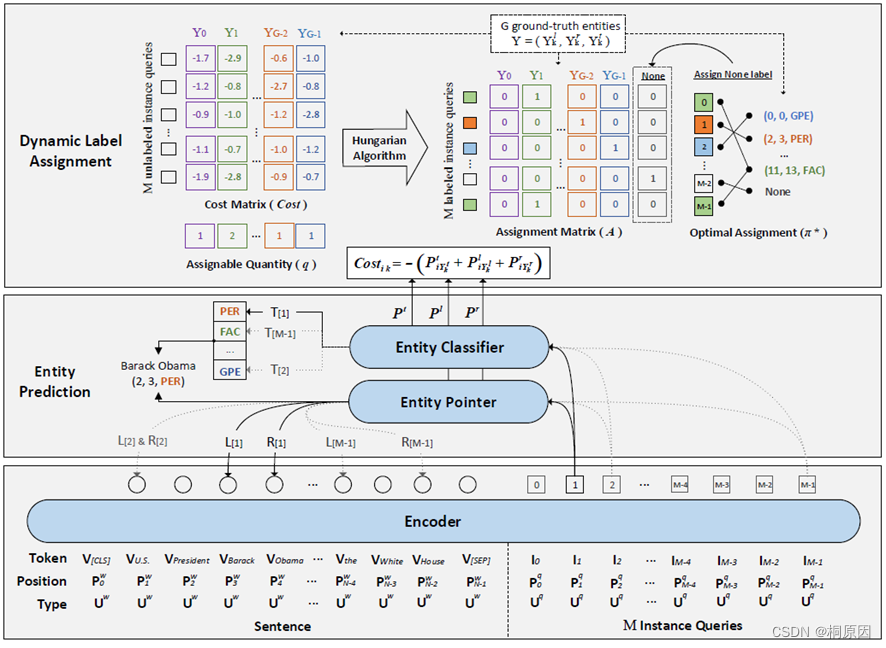
Encoder
输入:句子embeding (len:N )+ query id(len: M)的序列
在Encoder内部中 attention 矩阵是 (N+M)*(N+M)的,为了防止句子attention到query,矩阵的上三角被mask掉。
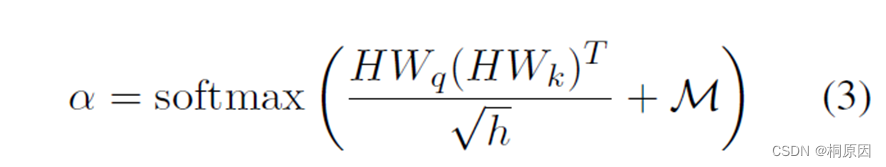
输出:句子的隐层信息H^W
query的隐藏信息H^q
span预测
利用指针网络进行线性预测
句子的隐层和问题的隐层分别过一个线性层进行映射,拼接后过Relu激活函数,得到交互的表征
最后利用sigmoid函数获取start、end位置信息

类别分类
基于预测得到的start、end的位置信息,加上query信息,以便获取最后类别信息

而在代码实现中,query信息先和content内容先进行attention交互。

然后进行拼接,分类。
Dynamic Label Assignment for Training
前面提到query是隐性,不能直接分配gold实体,因此,需要在训练中动态分配实体标签。
把分配问题看作Linear Assignment Problem
声明:待分配的第k个实体,三元组为 end、start、type
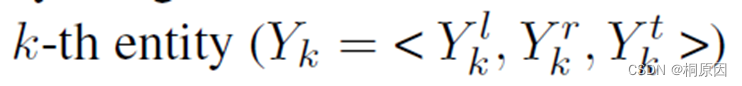
定义成本矩阵 cost
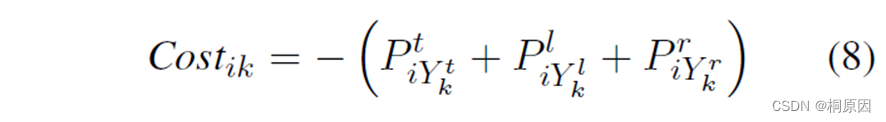
P为logits
如果一个entity只能分配一个query,则无法解决嵌套实体问题。因此,作者将一句话中的实体复制q_k份,这样可直接利用匈牙利算法实现一对多的分配问题。
优化目标:

这里与匈牙利算法不同的地方在于entity的约束变了,每个实体可以分配多个query,但是本质上,这样的变化并不没有改变匈牙利算法原本的约束条件,而是通过复制多个相同的entity去映射到不同的query上面。
由于设定query的数量M远大于每句entity的数量,部分query肯定不会分配到实体,因此在分配矩阵A中加入了一列None,将未分配的query在None这一列设定为1
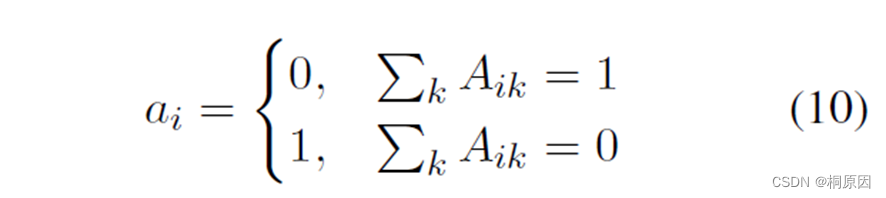
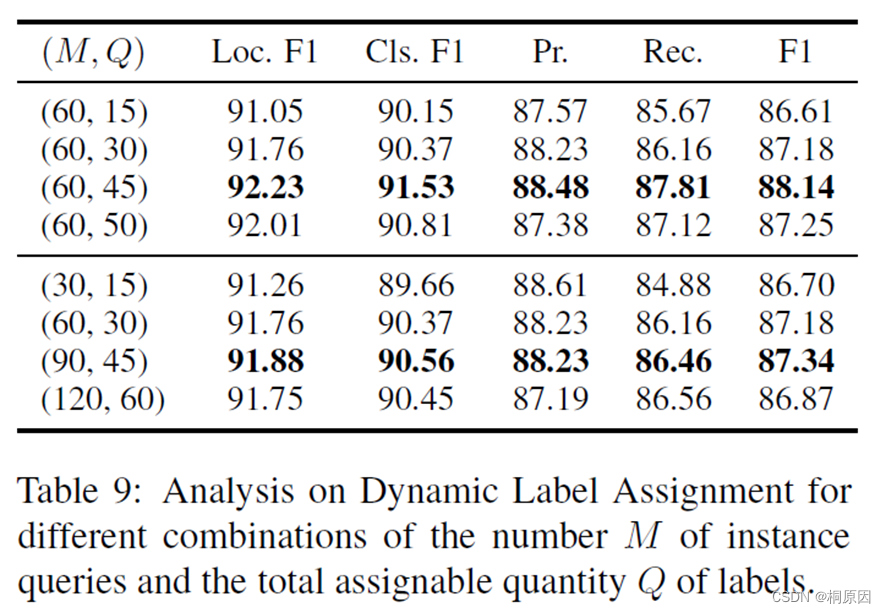
为什么是query远大于entity数量,作者也做了实验进行分析,发现query为60,重复entity为45,比例在4:3,效果最好。太大反而可能导致模型性能下降。算是一个经验值。
获取到最终的分配矩阵大小为(M, G+1)
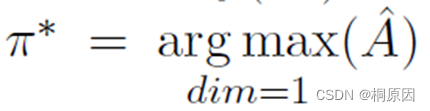
最后argmax获取到分配的index,得到标签Y
读到这里存在一个问题,为什么无信息的query id可以提升抽取性能,仅靠着分配算法,将不同实体分配到query id上面,其实id序列也可以说成隐性的对应的label外部信息,然后进行匈牙利算法分配,来提升效果。
训练目标:
对于start、end用二分类交叉熵计算loss,类别用交叉熵计算loss,同时加入模型最后几层transformer layer的loss
类别:
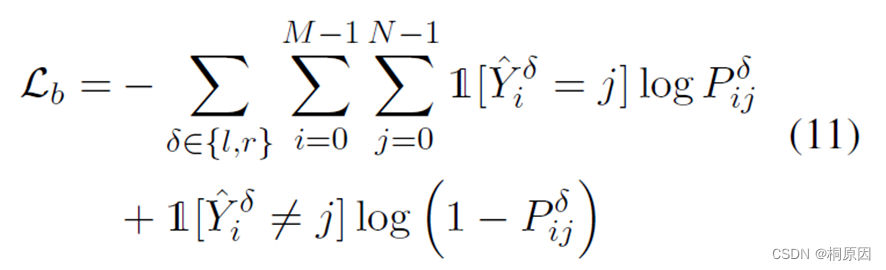
边界:
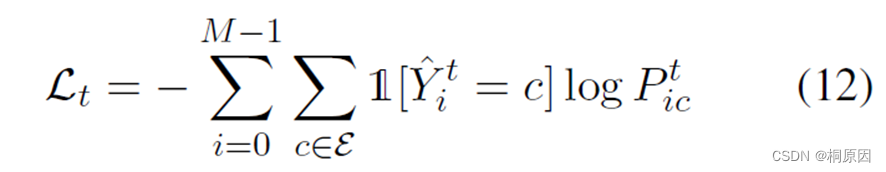
最终的loss
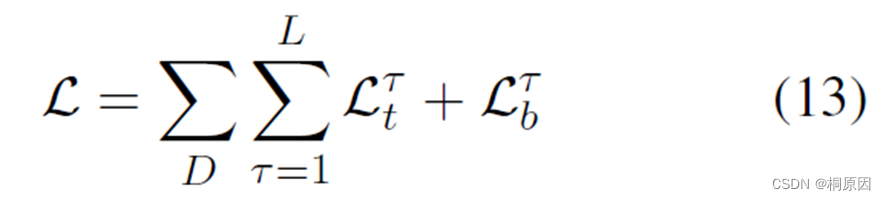
结果:
在嵌套实体数据集ACE04、ACE05、KBP17、GENIA、NNE(114实体类型)
在flat实体数据集FewNERD(66实体类型)、CoNLL03、OntoNotes、
中文数据集:MSRA
均达到SOTA
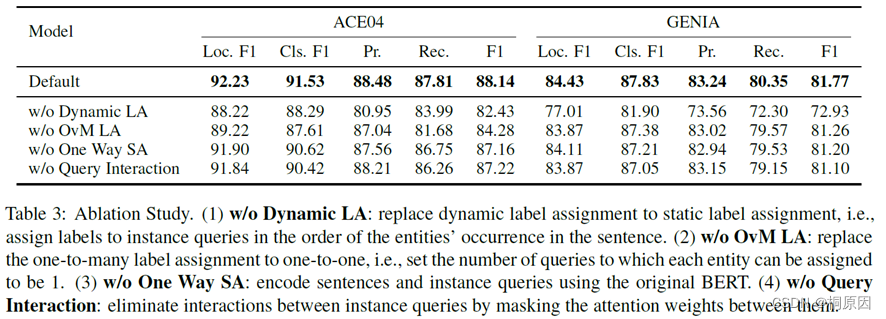
消融实验:
推理速度对比:
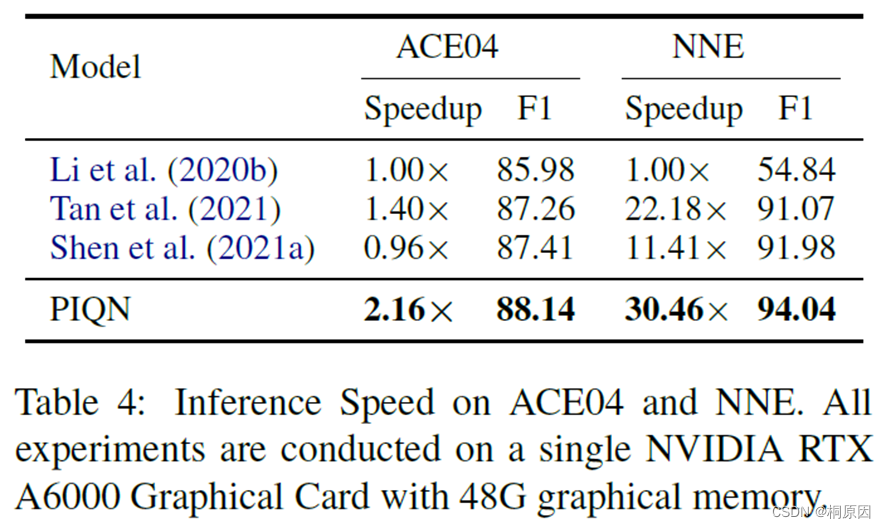
只能说好有钱
分析:
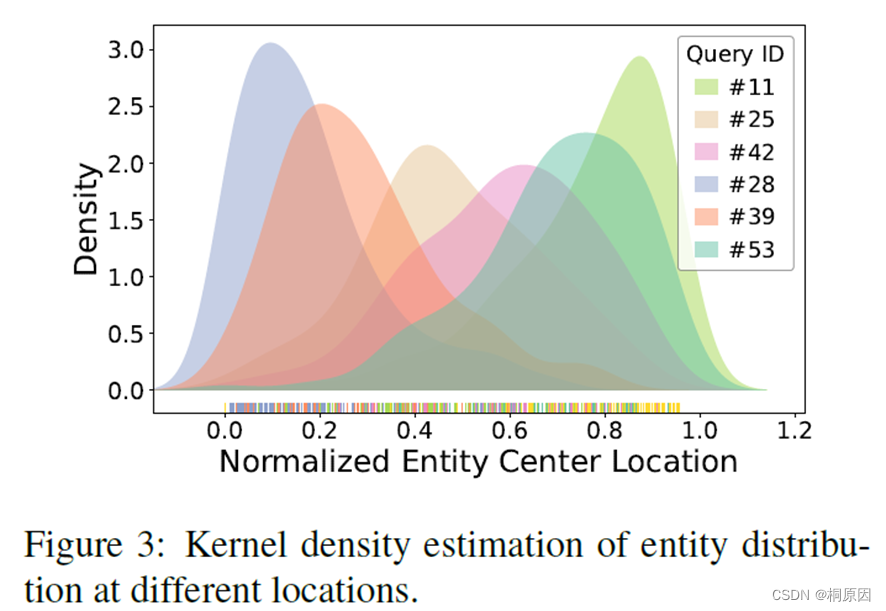
随机选择query id进行实体locations和类型的分析
使用 kernel density estimation (核密度估计来估计未知的密度函数,核密度估计的结果即为样本的概率密度函数估计,可以得到数据分布的一些性质)画预测实体位置的分布图 ,发现不同query注意的实体位置不同,这表明query能学习到关于实体位置信息的语义。
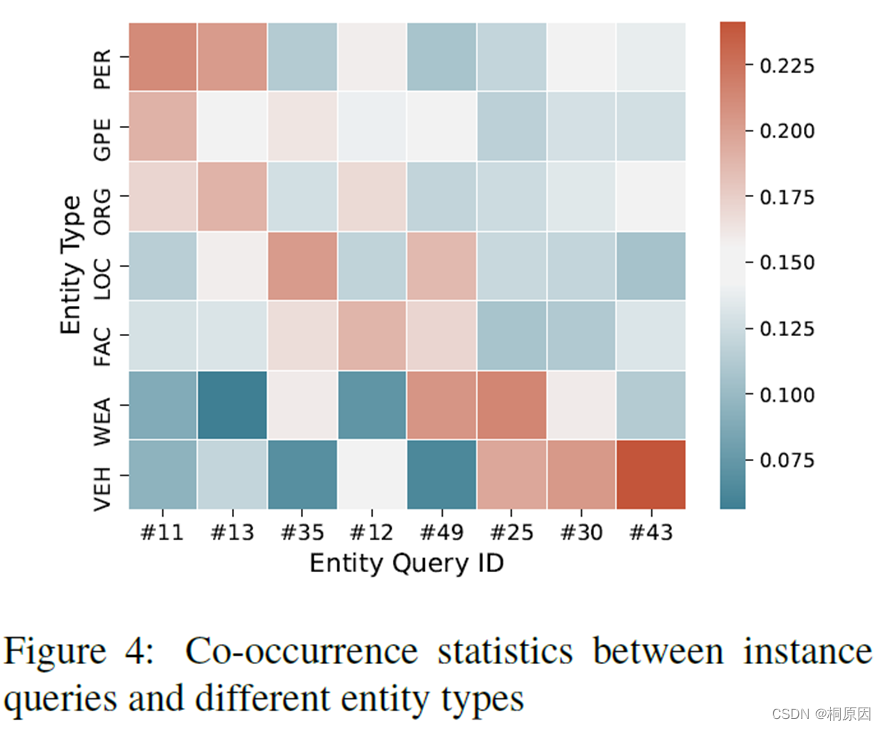
作者计算不同类型query和不同类型实体共同发生的概率,从下图的例子看到,#11和#13query倾向预测PER,#30和#43倾向预测VEH,#25和#49倾向预测WEA,#35倾向预测LOC
Case Study

实验发现对于长文本和嵌套效果也都不错
但是仍然存在一定问题:
1)缺少对领域词汇的理解,Yahoo ! Communications Services 在例子2中被误识别为ORG
2)过度关注于局部语义,例子3中将 Venezuelan consumer 误识别为 PER,忽略了长文本 the Venezuelan consumer protection agency 是ORG
3)对形近词区分不清晰,模型混淆了Venezuelan(形容词:委内瑞拉的,名词:委内瑞拉人)和Venezuela(委內瑞拉),在例子3中前者被认为是GPE















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









