






bert源码解读
暂且先看源码,原理和参考了谁的博客等后续完善吧
激活函数
def gelu(x):
"""Implementation of the gelu activation function.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Also see https://arxiv.org/abs/1606.08415
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu}
首先就是定义了 gelu 激活函数,Bert 中不同于传统 Transformer,Bert 中的某些层的激活函数使用了 gelu 来代替 relu,使得具备了更多的随机因素,在 gelu的论文 中,gelu 的实验效果也要优于 relu。
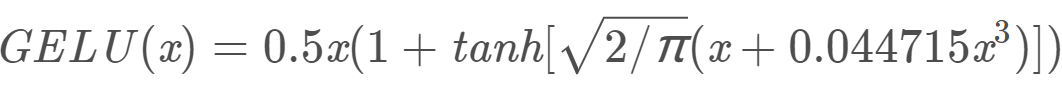
配置模块
class BertConfig(object):
"""Configuration class to store the configuration of a `BertModel`.
"""
def __init__(self,
vocab_size, # 字典字数
hidden_size=384, # 隐藏层维度也就是字向量维度,可以理解为我们把这个字向量映射成多长的维度
num_hidden_layers=6, # transformer block 的个数
num_attention_heads=12, # 注意力机制"头"的个数 讲道理这两个参数应该是可以调的吧
intermediate_size=384*4, # feedforward层线性映射的维度
hidden_act="gelu", # 激活函数
hidden_dropout_prob=0.4, # dropout的概率,为了防止过拟合,每次会丢掉一部分的参数
attention_probs_dropout_prob=0.4,
max_position_embeddings=512*2,#位置编码的最大长度
type_vocab_size=256, # 用来做next sentence预测,
# 这里预留了256个分类, 其实我们目前用到的只有0和1
initializer_range=0.02 # 用来初始化模型参数的标准差
):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
这是一个配置文件类,用于存储一些信息的
- vocab_size:在我们这个项目中可能出现的字的数量
- hidden_size:隐藏层的维度&字向量维度。embedding_dim
- num_hidden_layers:有几个隐藏层
- num_attention_head:定义多头机制里面的头的数量
- intermediate_size:这个维度说是feedforward层的先行映射的维度
- hidden_dropout_prob
- attention_probs_dropout_prob:这两个参数都是防止过拟合用的
- max_position_embeddings=512*2,#位置编码的最大长度,目前还不是很理解
- type_vocab_size=256, # 用来做next sentence预测,这里预留了256个分类, 其实我们目前用到的只有0和1
- initializer_range=0.02 # 用来初始化模型参数的标准差
Embedding部分
class BertEmbeddings(nn.Module):
"""LayerNorm层, 见Transformer(一), 讲编码器(encoder)的第1部分"""
"""Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super(BertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)#第一个参数是,词典大小,就是一个词典中有多少个字,第二个参数是隐藏层的大小,也可以理解为把一个字映射成多少的维度,第三个参数补0
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# embedding矩阵初始化
nn.init.orthogonal_(self.word_embeddings.weight) #初始化权重
nn.init.orthogonal_(self.token_type_embeddings.weight)#初始化另个权重
# embedding矩阵进行归一化
epsilon = 1e-8
self.word_embeddings.weight.data = \
self.word_embeddings.weight.data.div(torch.norm(self.word_embeddings.weight, p=2, dim=1, keepdim=True).data + epsilon)
self.token_type_embeddings.weight.data = \
self.token_type_embeddings.weight.data.div(torch.norm(self.token_type_embeddings.weight, p=2, dim=1, keepdim=True).data + epsilon)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, positional_enc, token_type_ids=None):
"""
:param input_ids: 维度 [batch_size, sequence_length]
:param positional_enc: 位置编码 [sequence_length, embedding_dimension]
:param token_type_ids: BERT训练的时候, 第一句是0, 第二句是1
:return: 维度 [batch_size, sequence_length, embedding_dimension]
"""
# 字向量查表
words_embeddings = self.word_embeddings(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + positional_enc + token_type_embeddings
# embeddings: [batch_size, sequence_length, embedding_dimension]
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings

embedding还有第三个参数padding_idx,他表示当句子长度不一致的时候,会用什么来数值来填充
__init__部分主要是一个Norm的过程。
L
a
y
e
r
N
o
r
m
a
l
i
z
a
t
i
o
n
Layer Normalization
LayerNormalization的作用是把神经网络中隐藏层归一为标准正态分布, 也就是
i
.
i
.
d
i.i.d
i.i.d独立同分布, 以起到加快训练速度, 加速收敛的作用:
forward 函数中,主要实现了 input_ids 与 token_type_ids 由 index token 到 embedding 的转化,以及 将 words embedding、positional encoding、token type embedding 相加生成最终输入 tansformer block 的 embedding,这里在相加后还进行了 Layer normal 和 dropout 的操作。
Self-Attention机制
class BertSelfAttention(nn.Module):
"""自注意力机制层, 见Transformer(一), 讲编码器(encoder)的第2部分"""
def __init__(self, config):
super(BertSelfAttention, self).__init__()
# 判断embedding dimension是否可以被num_attention_heads整除
if config.hidden_size % config.num_attention_heads != 0: #在这里判断multi-head 是否能被hidden_size整除,这里再次证明了所谓的hidden_size就是embedding size
raise ValueError( #不能整除就会丢出一个错误
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
self.num_attention_heads = config.num_attention_heads #定义头的数量
self.attention_head_size = int(config.hidden_size / config.num_attention_heads) #整除之后,定义q k v的 size大小
self.all_head_size = self.num_attention_heads * self.attention_head_size #我实在不懂这里脱裤子放屁在干啥= - =,这不就是embedding的大小吗
# Q, K, V线性映射
self.query = nn.Linear(config.hidden_size, self.all_head_size) #这里进行一个线性映射
self.key = nn.Linear(config.hidden_size, self.all_head_size) #线性映射+1
self.value = nn.Linear(config.hidden_size, self.all_head_size) #线性映射+1
self.dropout = nn.Dropout(config.attention_probs_dropout_prob) #定义一个dropout防止过拟合
def transpose_for_scores(self, x):
# 输入x为QKV中的一个, 维度: [batch_size, seq_length, embedding_dim]
# 输出的维度经过reshape和转置: [batch_size, num_heads, seq_length, embedding_dim / num_heads]
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask, get_attention_matrices=False):
# Q, K, V线性映射
# Q, K, V的维度为[batch_size, seq_length, num_heads * embedding_dim]
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# 把QKV分割成num_heads份
# 把维度转换为[batch_size, num_heads, seq_length, embedding_dim / num_heads]
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# Q与K求点积
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# attention_scores: [batch_size, num_heads, seq_length, seq_length]
# 除以K的dimension, 开平方根以归一为标准正态分布
attention_scores = attention_scores / math.sqrt(self.attention_head_size)#主要是想归一成正态分布
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask#这个attention_mask不知道是什么东西
# attention_mask 注意力矩阵mask: [batch_size, 1, 1, seq_length]
# 元素相加后, 会广播到维度: [batch_size, num_heads, seq_length, seq_length]
# softmax归一化, 得到注意力矩阵
# Normalize the attention scores to probabilities.
attention_probs_ = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs_)
# 用注意力矩阵加权V
context_layer = torch.matmul(attention_probs, value_layer)
# 把加权后的V reshape, 得到[batch_size, length, embedding_dimension]
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
# 输出attention矩阵用来可视化
if get_attention_matrices:
return context_layer, attention_probs_
return context_layer, None
__init__部分
首先先来了解一下nn.Linear()

在bias的地方愣了一下。因为在我的理解里面。在输入的[128*20]的矩阵中,每一行(20个值)代表了一个字向量的embedding,在[30*20]转置之后就是[20*30]的矩阵中,一列(20个参数)代表了一次参数,那么根据公式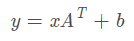
我人为的bias是一个[128*30]的矩阵,但是他其实是一个[30]的量,那其实说明他们共用的是一个bias。
···
self.query = nn.Linear(config.hidden_size, self.all_head_size) #这里进行一个线性映射
self.key = nn.Linear(config.hidden_size, self.all_head_size) #线性映射+1
self.value = nn.Linear(config.hidden_size, self.all_head_size) #线性映射+1
···
对这三句代码进行一个机制上的解释。这个其实在transformer的文章中有讲解,他其实是一个多头注意力机制,现在需要代码表示,那么就理解的更深入一些吧。

为了保证线性变换后的维度是一样的
Wq Wk Wv都是 embedding * embedding(这是在没有使用多头注意力机制的情况下)


transpose_for_scores 方法,实现了 Q,K,V 向量的维度转换,以及多头分割,将 Q,K,V 原始的维度 [ batch_size, seq_length, hidden_size ],转换为 [ batch_size, num_heads, seq_length, attention_head_size ]。由于在做Multi-head Self-attention时,是通过矩阵乘法的方式实现并行化的计算,所以需要在计算之初对多个头的 Q,K,V 向量进行分割并组成矩阵。
forward 方法具体实现了 Multi-head Self-attention 的操作,首先将隐藏层向量 hidden_states 通过不同的权重参数线性映射为 Q,K,V 向量,然后进行 Mutli-head 的划分,组成矩阵。Transformer 中计算 attention 权重值的公式如下:
代码中,第一步的 attention_scores 通过计算 Q Muti-head 矩阵与 K Muti-head 矩阵的矩阵乘乘积,实现了所有 Q 与 K 向量的点积的同步计算。由于 Q Muti-head 与 K Multi-head 矩阵的 shape 相同,所以在做矩阵乘法之前先要对每一个 head 的 K 向量矩阵进行转置的操作。经过计算后第一步的 attention_scores 的 shape 为:[ batch_size, num_heads, seq_length, seq_length ]。
第二步的 attention_scores 主要为公式中,计算点积值除以的部分,接下来将计算出的值,与 attention_mask 相加,会将 padding 时补充的占位符位置的相似度值置为负无穷大,以减小 padding 操作在后续 Softmax 中的影响。attention_mask 的 shape 为:[batch_size, 1, 1, seq_length ],在元素相加时,会自动广播到所有维度。
接下来,在最后一维 seq_length 的维度上,完成 Softmax 的操作,再经过 dropout ,得到最终的注意力权重矩阵 attention_probs。其维度为:[ batch_size, num_heads, seq_length, seq_length ]。
最后将注意权重矩阵与 V Multi-head 矩阵做矩阵乘法,实现方程中的最后一步。相乘后的 context_layer 维度为:[ batch_size, num_heads, seq_length, attention_head_size ]。此时就完成了所有 Multi-head attention 的并行计算,然后再将所有 head 的计算结果进行拼接,也就是将 context_layer 重新 reshape 为 hidden layer 的维度。最终经过 Self-attention 后的输出的维度仍为:[ batch_size, seq_length, embedding_size ]
也就是说,最后的到的是 batch_size,表明有几句话,seq_length,表示句子长度,embedding_size的一个矩阵,这个矩阵是含有每一个字对于当前话的权重影响。 这句话很重要,但是我还需要理解
补充:attention_mask是填充用的,使矩阵都是变成一个维度
补充:这个是我之前理解的一个错误的地方。对于Wq Wk Wv矩阵,他们是一个[embedding,embedding]的矩阵,对于映射后的矩阵变成一个[seqlength,embedding]的矩阵,这是映射之后Q K V,然后在embedding的维度上进行呢切分,切分成embedding/h的维度,分成了多头注意力矩阵。此时在进行[seqlength,embedding/h]矩阵的点集,成就的是[seqlength,seqlength],再乘上V矩阵(此时的V矩阵也也进行了分割)变成了[seqlength,embedding/h]的矩阵,进行一个点集,变成[seqlength,embedding/h]的矩阵,此时再进行一个凭借,把多个头拼接成一个[seqlength,embedding]的矩阵
补充:context_layer, attention_probs_ context_layer是矩阵一个[batch_size,seqlength,embedding]的矩阵,他含有了很多信息,而attention_probs_就是一系列的参数,可以理解为,attention_probs_加权V就变成了context_layer
Layer Normalization
class BertLayerNorm(nn.Module):
"""LayerNorm层, 见Transformer(一), 讲编码器(encoder)的第3部分"""
def __init__(self, hidden_size, eps=1e-12):
"""Construct a layernorm module in the TF style (epsilon inside the square root).
"""
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
Bert 中有许多地方使用了 Layer Normalization 的操作,对每一层的输出向量进行分布调整,以加快网络的训练速度。Layer Normalization 的方程如下:
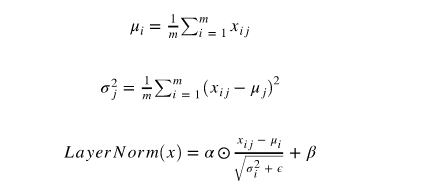
- u就是一个均值
- s是一个方差
- x就是我们需要部分
- 乘上weight和bias这都是可以训练的部分
- eps的存在是防止我们乘0。
forward 方法实现了 Layer Normalization 的操作。
先来解释一下
Attention 与 Add & Normal 的封装
class BertSelfOutput(nn.Module):
# 封装的LayerNorm和残差连接, 用于处理SelfAttention的输出
def __init__(self, config):
super(BertSelfOutput, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
封装的LayerNorm和残差连接, 用于处理SelfAttention的输出,这句话说的很明确了
class BertOutput(nn.Module):
# 封装的LayerNorm和残差连接, 用于处理FeedForward层的输出
def __init__(self, config):
super(BertOutput, self).__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class BertLayer(nn.Module):
# 一个transformer block
def __init__(self, config):
super(BertLayer, self).__init__()
self.attention = BertAttention(config)
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(self, hidden_states, attention_mask, get_attention_matrices=False):
# Attention层(包括LayerNorm和残差连接)
attention_output, attention_matrices = self.attention(hidden_states, attention_mask, get_attention_matrices=get_attention_matrices)
# FeedForward层
intermediate_output = self.intermediate(attention_output)
# LayerNorm与残差连接输出层
layer_output = self.output(intermediate_output, attention_output)
return layer_output, attention_matrices
到这儿相当于分装一个tansformer层了
class BertEncoder(nn.Module):
# transformer blocks * N
def __init__(self, config):
super(BertEncoder, self).__init__()
layer = BertLayer(config)
# 复制N个transformer block
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
def forward(self, hidden_states, attention_mask, output_all_encoded_layers=True, get_attention_matrices=False):
"""
:param output_all_encoded_layers: 是否输出每一个transformer block的隐藏层计算结果
:param get_attention_matrices: 是否输出注意力矩阵, 可用于可视化
"""
all_attention_matrices = []
all_encoder_layers = []
for layer_module in self.layer:
hidden_states, attention_matrices = layer_module(hidden_states, attention_mask, get_attention_matrices=get_attention_matrices)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
all_attention_matrices.append(attention_matrices)
if not output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
all_attention_matrices.append(attention_matrices)
return all_encoder_layers, all_attention_matrices
把多个tansformer封装到一个encoder.
class BertPooler(nn.Module):
"""Pooler是把隐藏层(hidden state)中对应#CLS#的token的一条提取出来的功能"""
def __init__(self, config):
super(BertPooler, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
# 线性映射, 激活, LayerNorm
class BertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super(BertPredictionHeadTransform, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.transform_act_fn = ACT2FN[config.hidden_act]
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class BertLMPredictionHead(nn.Module):
def __init__(self, config, bert_model_embedding_weights):
super(BertLMPredictionHead, self).__init__()
# 线性映射, 激活, LayerNorm
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(bert_model_embedding_weights.size(1),
bert_model_embedding_weights.size(0),
bias=False)
"""上面是创建一个线性映射层, 把transformer block输出的[batch_size, seq_len, embed_dim]
映射为[batch_size, seq_len, vocab_size], 也就是把最后一个维度映射成字典中字的数量,
获取MaskedLM的预测结果, 注意这里其实也可以直接矩阵成embedding矩阵的转置,
但一般情况下我们要随机初始化新的一层参数
"""
self.decoder.weight = bert_model_embedding_weights
self.bias = nn.Parameter(torch.zeros(bert_model_embedding_weights.size(0)))
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states) + self.bias
return hidden_states
上面两部分代码中,BertPredictionHeadTransform 类封装了一个顺序为:线性变换,激活,Layer Normal 的变换流程,为后续的 Masked language modeling 任务做准备。
BertLMPredictionHead 类中,实现了将 hidden layer 的输出由 [ batch_size, seq_length, hidden_size ] 转化为 [ batch_size, seq_length, vocab_size ] 的维度变换。这样就可以通过 Softmax 归一化 vocab_size 的概率,对 sequence 中被 mask 调的字进行预测了。
话是这么硕没错,但是对于 hidden_size与vocab_size的关系。就是字向量维度难道不是一个one-hot编码?然后直接映射,这个不理解,第二个就是
···
class BertPreTrainingHeads(nn.Module):
“”"
BERT的训练中通过隐藏层输出Masked LM的预测和Next Sentence的预测
“”"
def init(self, config, bert_model_embedding_weights):
super(BertPreTrainingHeads, self).init()
self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
# 把transformer block输出的[batch_size, seq_len, embed_dim]
# 映射为[batch_size, seq_len, vocab_size]
# 用来进行MaskedLM的预测
self.seq_relationship = nn.Linear(config.hidden_size, 2)
# 用来把pooled_output也就是对应#CLS#的那一条向量映射为2分类
# 用来进行Next Sentence的预测
def forward(self, sequence_output, pooled_output):
prediction_scores = self.predictions(sequence_output)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score
···
这里可以看到其实,对于cls是一个二分类的问题。是上下文和不是上下文的区别,prediction_scores是对于mask使用的
class BertPreTrainedModel(nn.Module):
""" An abstract class to handle weights initialization and
a simple interface for dowloading and loading pretrained models.
用来初始化模型参数
"""
def __init__(self, config, *inputs, **kwargs):
super(BertPreTrainedModel, self).__init__()
if not isinstance(config, BertConfig):
raise ValueError(
"Parameter config in `{}(config)` should be an instance of class `BertConfig`. "
"To create a model from a Google pretrained model use "
"`model = {}.from_pretrained(PRETRAINED_MODEL_NAME)`".format(
self.__class__.__name__, self.__class__.__name__
))
self.config = config
def init_bert_weights(self, module):
""" Initialize the weights.
"""
if isinstance(module, (nn.Linear)):
# 初始线性映射层的参数为正态分布
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
elif isinstance(module, BertLayerNorm):
# 初始化LayerNorm中的alpha为全1, beta为全0
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
# 初始化偏置为0
module.bias.data.zero_()
一个参数的初始化过程
class BertModel(BertPreTrainedModel):
"""BERT model ("Bidirectional Embedding Representations from a Transformer").
Params:
config: a BertConfig class instance with the configuration to build a new model
Inputs:
`input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
`extract_features.py`, `run_classifier.py` and `run_squad.py`)
`token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
a `sentence B` token (see BERT paper for more details).
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
input sequence length in the current batch. It's the mask that we typically use for attention when
a batch has varying length sentences.
`output_all_encoded_layers`: boolean which controls the content of the `encoded_layers` output as described below. Default: `True`.
Outputs: Tuple of (encoded_layers, pooled_output)
`encoded_layers`: controled by `output_all_encoded_layers` argument:
- `output_all_encoded_layers=True`: outputs a list of the full sequences of encoded-hidden-states at the end
of each attention block (i.e. 12 full sequences for BERT-base, 24 for BERT-large), each
encoded-hidden-state is a torch.FloatTensor of size [batch_size, sequence_length, hidden_size],
- `output_all_encoded_layers=False`: outputs only the full sequence of hidden-states corresponding
to the last attention block of shape [batch_size, sequence_length, hidden_size],
`pooled_output`: a torch.FloatTensor of size [batch_size, hidden_size] which is the output of a
classifier pretrained on top of the hidden state associated to the first character of the
input (`CLS`) to train on the Next-Sentence task (see BERT's paper).
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
config = modeling.BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
model = modeling.BertModel(config=config)
all_encoder_layers, pooled_output = model(input_ids, token_type_ids, input_mask)
```
"""
def __init__(self, config):
super(BertModel, self).__init__(config)
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config)
self.apply(self.init_bert_weights)
def forward(self, input_ids, positional_enc, token_type_ids=None, attention_mask=None,
output_all_encoded_layers=True, get_attention_matrices=False):
if attention_mask is None:
# torch.LongTensor
# attention_mask = torch.ones_like(input_ids)
attention_mask = (input_ids > 0)
# attention_mask [batch_size, length]
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
# 注意力矩阵mask: [batch_size, 1, 1, seq_length]
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# 给注意力矩阵里padding的无效区域加一个很大的负数的偏置, 为了使softmax之后这些无效区域仍然为0, 不参与后续计算
# embedding层
embedding_output = self.embeddings(input_ids, positional_enc, token_type_ids)
# 经过所有定义的transformer block之后的输出
encoded_layers, all_attention_matrices = self.encoder(embedding_output,
extended_attention_mask,
output_all_encoded_layers=output_all_encoded_layers,
get_attention_matrices=get_attention_matrices)
# 可输出所有层的注意力矩阵用于可视化
if get_attention_matrices:
return all_attention_matrices
# [-1]为最后一个transformer block的隐藏层的计算结果
sequence_output = encoded_layers[-1]
# pooled_output为隐藏层中#CLS#对应的token的一条向量
pooled_output = self.pooler(sequence_output)
if not output_all_encoded_layers:
encoded_layers = encoded_layers[-1]
return encoded_layers, pooled_output
接下来的相当于是组装前面说过的部分
讲完了之前的源码,这一部分源码就变得很简单了。 inint 方法实例化了前面的三大模块,分别是:
1.处理 word embedding、positional encoding、和 token_type_embedding 的 BertEmbeddings 模块。
2.经过N个 Transformer Block 堆叠好的 BertEncoder 模块。
3.用于提取 hidden state 中,对应 #CLS# 的 token 的 vector 的 BertPooler 模块。
forward 方法中,首先处理attention_mask 矩阵,用于在计算 attention 权重值时,减少 padding 带来的影响。接下来将 embedding 层的输出和 attention_mask 矩阵传入 BertEncoder 部分,再对 output_all_encoded_layers 标识位进行判断,决定返回每一层 Transformer Block 的输出,还是只返回最后一层的最终结果。同时返回 #CLS# 对应的 hidden state。
就注意一下[-1]这个节点,因为我们是包装了tansformer6个为一个list,但是我们其实只需要最后一层输出就行,最后还给了参数,如果你想可视化参数的话
class BertForPreTraining(BertPreTrainedModel):
"""BERT model with pre-training heads.
This module comprises the BERT model followed by the two pre-training heads:
- the masked language modeling head, and
- the next sentence classification head.
Params:
config: a BertConfig class instance with the configuration to build a new model.
Inputs:
`input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
`extract_features.py`, `run_classifier.py` and `run_squad.py`)
`token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
a `sentence B` token (see BERT paper for more details).
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
input sequence length in the current batch. It's the mask that we typically use for attention when
a batch has varying length sentences.
`masked_lm_labels`: optional masked language modeling labels: torch.LongTensor of shape [batch_size, sequence_length]
with indices selected in [-1, 0, ..., vocab_size]. All labels set to -1 are ignored (masked), the loss
is only computed for the labels set in [0, ..., vocab_size]
`next_sentence_label`: optional next sentence classification loss: torch.LongTensor of shape [batch_size]
with indices selected in [0, 1].
0 => next sentence is the continuation, 1 => next sentence is a random sentence.
Outputs:
if `masked_lm_labels` and `next_sentence_label` are not `None`:
Outputs the total_loss which is the sum of the masked language modeling loss and the next
sentence classification loss.
if `masked_lm_labels` or `next_sentence_label` is `None`:
Outputs a tuple comprising
- the masked language modeling logits of shape [batch_size, sequence_length, vocab_size], and
- the next sentence classification logits of shape [batch_size, 2].
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
model = BertForPreTraining(config)
masked_lm_logits_scores, seq_relationship_logits = model(input_ids, token_type_ids, input_mask)
```
"""
def __init__(self, config):
super(BertForPreTraining, self).__init__(config)
self.bert = BertModel(config)
self.cls = BertPreTrainingHeads(config, self.bert.embeddings.word_embeddings.weight)
self.apply(self.init_bert_weights)
self.vocab_size = config.vocab_size
self.next_loss_func = CrossEntropyLoss()
self.mlm_loss_func = CrossEntropyLoss(ignore_index=0)
def compute_loss(self, predictions, labels, num_class=2, ignore_index=-100):
loss_func = CrossEntropyLoss(ignore_index=ignore_index)
return loss_func(predictions.view(-1, num_class), labels.view(-1))
def forward(self, input_ids, positional_enc, token_type_ids=None, attention_mask=None,
masked_lm_labels=None, next_sentence_label=None):
sequence_output, pooled_output = self.bert(input_ids, positional_enc, token_type_ids, attention_mask,
output_all_encoded_layers=False)
mlm_preds, next_sen_preds = self.cls(sequence_output, pooled_output)
return mlm_preds, next_sen_preds
这是在预训练的时候要用到的类,而其实很明显,只要关注最后的输出就行了,对应的分别是mask的预测值和next_seq的预测值。
终于到了最后一个模块,BertForPreTraining 类。这是最终在预训练 Bert 时调用的类。
init 方法中,实例化 BertModel 类,得到 bert 模型。实例化 BertPreTrainingHeads 类,用于获得预训练 Bert 时,进行的两个任务的输出向量。模型参数初始化,获得词表大小,以及定义两个任务所用到的损失函数,都为 Cross-Entropy。
compute_loss 方法主要定义了 next_sentence_classification 任务中用到的 loss 计算。
forward 方法中,通过之前实例化好的 bert 模型计算得到 hidden state 的输出及 #CLS# 对应 token 的输出,在将他们进行线性变换,转化为可以直接计算 loss 的形式















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









