







Pandas模块是Python用于数据导入及整理的模块,对数据挖掘前期数据的处理工作十分有用,因此这些基础的东西还是要好好的学学。
Pandas模块的数据结构主要有两:1、Series ;2、DataFrame
这次就先了解一下Series结构。
1. 介绍
The Series is the primary building block of pandas and represents a one-dimensional labeled array based on the NumPy ndarray;(从书上搬来的,逃~)
大概就是说Series结构是基于NumPy的ndarray结构,是一个一维的标签矩阵(感觉跟python里的字典结构有点像)
- 1
- 2
- 3
2. 相关操作
a.创建
a.1、pd.Series([list],index=[list])//以list为参数,参数为一list;index为可选参数,若不填则默认index从0开始;若添则index长度与value长度相等
import pandas as pd
s=pd.Series([1,2,3,4,5],index=['a','b','c','f','e'])
print s
- 1
- 2
- 3
- 4

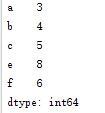
a.2、pd.Series({dict})//以一字典结构为参数
import pandas as pd
s=pd.Series({'a':3,'b':4,'c':5,'f':6,'e':8})
print s
- 1
- 2
- 3
- 4
b.取值
s[index] or s[[index的list]]
取值操作类似数组,当取不连续的多个值时可以以一list为参数
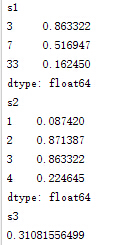
import pandas as pd
import numpy as np
v=np.random.random_sample(50)
s=pd.Series(v)
s1=s[[3,7,33]]
s2=s[1:5]
s3=s[49]
print "s1\n",s1
print "s2\n",s2
print "s3\n",s3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
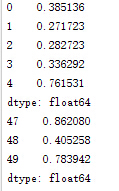
c..head(n);.tail(n)//取出头n行或尾n行,n为可选参数,若不填默认5
v=np.random.random_sample(50)
s=pd.Series(v)
print s.head()
print s.tail(3)
- 1
- 2
- 3
- 4
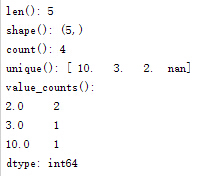
d、.index; .values//取出index 与values ,返回list
e、Size、shape、uniqueness、counts of values
v=[10,3,2,2,np.nan]
v=pd.Series(v);
print "len():",len(v)#Series长度,包括NaN
print "shape():",np.shape(v)#矩阵形状,(,)
print "count():",v.count()#Series长度,不包括NaN
print "unique():",v.unique()#出现不重复values值
print "value_counts():\n",v.value_counts()#统计value值出现次数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
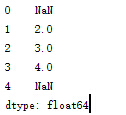
f.加运算
相同index的value相加,若index并非共有的则该index对应value变为NaN
import pandas as pd
s1=pd.Series([1,2,3,4],index=[1,2,3,4])
s2=pd.Series([1,1,1,1])
s3=s1+s2
print s3
- 1
- 2
- 3
- 4
- 5
- 6
<原创文章,转载请注明出处>















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









