







继上一篇文章,这篇文章介绍一下Pandas模块里面的DataFrame结构
1. 介绍
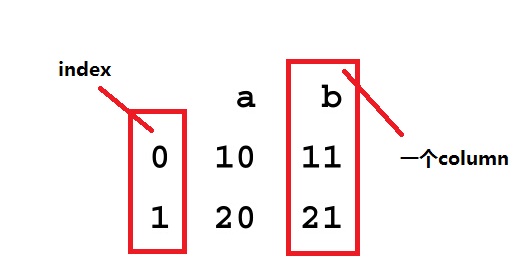
DataFrame unifies two or more Series into a single data structure.Each Series then represents a named column of the DataFrame, and instead of each column having its own index, the DataFrame provides a single index and the data in all columns is aligned to the master index of the DataFrame.
这段话的意思是,DataFrame提供的是一个类似表的结构,由多个Series组成,而Series在DataFrame中叫columns(理解有错请指出,(逃~
2. 相关操作
a.create
pd.DataFrame()
参数:
1、二维array;
2、Series 列表;
3、value为Series的字典;
a.1、二维array
import pandas as pd
import numpy as np
s1=np.array([1,2,3,4])
s2=np.array([5,6,7,8])
df=pd.DataFrame([s1,s2])
print df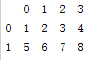
a.2、Series列表(效果与二维array相同)
import pandas as pd
import numpy as np
s1=pd.Series(np.array([1,2,3,4]))
s2=pd.Series(np.array([5,6,7, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3732
3732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









