







milvus 版本2.4之后支持多向量搜索,但是我使用的是v2.3.1也是支持多向量搜索的。
两种类型的搜索
单向量搜索,collection中只有一个向量字段,使用search()方法。
多向量搜索,collection中有两个和多个向量字段,使用hybrid_search()方法。执行多个近似最近邻ANN搜索请求,合并结果,重新排序,返回最相关的匹配项。
单向量搜索
import random
from pymilvus import (
connections,
Collection
)
dim = 128
if __name__ == '__main__':
connections.connect(alias="default", host="192.168.171.130", port='19530', user='', password='')
collection_name = 'first_milvus'
coll = Collection(collection_name)
search_param = {
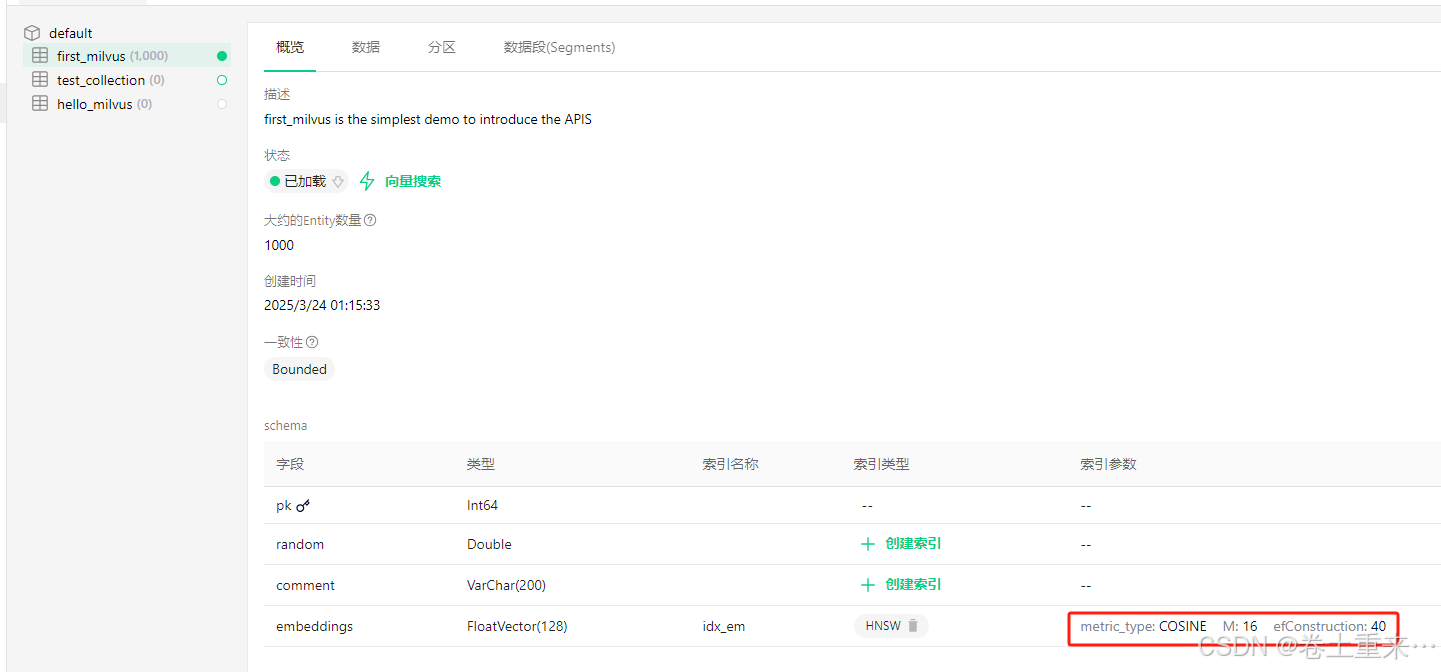
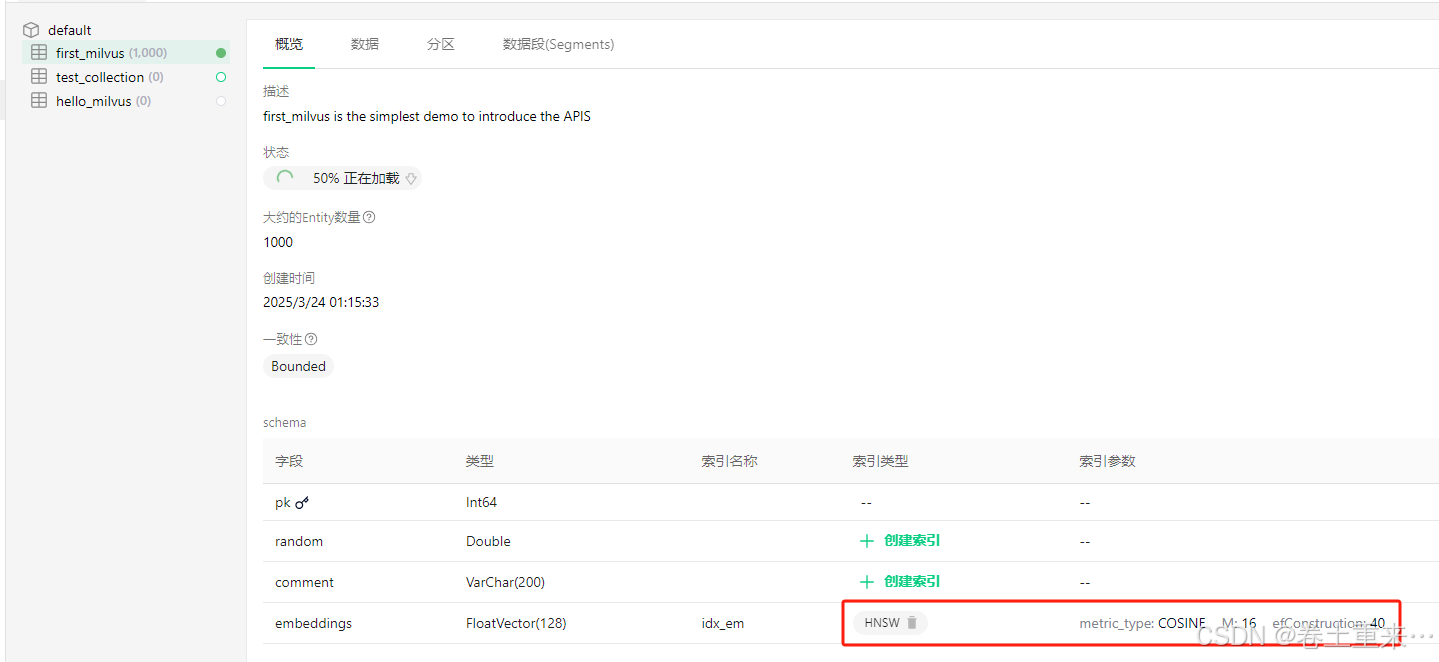
'metric_type': 'COSINE',
'params': {'ef': 40} # 注意:ef的值要大于等于limit的值
}
search_data = [random.random() for _ in range(dim)]
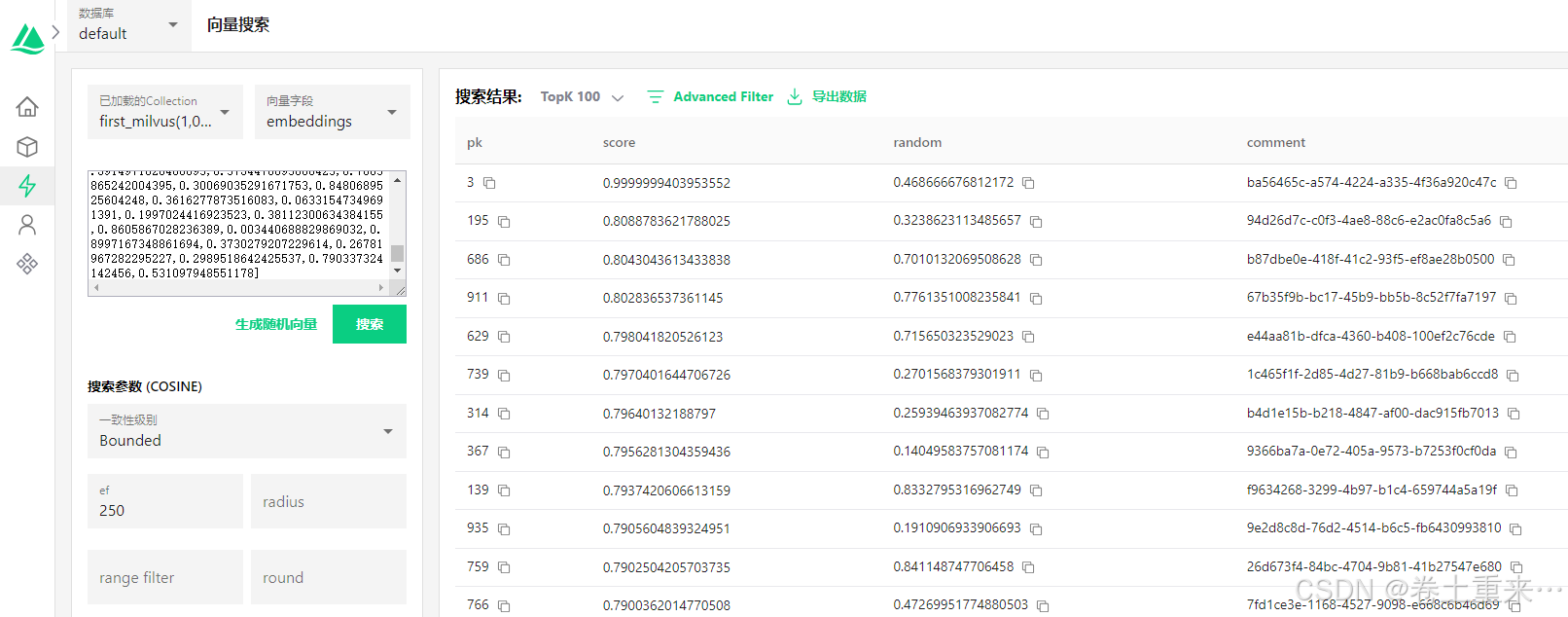
result = coll.search(
data=[search_data],
anns_field="embeddings",
param=search_param,
limit=5, # 对应attu中TopK5
output_fields=['pk', 'embeddings']
)
print(result)
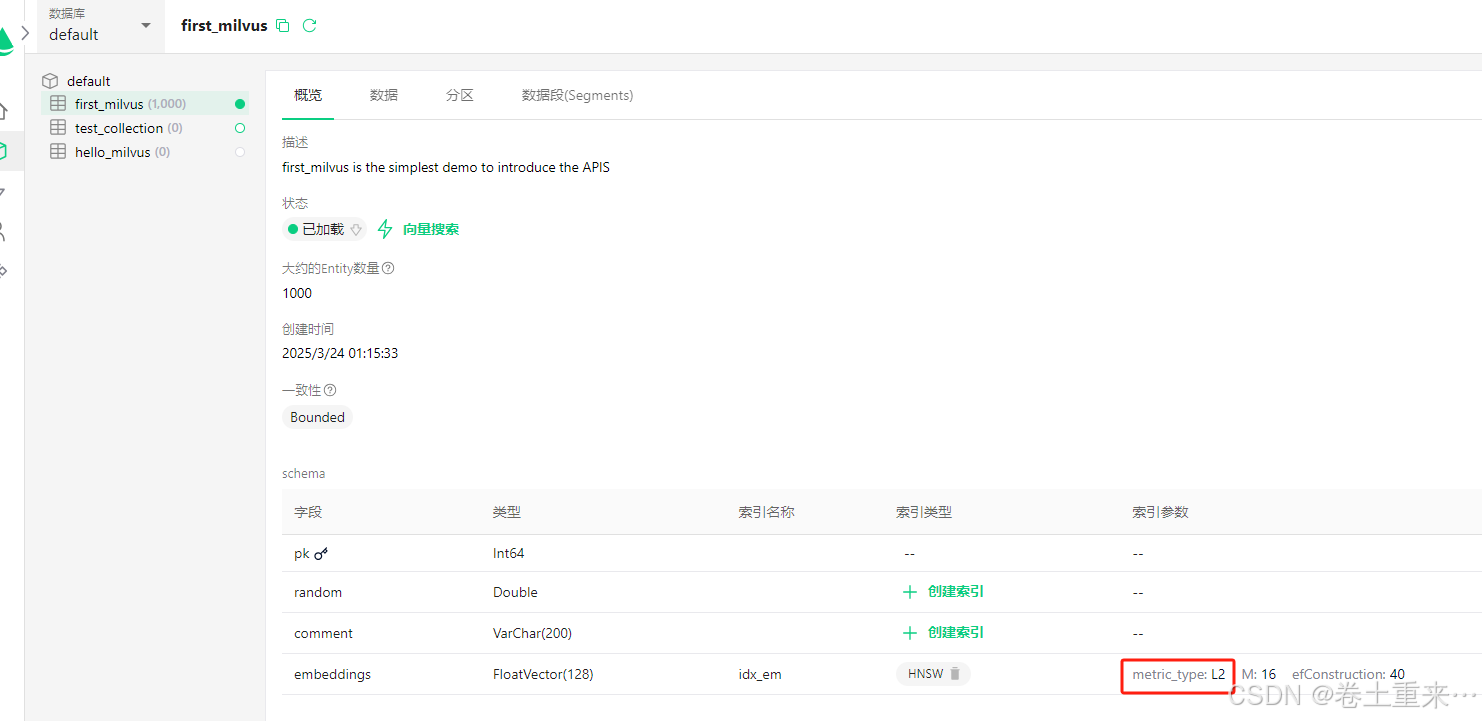
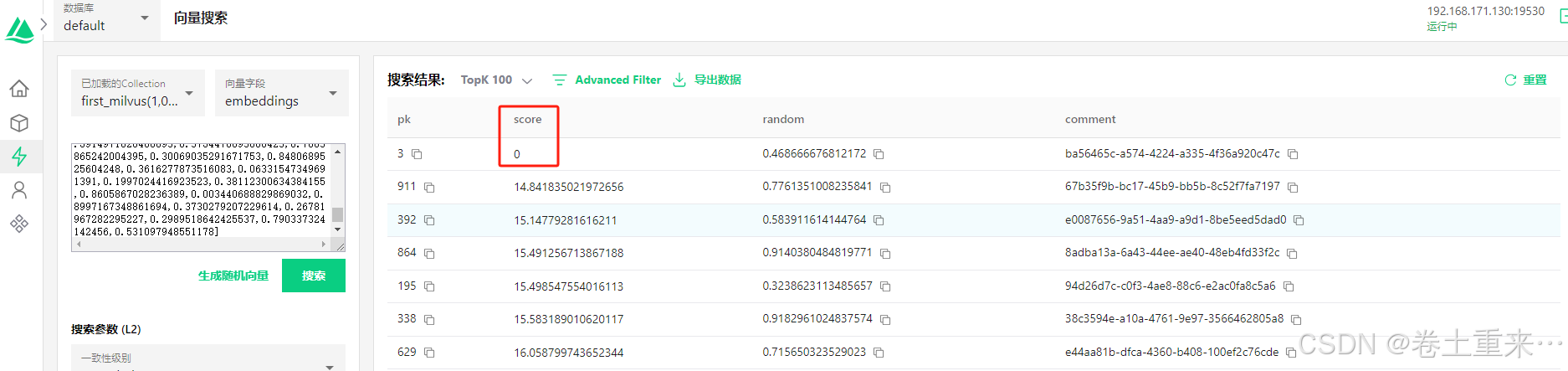
注意:metric_type如果为L2, 最佳匹配的score是0。如果为COSINE,最佳匹配的score是0.9999999403953552,也就说值越大越匹配。
多向量搜索
import random
from pymilvus import (
connections,
Collection
)
dim = 128
if __name__ == '__main__':
connections.connect(alias="default", host="192.168.171.130", port='19530', user='', password='')
collection_name = 'first_milvus'
coll = Collection(collection_name)
search_param = {
'metric_type': 'COSINE',
'params': {'ef': 40} # 注意:ef的值要大于等于limit的值
}
# 多向量查询
search_data = [[random.random() for _ in range(dim)], [random.random() for _ in range(dim)]]
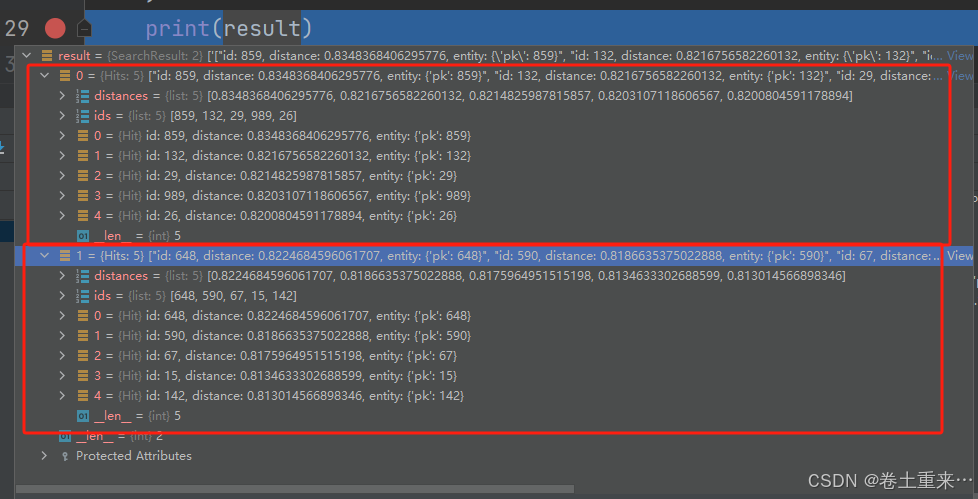
result = coll.search(
data=search_data,
anns_field="embeddings",
param=search_param,
limit=5, # 对应attu中TopK5
output_fields=['pk']
)
print(result)
返回的是一个也是一个数组,为每个查询向量返回一个单独的结果集。
分区搜索
创建一个collection,它的默认分区是_default
新建建其他分区 blue, red
向分区插入数据
代码实现
import uuid
import numpy as np
from pymilvus import (
connections,
FieldSchema,
CollectionSchema,
DataType,
Collection
)
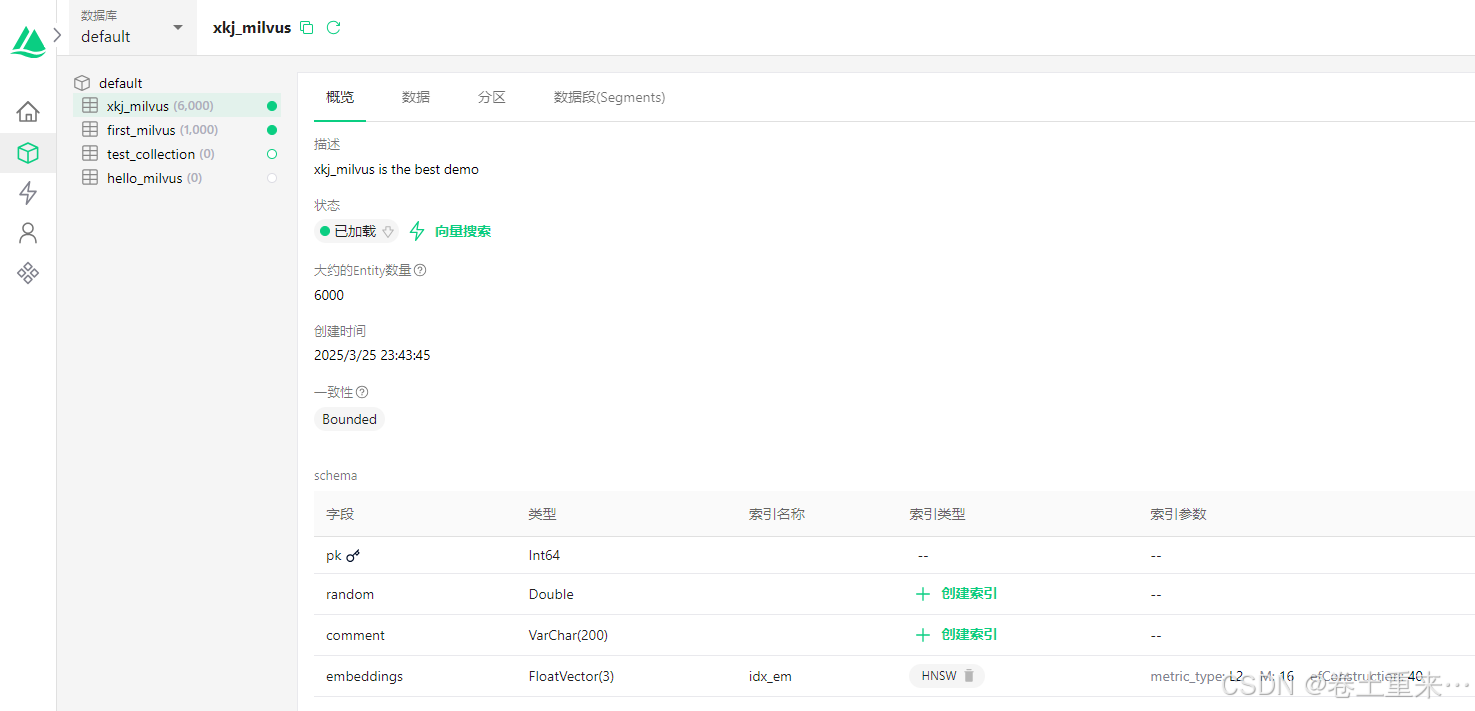
colletion_name = "xkj_milvus"
host = "192.168.171.130"
port = 19530
username = ""
password = ""
num_entities, dim = 3000, 3
def generate_uuid(number_of_uuids):
uuids = [str(uuid.uuid4()) for _ in range(number_of_uuids)]
return uuids
# 建立连接
connections.connect("default", host=host, port=port, user=username, password=password)
# 定义字段
field = [
FieldSchema(name="pk", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="comment", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
# 创建schema
schema = CollectionSchema(field, "xkj_milvus is the best demo")
# 创建collection
coll = Collection(colletion_name, schema, consistency_level="Bounded", shards_num=1)
# 创建分区blue,red
coll.create_partition(partition_name="blue")
coll.create_partition(partition_name="red")
# 插入数据
# seed=19530 设置了随机数生成器的种子,确保每次运行代码时生成的随机数序列是相同的(可重复性)。
rng = np.random.default_rng(seed=19530)
entities = [
# 生成一个从 0 到 num_entities - 1 的整数列表
[i for i in range(num_entities)],
# 随机数生成器 rng 生成 num_entities 个随机浮点数,范围在 [0, 1) 之间
# tolist() 将 NumPy 数组转换为 Python 列表
# 如果 num_entities = 3,可能生成 [0.123, 0.456, 0.789]
rng.random(num_entities).tolist(),
# 生成一个包含 num_entities 个 UUID 字符串的列表, 列表可能用于为每个实体分配一个全局唯一的标识符
generate_uuid(num_entities),
# 使用随机数生成器 rng 生成一个形状为 (num_entities, dim) 的二维 NumPy 数组
# num_entities表示二维数组中有几个数组,dim表示第二层数组里面有几个元素
rng.random((num_entities, dim)),
]
coll.insert(data=entities, partition_name="blue")
entities0 = [
# 生成一个从 0 到 num_entities - 1 的整数列表
[i+3000 for i in range(num_entities)],
# 随机数生成器 rng 生成 num_entities 个随机浮点数,范围在 [0, 1) 之间
# tolist() 将 NumPy 数组转换为 Python 列表
# 如果 num_entities = 3,可能生成 [0.123, 0.456, 0.789]
rng.random(num_entities).tolist(),
# 生成一个包含 num_entities 个 UUID 字符串的列表, 列表可能用于为每个实体分配一个全局唯一的标识符
generate_uuid(num_entities),
# 使用随机数生成器 rng 生成一个形状为 (num_entities, dim) 的二维 NumPy 数组
# num_entities表示二维数组中有几个数组,dim表示第二层数组里面有几个元素
rng.random((num_entities, dim)),
]
coll.insert(data=entities, partition_name="red")
# 刷新
coll.flush()
# 创建索引
index_params = {
"index_type": "HNSW",
"metric_type": "L2",
"params": {
"M": 16,
"efConstruction": 40
}
}
coll.create_index(
field_name="embeddings",
index_params=index_params,
index_name="idx_em"
)
# 加载到内存
coll.load()
print("done")

指定分区进行搜索
import random
from pymilvus import (
connections,
Collection
)
dim = 128
if __name__ == '__main__':
connections.connect(alias="default", host="192.168.171.130", port='19530', user='', password='')
collection_name = 'xkj_milvus'
coll = Collection(collection_name)
search_param = {
'metric_type': 'L2',
'params': {'ef': 40} # 注意:ef的值要大于等于limit的值
}
search_data = [[0.20963513851165771, 0.3974665701389313, 0.12019053101539612]]
result = coll.search(
data=search_data,
anns_field="embeddings",
param=search_param,
limit=5, # 对应attu中TopK5
output_fields=['pk'],
partition_names=["blue"]
# expr='',
# consistency_level="Eventually"
)
print(result)


















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











