







文本分割的粒度
缺陷
- 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
- 问题的答案可能跨越两个片段
改进: 按一定粒度,部分重叠式的切割文本,使上下文更完整
from nltk.tokenize import sent_tokenize
import json
def split_text(paragraphs, chunk_size=300, overlap_size=100):
'''按指定 chunk_size 和 overlap_size 交叠割文本'''
sentences = [s.strip() for p in paragraphs for s in sent_tokenize(p)]
chunks = []
i = 0
while i < len(sentences):
chunk = sentences[i]
overlap = ''
prev_len = 0
prev = i - 1
# 向前计算重叠部分
while prev >= 0 and len(sentences[prev])+len(overlap) <= overlap_size:
overlap = sentences[prev] + ' ' + overlap
prev -= 1
chunk = overlap+chunk
next = i + 1
# 向后计算当前chunk
while next < len(sentences) and len(sentences[next])+len(chunk) <= chunk_size:
chunk = chunk + ' ' + sentences[next]
next += 1
chunks.append(chunk)
i = next
return chunks
检索后排序(选)
问题: 有时,最合适的答案不一定排在检索的最前面
混合检索(Hybrid Search)(选)
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣。
举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆。
# 背景说明:在医学中“小细胞肺癌”和“非小细胞肺癌”是两种不同的癌症
query = "非小细胞肺癌的患者"
documents = [
"玛丽患有肺癌,癌细胞已转移",
"刘某肺癌I期",
"张某经诊断为非小细胞肺癌III期",
"小细胞肺癌是肺癌的一种"
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Cosine distance:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
Cosine distance:
0.891300758103824
0.8897648918974225
0.9040803406710733
0.9132102982983258
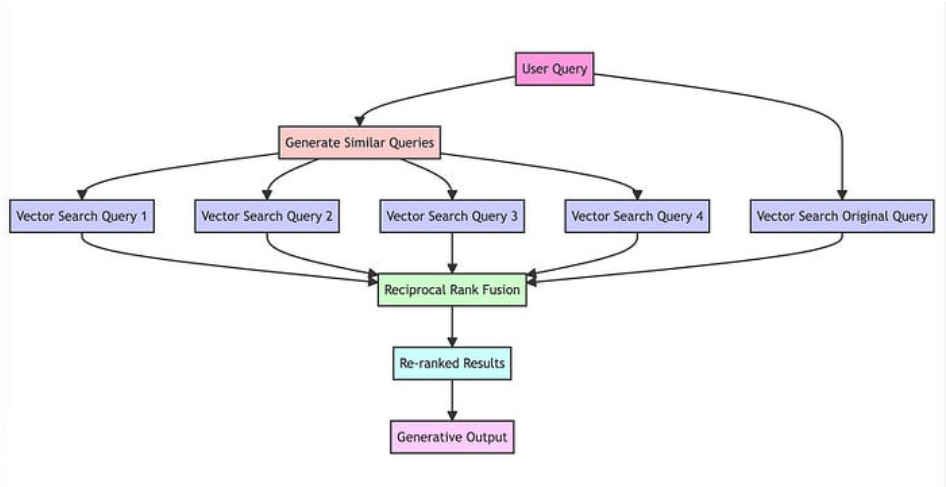
所以,有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
混合检索的核心是,综合文档 d d d 在不同检索算法下的排序名次(rank),为其生成最终排序。
一个最常用的算法叫 Reciprocal Rank Fusion(RRF)
KaTeX parse error: Can't use function '$' in math mode at position 2: $̲rrf(d)=\sum_{a\…
其中
A
A
A 表示所有使用的检索算法的集合,
r
a
n
k
a
(
d
)
rank_a(d)
ranka(d) 表示使用算法
a
a
a 检索时,文档
d
d
d 的排序,
k
k
k 是个常数。
很多向量数据库都支持混合检索,比如 Weaviate、Pinecone 等。也可以根据上述原理自己实现。
RAG-Fusion(选)
RAG-Fusion 就是利用了 RRF 的原理来提升检索的准确性。
向量模型的本地加载与运行
划重点:
- 不是每个 Embedding 模型都对余弦距离和欧氏距离同时有效
- 哪种相似度计算有效要阅读模型的说明(通常都支持余弦距离计算)
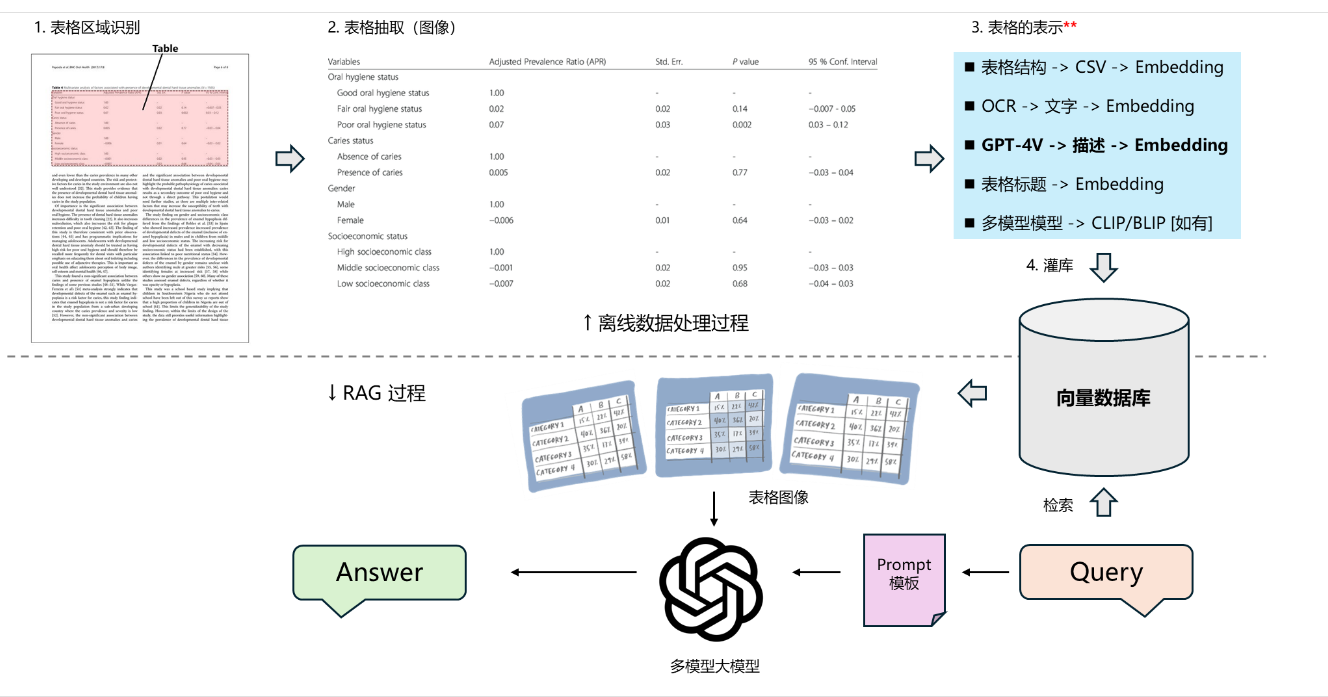
PDF 文档中的表格怎么处理(选)
-
将每页 PDF 转成图片
-
识别文档(图片)中的表格
-
基于 GPT-4 Vision API 做表格问答
-
用 GPT-4 Vision 生成表格(图像)描述,并向量化用于检索
一些面向 RAG 的文档解析辅助工具¶
- PyMuPDF: PDF 文件处理基础库,带有基于规则的表格与图像抽取(不准)
- RAGFlow: 一款基于深度文档理解构建的开源 RAG 引擎,支持多种文档格式
- Unstructured.io: 一个开源+SaaS形式的文档解析库,支持多种文档格式
在工程上,PDF 解析本身是个复杂且琐碎的工作。以上工具都不完美,建议在自己实际场景测试后选择使用。
总结
RAG 的流程
- 离线步骤:
- 文档加载
- 文档切分
- 向量化
- 灌入向量数据库
- 在线步骤:
- 获得用户问题
- 用户问题向量化
- 检索向量数据库
- 将检索结果和用户问题填入 Prompt 模版
- 用最终获得的 Prompt 调用 LLM
- 由 LLM 生成回复
我用了一个开源的 RAG,不好使怎么办?
- 检查预处理效果:文档加载是否正确,切割的是否合理
- 测试检索效果:问题检索回来的文本片段是否包含答案
- 测试大模型能力:给定问题和包含答案文本片段的前提下,大模型能不能正确回答问题















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









