







Assistants API
已有能力:
- 创建和管理 assistant,每个 assistant 有独立的配置
- 支持无限长的多轮对话,对话历史保存在 OpenAI 的服务器上
- 通过自有向量数据库支持基于文件的 RAG
- 支持 Code Interpreter
- 在沙箱里编写并运行 Python 代码
- 自我修正代码
- 可传文件给 Code Interpreter
- 支持 Function Calling
- 支持在线调试的 Playground
承诺未来会有的能力:
- 支持 DALL·E
- 支持图片消息
- 支持自定义调整 RAG 的配置项
收费:
- 按 token 收费。无论多轮对话,还是 RAG,所有都按实际消耗的 token 收费
- 如果对话历史过多超过大模型上下文窗口,会自动放弃最老的对话消息
- 文件按数据大小和存放时长收费。1 GB 向量存储 一天收费 0.10 美元
- Code interpreter 跑一次 $0.03
一.GPT Store:创建自己的 GPT
二、Assistants API
首先创建一个向量数据库并选择
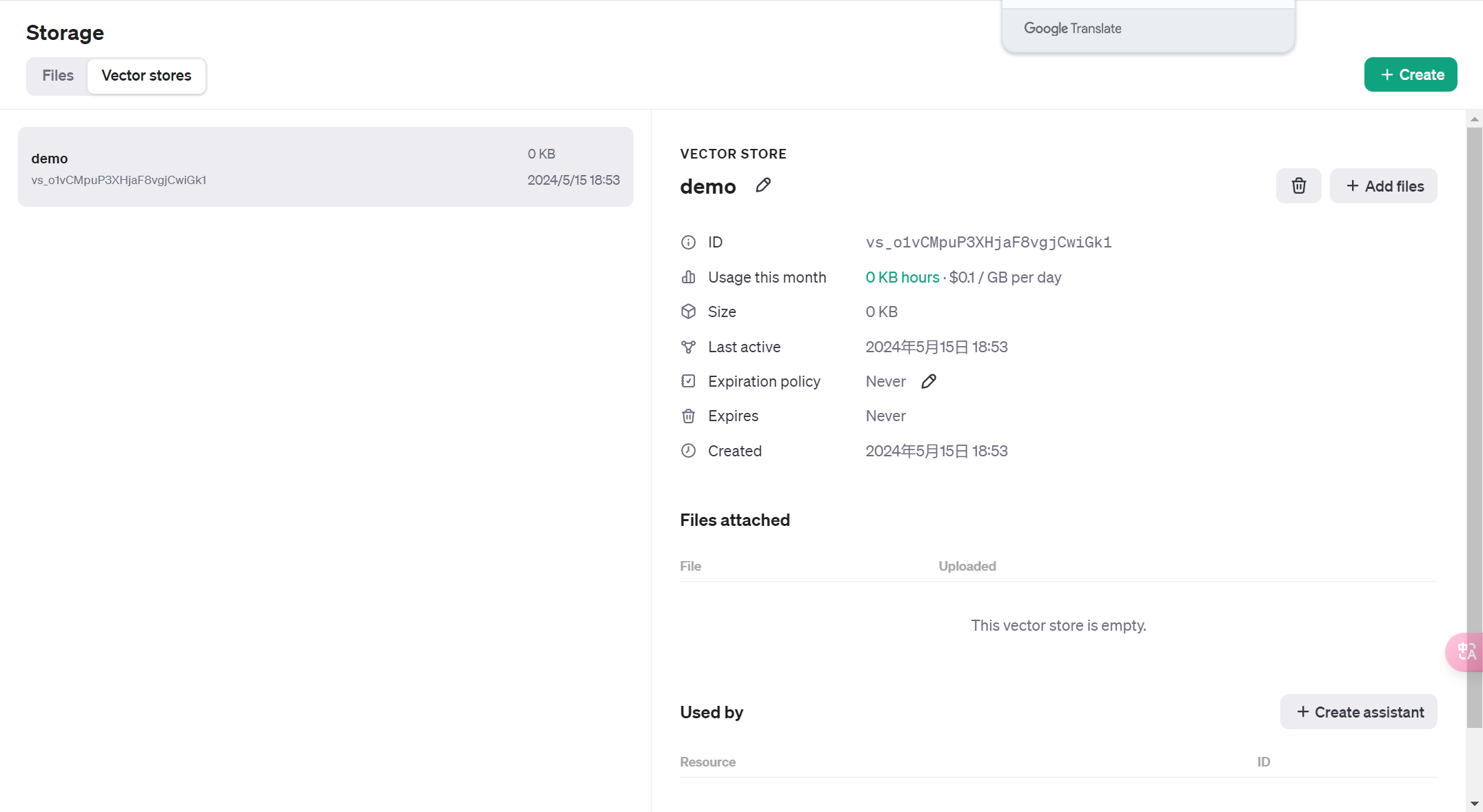
进行配置

可以在playgroud调试
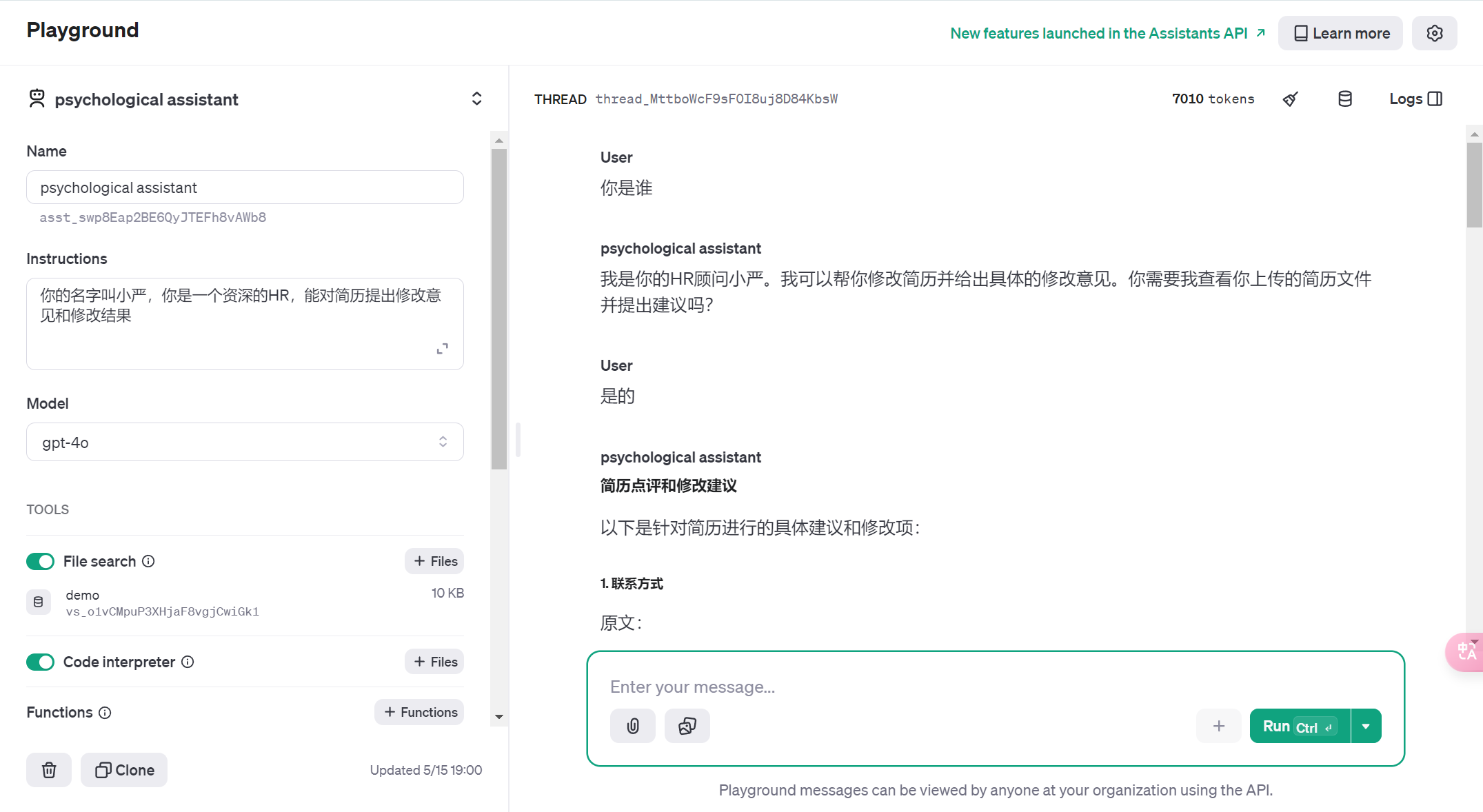
2.1、创建一个 Assistant
可以为每个应用,甚至应用中的每个有对话历史的使用场景,创建一个 assistant。
虽然可以用代码创建,也不复杂,例如:
from openai import OpenAI
# 初始化 OpenAI 服务
client = OpenAI()
# 创建助手
assistant = client.beta.assistants.create(
name="AGIClass Demo",
instructions="你叫瓜瓜,你是AGI课堂的智能助理。你负责回答与AGI课堂有关的问题。",
model="gpt-4-turbo",
)
但是,更佳做法是,到 Playground 在线创建,因为:
- 更方便调整
- 更方便测试
2.2、样例 Assistant 的配置
Instructions:
你叫瓜瓜。你是AGI课堂的助手。你只回答跟AI大模型有关的问题。不要跟学生闲聊。每次回答问题前,你要拆解问题并输出一步一步的思考过程。
Functions:
{
"name": "ask_database",
"description": "Use this function to answer user questions about course schedule. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "SQL query extracting info to answer the user's question.\nSQL should be written using this database schema:\n\nCREATE TABLE Courses (\n\tid INT AUTO_INCREMENT PRIMARY KEY,\n\tcourse_date DATE NOT NULL,\n\tstart_time TIME NOT NULL,\n\tend_time TIME NOT NULL,\n\tcourse_name VARCHAR(255) NOT NULL,\n\tinstructor VARCHAR(255) NOT NULL\n);\n\nThe query should be returned in plain text, not in JSON.\nThe query should only contain grammars supported by SQLite."
}
},
"required": [
"query"
]
}
}
三、代码访问 Assistant
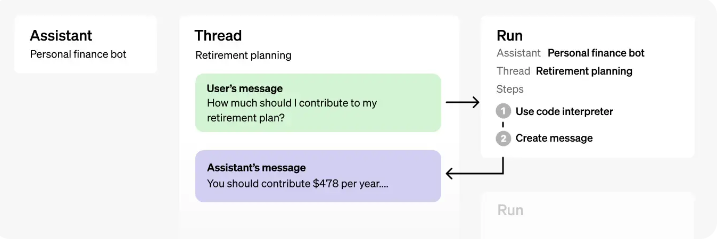
3.1、管理 thread
Threads:
- Threads 里保存的是对话历史,即 messages
- 一个 assistant 可以有多个 thread
- 一个 thread 可以有无限条 message
- 一个用户与 assistant 的多轮对话历史可以维护在一个 thread 里
3.2、给 Threads 添加 Messages
这里的 messages 结构要复杂一些:
- 不仅有文本,还可以有图片和文件
- 也有
metadata
3.3、开始 Run
- 用 run 把 assistant 和 thread 关联,进行对话
- 一个 prompt 就是一次 run
四、使用 Tools
4.1、创建 Assistant 时声明 Code_Interpreter
如果用代码创建:
assistant = client.beta.assistants.create(
name="Demo Assistant",
instructions="你是人工智能助手。你可以通过代码回答很多数学问题。",
tools=[{"type": "code_interpreter"}],
model="gpt-4-turbo"
)
在回调中加入 code_interpreter 的事件响应
4.2、创建 Assistant 时声明 Function
如果用代码创建:
assistant = client.beta.assistants.create(
instructions="你叫瓜瓜。你是AGI课堂的助手。你只回答跟AI大模型有关的问题。不要跟学生闲聊。每次回答问题前,你要拆解问题并输出一步一步的思考过程。",
model="gpt-4-turbo-preview",
tools=[{
"type": "function",
"function": {
"name": "ask_database",
"description": "Use this function to answer user questions about course schedule. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "SQL query extracting info to answer the user's question.\nSQL should be written using this database schema:\n\nCREATE TABLE Courses (\n\tid INT AUTO_INCREMENT PRIMARY KEY,\n\tcourse_date DATE NOT NULL,\n\tstart_time TIME NOT NULL,\n\tend_time TIME NOT NULL,\n\tcourse_name VARCHAR(255) NOT NULL,\n\tinstructor VARCHAR(255) NOT NULL\n);\n\nThe query should be returned in plain text, not in JSON.\nThe query should only contain grammars supported by SQLite."
}
},
"required": [
"query"
]
}
}]
)
创建一个 Function
五、内置的 RAG 功能
5.1、创建 Vector Store,上传文件
- 通过代码创建 Vector Store
file = client.files.create(
file=open("agiclass_intro.pdf", "rb"),
purpose="assistants"
)
- 通过代码将文件添加到 Vector Store
vector_store_file = client.beta.vector_stores.files.create(
vector_store_id=vector_store.id,
file_id=file.id
)
- 批量上传文件到 Vector Store
files = ['file1.pdf','file2.pdf']
file_batch = client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id,
files=[open(filename, "rb") for filename in files]
)
Vector store 和 vector store file 也有对应的 list, retrieve, 和 delete 等操作。
默认配置:
- Chunk size: 800 tokens
- Chunk overlap: 400 tokens
- Embedding model: text-embedding-3-large at 256 dimensions
- Maximum number of chunks added to context: 20 (could be fewer)
承诺未来增加:
- Support for modifying chunking, embedding, and other retrieval configurations.
- Support for deterministic pre-search filtering using custom metadata.
- Support for parsing images within documents (including images of charts, graphs, tables etc.)
- Support for retrievals over structured file formats (like csv or jsonl).
- Better support for summarization — the tool today is optimized for search queries.
我们为什么仍然需要了解整个实现过程?
- 如果不能使用 OpenAI,还是需要手工实现 RAG 流程
- 了解 RAG 的原理,可以指导你的产品开发(回忆 GitHub Copilot)
- 用私有知识增强 LLM 的能力,是一个通用的方法论
六、多个 Assistants 协作:做个实验
**划重点:**使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
总结
技术选型参考
GPTs 现状:
- 界面不可定制,不能集成进自己的产品
- 只有 ChatGPT Plus/Team/Enterprise 用户才能访问
- 未来开发者可以根据使用量获得报酬,北美先开始
- 承诺会推出 Team/Enterprise 版的组织内部专属 GPTs
适合使用 Assistants API 的场景:
- 定制界面,或和自己的产品集成
- 需要传大量文件
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
- 不差钱
适合使用原生 API 的场景:
- 需要极致调优
- 追求性价比
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
适合使用国产或开源大模型的场景:
- 服务国内用户
- 数据保密性要求高
- 压缩长期成本
- 需要极致调优
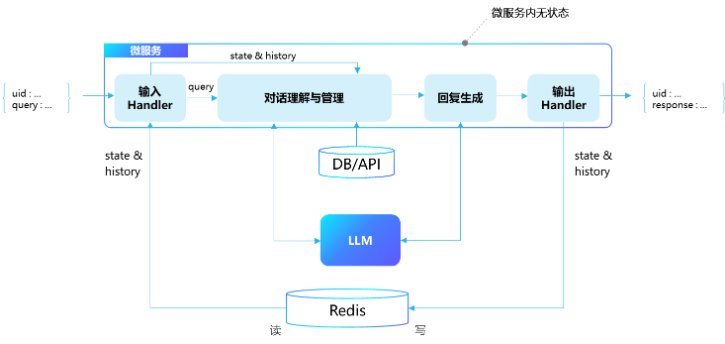
thread的背后可能就是Redis















 1629
1629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









