







项目地址:chats-crawler
Discourse 类型论坛网站的对话数据爬取和解析,以直接用于大型语言模型(LLM)指令微调。数据包括文本、图片(多模态指令微调)和链接。不久将支持更多聊天对话网站。快速开始
运行
git clone https://github.com/jackfsuia/chats-crawler.git
然后运行下面命令安装依赖
npm i
在开始爬取之前,请务必阅读下面的注意事项。
注意事项!!!
请确保此爬取是合法的,如果你不确定,请检查目标网站的robots.txt和其他相关法律信息源。项目不承担由此产生的任何法律风险和问题。
在config.ts配置目标网站,编辑url和rex属性以满足你的需求, 把其中的两个https://discuss.pytorch.org替换为您的目标网站。目标网站必须是基于Discourse构建的。 Discourse构建的网站基本都长下面这样:
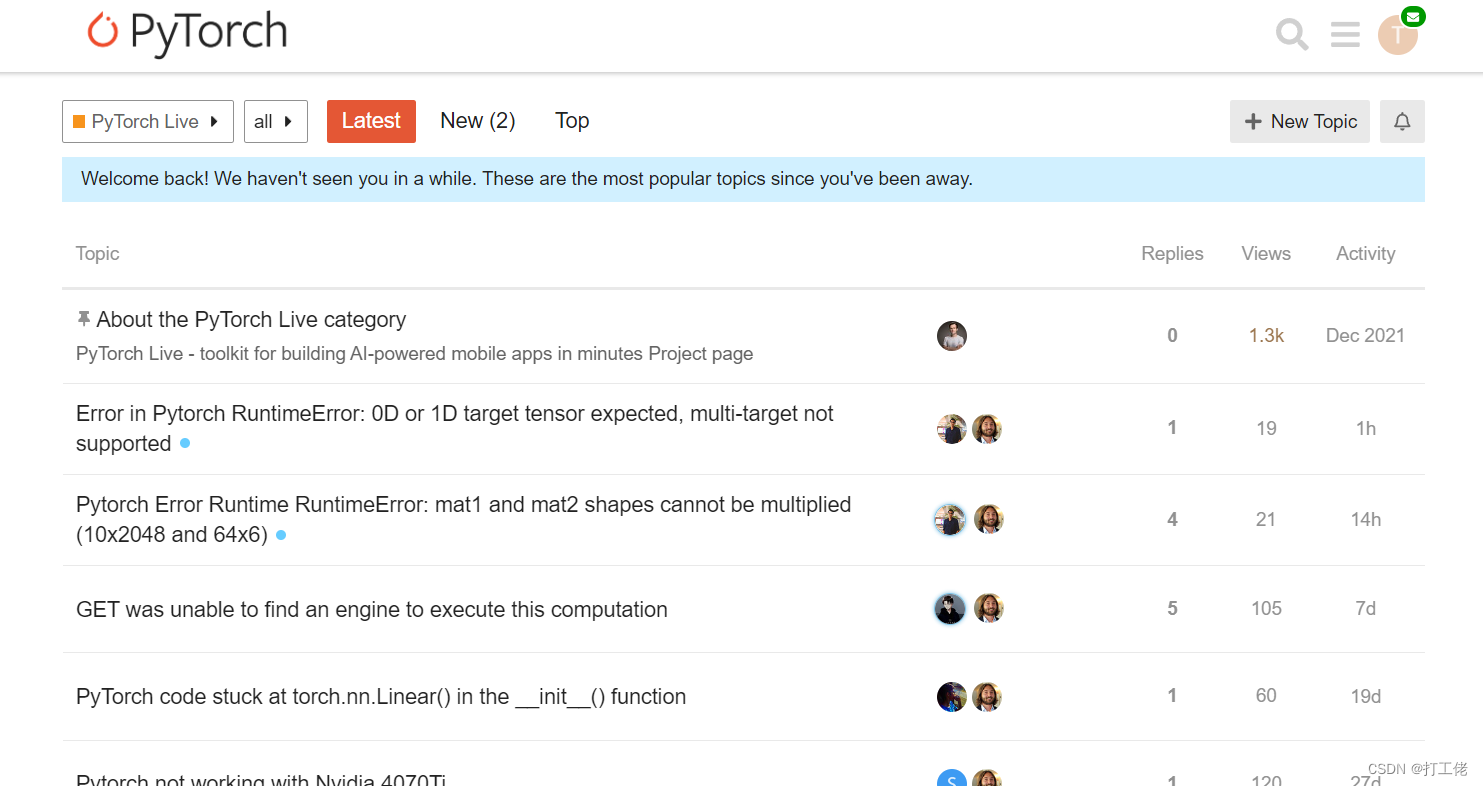
运行下面命令开始爬取和解析
npm start
大功告成! 一条条的对话数据会分别作为json文件保存在 storage/datasets/default , 其中的图片保存在 storage/datasets/imgs.
示例
比如想爬取https://discuss.pytorch.org网站. 修改config.ts文件的两个地方:
...
url: "https://discuss.pytorch.org/",
...
rex: "https://discuss.pytorch.org/t/[^/]+/[0-9]+$",
可能我们中途会爬到类似下面的网站
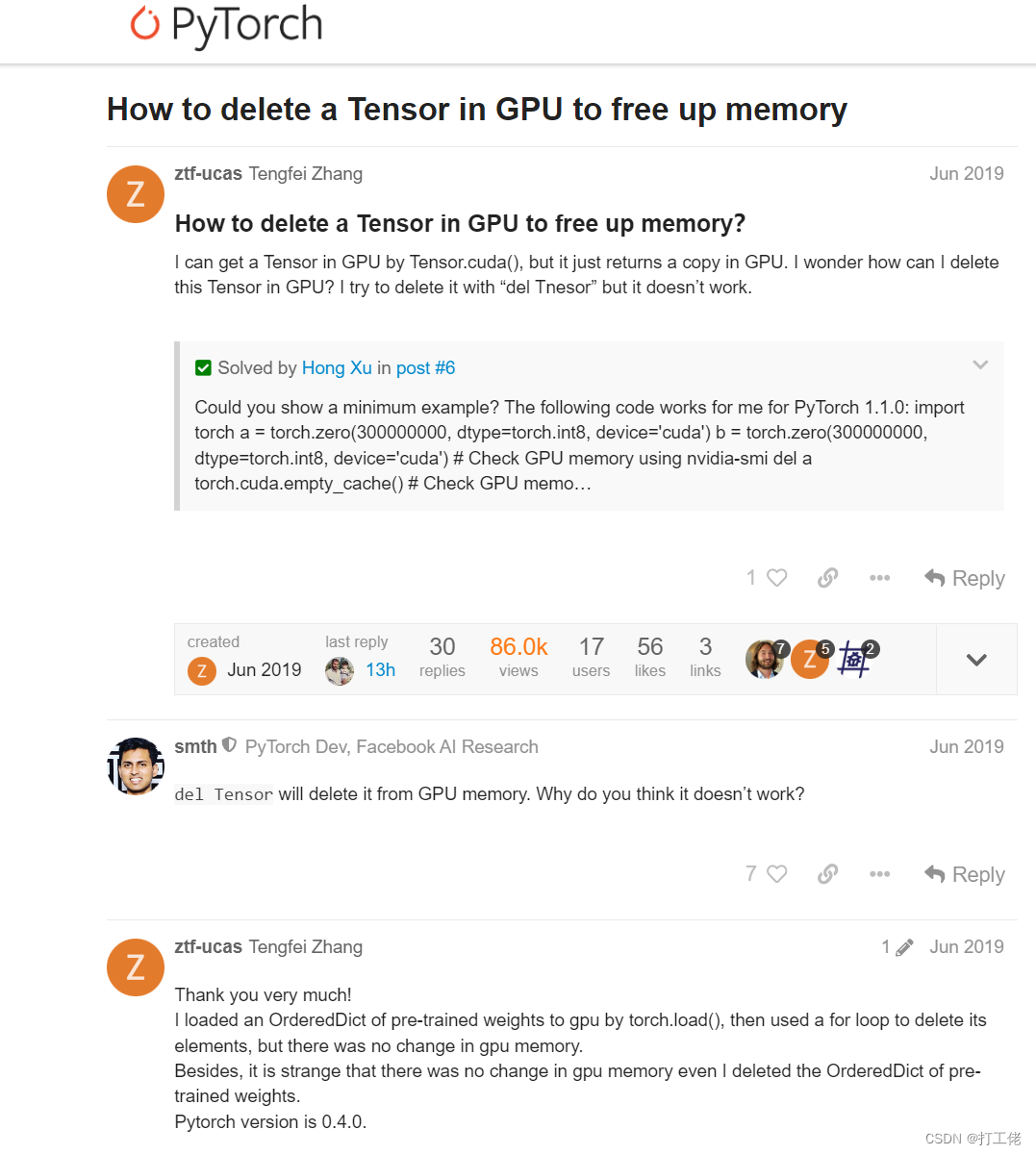
然后得到的相应json文件里的"conversations"内容应该是
<# ztf-ucasTengfei Zhang #>:
How to delete a Tensor in GPU to free up memory?
I can get a Tensor in GPU by Tensor.cuda(), but it just returns a copy in GPU. I wonder how can I delete this Tensor in GPU? I try to delete it with “del Tnesor” but it doesn’t work.
Quote:"
Could you show a minimum example? The following code works for me for PyTorch 1.1.0:
import torch
a = torch.zero(300000000, dtype=torch.int8, device='cuda')
b = torch.zero(300000000, dtype=torch.int8, device='cuda')
# Check GPU memory using nvidia-smi
del a
torch.cuda.empty_cache()
# Check GPU memo…
"
<# smth #>:
del Tensor will delete it from GPU memory. Why do you think it doesn’t work?
<# ztf-ucasTengfei Zhang #>:
Thank you very much!
I loaded an OrderedDict of pre-trained weights to gpu by torch.load(), then used a for loop to delete its elements, but there was no change in gpu memory.
Besides, it is strange that there was no change in gpu memory even I deleted the OrderedDict of pre-trained weights.
Pytorch version is 0.4.0.2
...
其中<# ztf-ucasTengfei Zhang #>和<# smth #>是两位帖主的用户名, 自行把其分别替换成一般大模型指令模板里的<user>和<assistant>即可直接用于指令微调。对话里包含的图片都会下载保存在storage/datasets/imgs, 并且对话里会把相应的图片位置替换成[img 图片名]。对话里的链接会[link 链接] 。其他无关元素被完全过滤掉。
觉得有用的话,给我们仓库点颗星呗 ⭐️ ,谢谢~~
未来工作
- 将支持图片数据OCR成文本,插入原始对话流中。
许可证
chats-crawler许可证文件是MIT许可证。
致谢
本项目基于gpt-crawler和crawlee。感谢他们的工作。

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









