






一、框架的选择
这里我主要用的scrapy框架和Beautiful Soup工具,爬取的网址是39医生中文网,这里就不再对爬虫的使用技巧进行说明了,因为我本人有很多爬虫项目的经验,所以在这方面也是比较得心应手。

主要是通过如下代码,通过解析网页内容提取出相应的问题与答案。
39医生的爬取难度还是比较低的比起我以前做的许多爬虫项目而言,它的反爬机制较少。
我们爬取下来数据后,保存到相应的csv文件,我们可以看看我们爬取的一些结果。

二、一些反爬应对手段
如果担心说我们的爬取可能导致IP封禁等问题,这里我没有仔细研究39医生中文网有没有IP封禁问题,我们可以直接构造我们的IP池进行反爬虫应对。
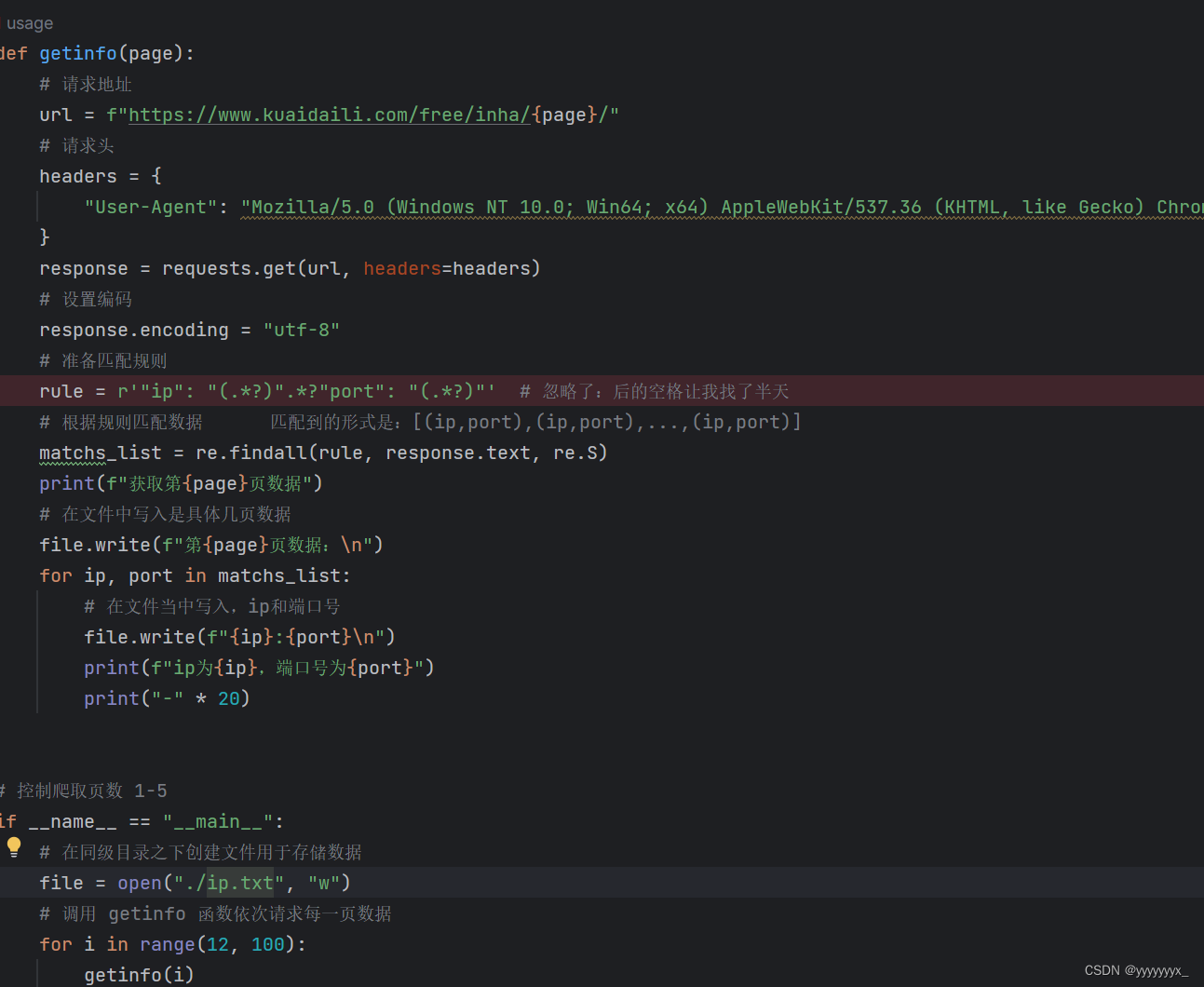
这里我们应用request模块,可以很容易的爬到一些代理IP然后存储起来,作为我们的代理IP。















 2747
2747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









