










协同过滤算法
推荐系统构建三大方法:基于内容的推荐content-based,协同过滤collaborative filtering,隐语义模型(LFM, latent factor model)推荐。这篇博客主要讲协同过滤。
——《推荐系统:协同过滤collaborative filtering》
协同过滤(CF, Collaborative Filtering)的主要思想是:利用已有的用户群过去的行为或者意见预测当前用户最可能喜欢哪些东西或者对哪些东西感兴趣。主要应用场景是在线零售系统,目的是进行商品促销和提高销售额。
——《协同过滤》
协同过滤(Collaborative Filtering, CF) 是一种非常经典的推荐系统算法,其完全由统计学出发,挖掘用户与物品之间的相关性。协同过滤顾名思义,先协同,即寻找相似的用户或物品,再过滤,即筛选出符合条件的内容。
在推荐系统中,主要有两个主体,包括 用户(User) 和 物品(Item) ,协同过滤也因此分为用户协同过滤(UserCF) 和 物品协同过滤(ItemCF) 。简单的罗列描述如下:
- 用户协同过滤:是指根据相似性的用户进行推荐。具体地讲,当为某一个用户 A A A 进行推荐相关物品时,先根据这个用户的交互历史,与其他所有用户计算相似度,获得一定数量的最相似的用户 B B B ,其次根据这些用户所交互过的物品获得候选的物品列表,最后将这些物品推荐给用户 A A A 。
- 物品协同过滤:是指根据相似性的物品为用户进行推荐。具体地讲,首先获得某个用户 A A A 的正反馈列表(即该用户对于所有持正反馈交互的物品集合),其次根据正反馈列表中的每一个物品与其他物品计算相似度,并获取一定数量的物品,最终将这些物品进行排序,形成推荐列表。
1、共现矩阵
给定一组用户 U = { u 1 , u 2 , . . . , u m } U=\{u_1, u_2, ..., u_m\} U={u1,u2,...,um} 和一组物品 P = { p 1 , p 2 , . . . , p n } P=\{p_1, p_2, ..., p_n\} P={p1,p2,...,pn} ,其中 m , n m, n m,n 分别表示用户和物品的数量。推荐系统的前提是获取用户与物品的交互数据,因此即需要获得用户集合 U U U 中每个用户 u ∈ U u\in U u∈U 与物品集合中 P P P 中,每个物品之间的交互关系,因此这属于一个典型的二分图结构。图中,包含两类不同的结点,分别表示用户和物品,图中边的两端结点类型不同,边表示用户与物品之间存在交互历史,边上的权值则可以表示评价(正反馈,或打分等)。因此可以选择共现矩阵进行存储。
共现矩阵是描述用户与物品之间交互的矩阵,一般地,行表示某个用户与所有物品的交互数据,列表示某个物品与所有用户的交互数据。相比邻接矩阵而言,其可用于存储二分图。
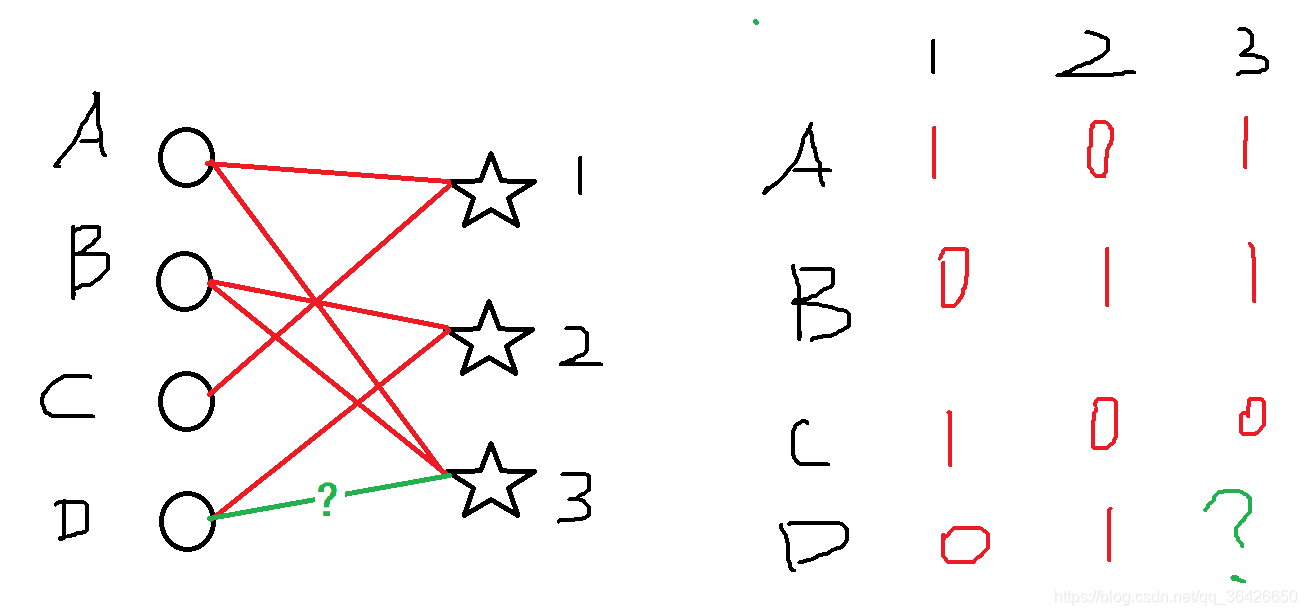
例1: 给定三个用户 { A , B , C } \{A, B, C\} {A,B,C} 和三个物品 { 1 , 2 , 3 } \{1, 2, 3\} {1,2,3} ,假设存在一定的交互数据(左侧为二分图,1表示存在交互,0表示不存在交互),则可以转化为共现矩阵表示(右侧图)。
当新来一个用户 D D D, 其只与2号物品有过交互,推荐系统的目标则是为这个用户推荐其他没有交互过的物品,例如预测图中的绿色边是否存在。
本文中,共现矩阵记做 R = [ R u p ] R=[R_{up}] R=[Rup] 表示第 u u u 个用户对物品 p p p 的得分。其可以表示为 R = [ R 1 u , R 2 u , . . . , R m u ] T R = [R_1^u, R_2^u, ..., R_m^u]^T R=[R1u,R2u,...,Rmu]T,其中 R i u R_i^u Riu 表示第 i i i 个用户向量;也可以表示为 R = [ R 1 p , R 2 p , . . . , R n p ] R = [R_1^p, R_2^p, ..., R_n^p] R=[R1p,R2p,...,Rnp], 其中 R j p R_j^p Rjp 表示第 j j j 个物品的向量。
2、相似度
根据上面的描述,可知协同过滤中非常重要的部分是计算相似度。一般地,常见的相似度量函数有:
- 余弦相似度:给定两个向量 i \mathbf{i} i 和 j \mathbf{j} j,则有 s i m ( i , j ) = i ⋅ j ∣ ∣ i ∣ ∣ ⋅ ∣ ∣ j ∣ ∣ sim(\mathbf{i}, \mathbf{j}) = \frac{\mathbf{i}\cdot\mathbf{j}}{||\mathbf{i}||\cdot ||\mathbf{j}||} sim(i,j)=∣∣i∣∣⋅∣∣j∣∣i⋅j 。
- 皮尔逊相关系数:
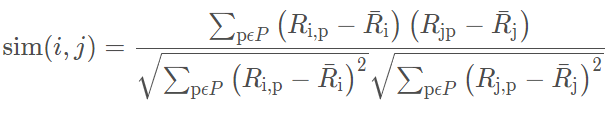
皮尔逊相关系数本质上就是对共现矩阵的归一化后任意两个用户之间的协方差,当协方差值越大,则说明相关度越大。其中 R i p R_{ip} Rip 表示用户 i i i 对物品 p p p 的打分, R i ‾ \overline{R_i} Ri 则表示用户 i i i 对所有物品打分的均值。 - 杰卡德相似度:通常适合集合,在共现矩阵中,可以对每个用户表示具有交互的物品集合,因此可以使用集合的相似度,记做
s i m ( i , j ) = ∣ ∣ u i ∩ u j ∣ ∣ ∣ ∣ u i ∪ u j ∣ ∣ sim(i,j) = \frac{||u_i\cap u_j||}{||u_i\cup u_j||} sim(i,j)=∣∣ui∪uj∣∣∣∣ui∩uj∣∣
有了相似度函数,则可以进行协同过滤。
2、用户协同过滤
给定一个共现矩阵 R = [ R u p ] R=[R_{up}] R=[Rup] 表示第 u u u 个用户对物品 p p p 的得分。用户协同过滤的目标是计算每个用户之间的相似度,并将TopK相似度最高的用户对于的物品推荐给用户。具体流程如下:
- 给定一个用户 u u u,选择相应的相似度函数,计算其与其他所有用户 s s s 之间的相似度 w u s = s i m ( u , s ) w_{us} = sim(u, s) wus=sim(u,s);
- 对所有相似度进行由高到低排序,并获取TopK个最相似的用户集合,记做 S = { s 1 , s 2 , . . . , s K } S=\{s_1, s_2, ..., s_K\} S={s1,s2,...,sK};
- 根据这TopK个用户的反馈物品数据,分别预测该用户
u
u
u 对每个物品
p
p
p 的评价得分,公式为:
R u p = ∑ s ∈ S ( w u s ⋅ R s p ) ∑ s ∈ S w u s R_{up} = \frac{\sum_{s\in S}(w_{us}\cdot R_{sp})}{\sum_{s\in S}w_{us}} Rup=∑s∈Swus∑s∈S(wus⋅Rsp)
直观理解为,每个用户 s ∈ S s\in S s∈S 与 u u u 的相似度与 s s s 为 p p p 的得分的乘积的和的期望作为评价的预测。
例2: 假设例1中的共现矩阵中的元素表示用户为物品的打分,试预测用户 D D D 与物品 3 3 3 的打分。
- 用户 D D D 可以初始化表示为向量 [ 0 , 1 , 0 ] [0, 1, 0] [0,1,0],并选择余弦相似度与其他3个用户计算相似度,计算得分分别为 s i m ( D , A ) = 0 , s i m ( D , B ) = 1 2 , s i m ( D , C ) = 0 sim(D, A) = 0, sim(D, B) = \frac{1}{\sqrt{2}}, sim(D, C) = 0 sim(D,A)=0,sim(D,B)=21,sim(D,C)=0,发现用户 B B B 最为相似;
- 取 B B B 用户所有反馈物品 2 , 3 2, 3 2,3, 2 2 2 已经与用户 D D D 有过交互,则只需要计算物品 3 3 3 的预测值。代入式子得到 R D 3 = 1 R_{D3} = 1 RD3=1;
- 因此,预测结果为1。
用户协同过滤存在两个不足之处:
(1)通常用户数远远大于物品数,因此寻找相似用户的计算量会非常大;
(2)用户的历史数据向量往往非常稀疏。
3、物品协同过滤
物品协同过滤是基于物品进行推荐的协同过滤算法。通过共现矩阵中物品列向量的相似度得到物品之间相似矩阵。再找到用户的历史正反馈物品的相似物品进行一步排序和推荐,物品协同过滤具体过程:
- 给定一个用户 p p p,选择相应的相似度函数,计算其与其他所有用户 h h h 之间的相似度 w p h = s i m ( p , h ) w_{ph} = sim(p, h) wph=sim(p,h);
- 获得当前用户的正反馈物品列表;
- 针对用户的正反馈物品,找出相似的TopK个物品,组成相似物品集合, H = { h 1 , h 2 , . . . , h K } H=\{h_1, h_2, ..., h_K\} H={h1,h2,...,hK};
- 对相似物品集合中的物品,利用相似度分值进行排序,生成最终的推荐列表;相似度分值计算为:
R u p = ∑ h ∈ H ( w p h ⋅ w u h ) R_{up} = \sum_{h\in H}(w_{ph}\cdot w_{uh}) Rup=h∈H∑(wph⋅wuh)
4、协同过滤总结
(1)用户协同过滤(UserCF)是基于用户相似度进行推荐的,用户可以快速地了解与自己相似的其他用户的偏好。UserCF更适用于发现热点,跟踪热点的趋势;
(2)基于物品协同过滤(ItemCF)是基于物品相似度进行推荐的,用户在某一段内更倾向于寻找一类商品,根据用户偏好的物品来寻找与之相似的物品进行推荐,更加契合用户动机。
(3)协同过滤算法具有可解释性,但不具有泛化能力。
(4)协同过滤不能处理长尾效应以及稀疏性的数据;
(5)协同过滤只对用户-物品的交互数据进行分析,无法有效引入其他信息,例如用户信息、物品信息等
转载请注明出处:https://blog.csdn.net/qq_36426650/article/details/113956490,更多文章请访问并关注:https://blog.csdn.net/qq_36426650 。


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











