










论文解读:Spelling Error Correction with Soft-Masked BERT(2020ACL)
拼写错误纠错是一个比较重要且挑战的任务,非常依赖于人类的语言理解能力。本文关注中文的拼写错误纠错任务(Chinese Spelling Error Correction)。目前SOTA的方法是给予BERT模型,为句子中的每一个词,从候选的字符列表中挑选一个作为纠错的结果,然而这类方法容易陷入局部最优。然而,因为 BERT 没有足够的能力来检测每个位置是否有错误,显然是由于使用掩码语言建模对其进行预训练的方式。、
本文解决上述提到的问题,提出一种基于BERT端到端的新方法,包括error detection network和error correction network,这两个模块前后之间通过我们提出的soft-masking technique。
Our method of using ‘Soft-Masked BERT’ is general, and it may be employed in other language detection- correction problems.
拼写错误纠错任务可以用于搜索、OCR识别等下游任务中,本文关注与字符级别的纠错任务。
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | SoftMasked BERT |
| 2 | 所属领域 | 自然语言处理、中文拼写检测 |
| 3 | 研究内容 | 预训练语言模型 |
| 4 | 核心内容 | BERT应用 |
| 5 | GitHub源码 | https://github.com/hiyoung123/SoftMaskedBert |
| 6 | 论文PDF | https://aclanthology.org/2020.acl-main.82.pdf |
一、挑战:
- 世界知识(World Knowledge)需要应用到拼写错误纠错上;
- 需要一定的推理(Inference)
二、相关工作与动机:
- 先前的拼写错误纠错方法可以分为传统的机器学习方法和深度学习方法:
- BERT目前常用于拼写检错上,但是其错误检测能力还不够好。作者认为可能Masked Langauge Model模型只有15%的字符被mask,因此其可能只学习到mask的分布情况,并不会尝试进行纠错。
the way of pre-training BERT with mask language modeling in which only about 15% of the characters in the text are masked, and thus it only learns the distribution of masked tokens and tends to choose not to make any correction.
本文提出Soft-Masked BERT,包括detection network和correction network:
- detection network:使用Bi-GRU用于预测每个位置的字符是否存在错误;概率则作为soft-masking
- correction network:使用BERT预测纠正的词的概率;
soft-masking是hard-masking的一种拓展:
- hard-masking,0/1向量,0表示不纠错,1表示纠错;
- soft-masking:小数,每个位置的字符代表一个embedding向量,并喂入correction network中
三、方法
Soft-Masked BERT is composed of a detection network based on Bi-GRU and a correction network based on BERT. The detection network predicts the probabilities of errors and the correction network predicts the probabilities of error corrections, while the former passes its prediction results to the latter using soft masking.
模型架构如下图所示:
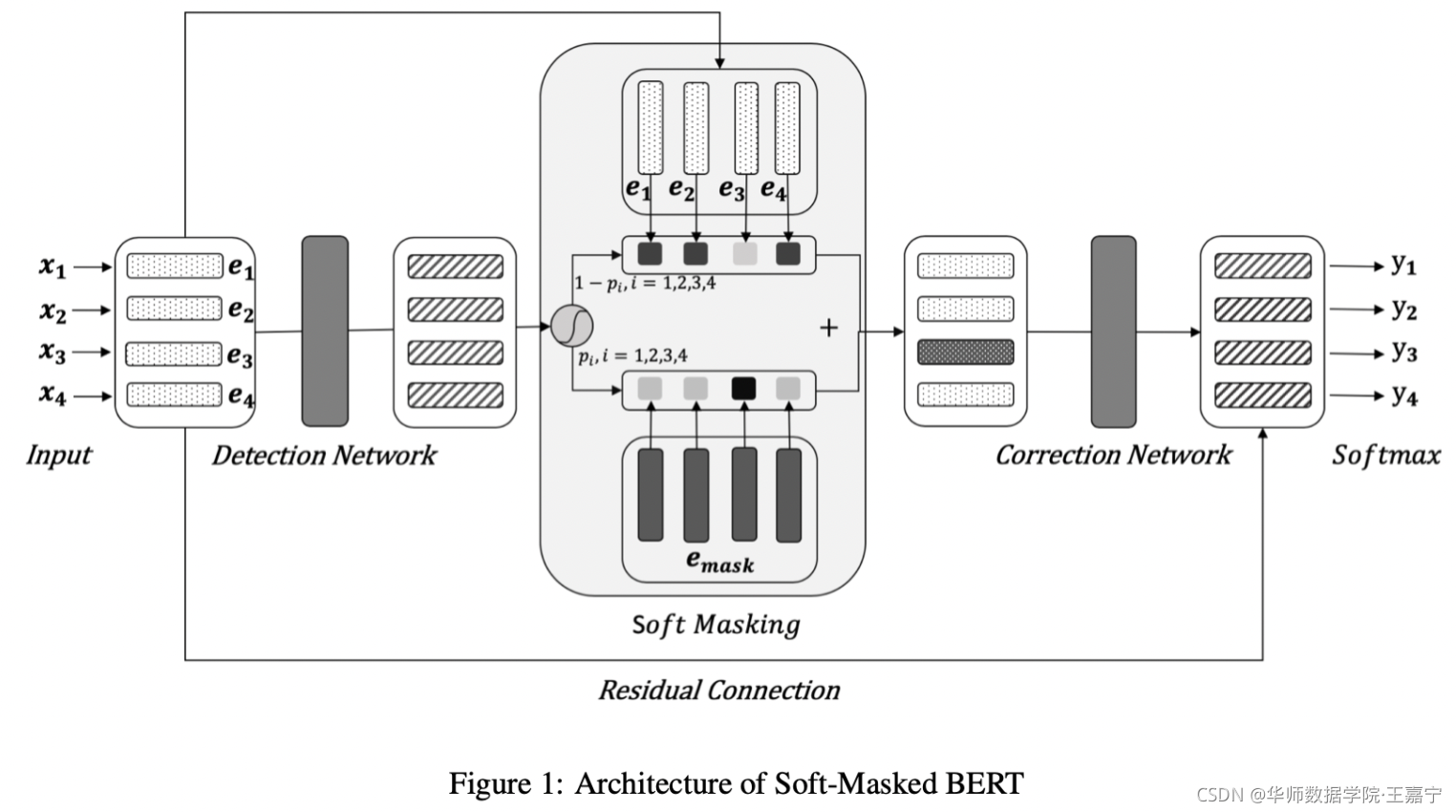
Detection Network
- 输入每个token,每个token的input embedding为word embedding、position embedding以及segment embedding,经过双向GRU网路,每个位置将会输出一个二分类标签(1表示该token是错的,0表示正确),并输出对应的标签为1的概率(即存在错误的概率)
- soft masking:对input embedding和mask embedding进行加权求和:
e i ′ = p i ⋅ e m a s k + ( 1 − p i ) ⋅ e i e_i' = p_i\cdot e_{mask} + (1 - p_i)\cdot e_i ei′=pi⋅emask+(1−pi)⋅ei
最终获得的 e i ′ e_i' ei′ 表示每个位置的soft masking embebding。
Correction Network
-
输入soft masking emebdding,喂入到BERT的Masked Langauge Modeling模型中
其中 p i p_i pi 是该位置是错误的概率,得到最后一层的隐向量,同时通过残差连接方法与input embedding进行结合:
h i ′ = h i c + e i h_i' = h_i^c + e_i hi′=hic+ei -
每个位置的token进行多类分类,得到纠错后的结果。
learning -
训练目标:detection network和correction network分别对应loss function:
L d = − ∑ i = 1 n log P d ( g i ∣ X ) \mathcal{L}_d = - \sum_{i=1}^{n}\log P_d(g_i|X) Ld=−i=1∑nlogPd(gi∣X)
L c = − ∑ i = 1 n log P c ( y i ∣ X ) \mathcal{L}_c = - \sum_{i=1}^{n}\log P_c(y_i|X) Lc=−i=1∑nlogPc(yi∣X)
最后两者线性相加,得到总体的训练损失:
L
=
λ
⋅
L
c
+
(
1
−
λ
)
⋅
L
d
\mathcal{L} = \lambda\cdot\mathcal{L}_c + (1-\lambda)\cdot\mathcal{L}_d
L=λ⋅Lc+(1−λ)⋅Ld
四、实验:
4.1 数据集
- SIGHAN:1100texts、461种错误;
- News Title:15730texts,其中5423texts存在错误,一共3441种类型错误
训练集:在中文新闻app上爬取5,000,000左右新闻title,并为每个字符根据发音(homophonous)构建来confusion table。
We also created a confusion table in which each character is associated with a number of homophonous characters as potential errors.
随机将15%的token替换为其他错误的token,所有替换中的80%来自于对应的confusion table,20%则来自于其他任意的token。作者认为中文的80%的拼写错误都是来自于发音问题。
4.2 Baseline:
- NTOU:词袋模型+分类器;
- NCTU-NTUT:词向量+CRF
- HanSpeller++:隐马尔可夫模型+重排序;
- Hybrid:BiLSTM;
- Confusionset:指针网络+copy机制;
- FASpell:BERT+seq2seq模型;
- BERT-Pretrain:直接使用预训练BERT;
- BERT-Finetune:使用finetune bert
4.3 评价指标:
sentence-level accuracy、precision、recall、F1
4.4 预训练
对于BERT模型,先在5,000,000个语料上进行微调,再在SIGHAN的训练集上微调。
we first fine-tuned the model with the 5 million training examples and then contin- ued the fine-tuning with the training examples in SIGHAN.
4.5 实验结果
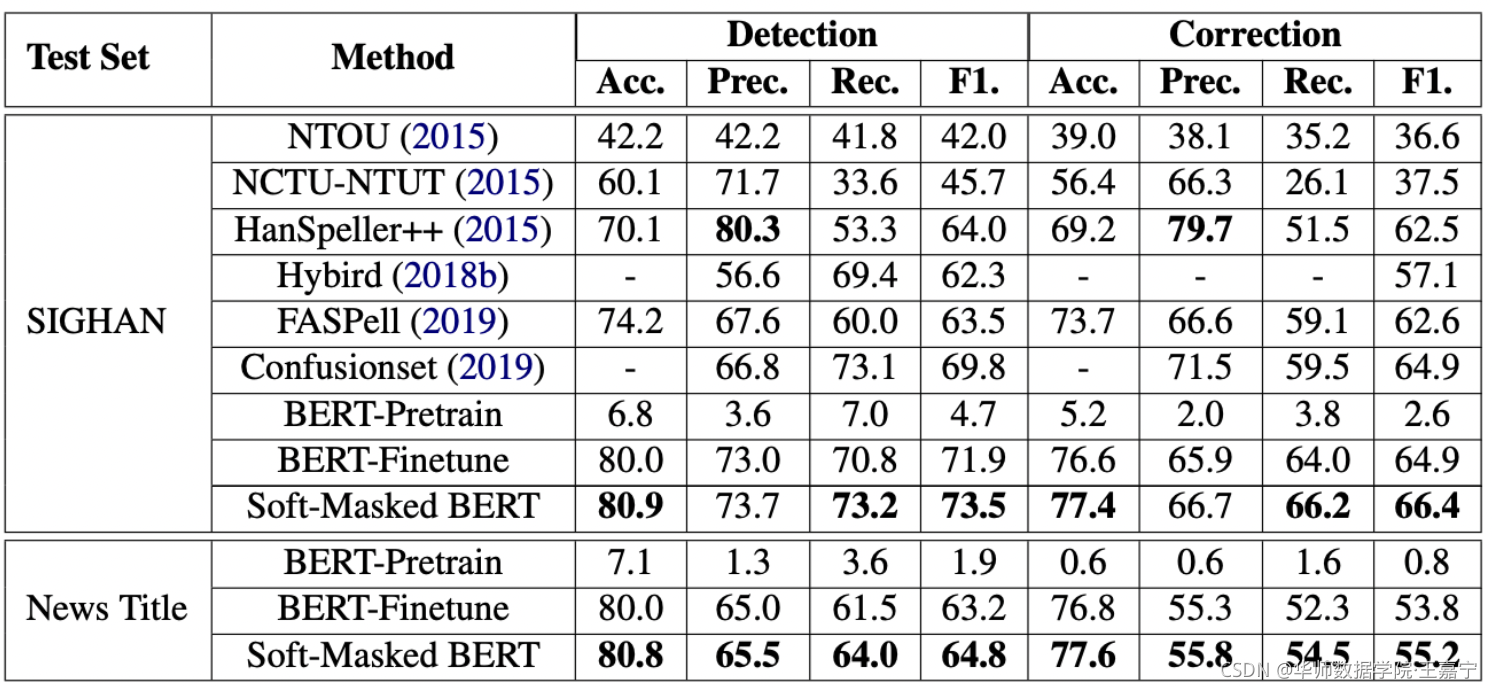
改进点
- 需要推理:上下文语境;
- 需要常识知识:一些领域词的预测错误;


















 7043
7043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











