







目录
📝论文下载地址
🔨代码下载地址
👨🎓论文作者
📦模型讲解
[论文解读]
在本文中,作者提出了一种针对红外和可见光图像融合问题的新型深度学习体系结构。与传统的卷积网络相比,编码网络与卷积层,融合层和密集块相结合,其中每一层的输出彼此相连。 作者尝试使用此体系结构在编码过程中从源图像中获取更多有用的feature,并设计了两个融合层(融合策略)以融合feature。 最后,通过解码器重建融合图像。与现有融合方法相比,该融合方法在客观和主观评估方面均达到了最新水平。
[网络结构]
输入的红外图像和可见图像(灰度图像)表示为 I 1 , . . . , I k I_1,...,I_k I1,...,Ik且k≥2。 请注意,输入图像已预先配准对齐。 索引 ( 1 , . . . , k ) (1,...,k) (1,...,k)与输入图像的类型无关,这意味着 I i I_i Ii ( i = 1 , . . . , k ) (i = 1,...,k) (i=1,...,k)可以视为红外图像或可见图像。网络架构包含三个部分:编码器,融合层和解码器。 所建议的网络架构如下图所示。
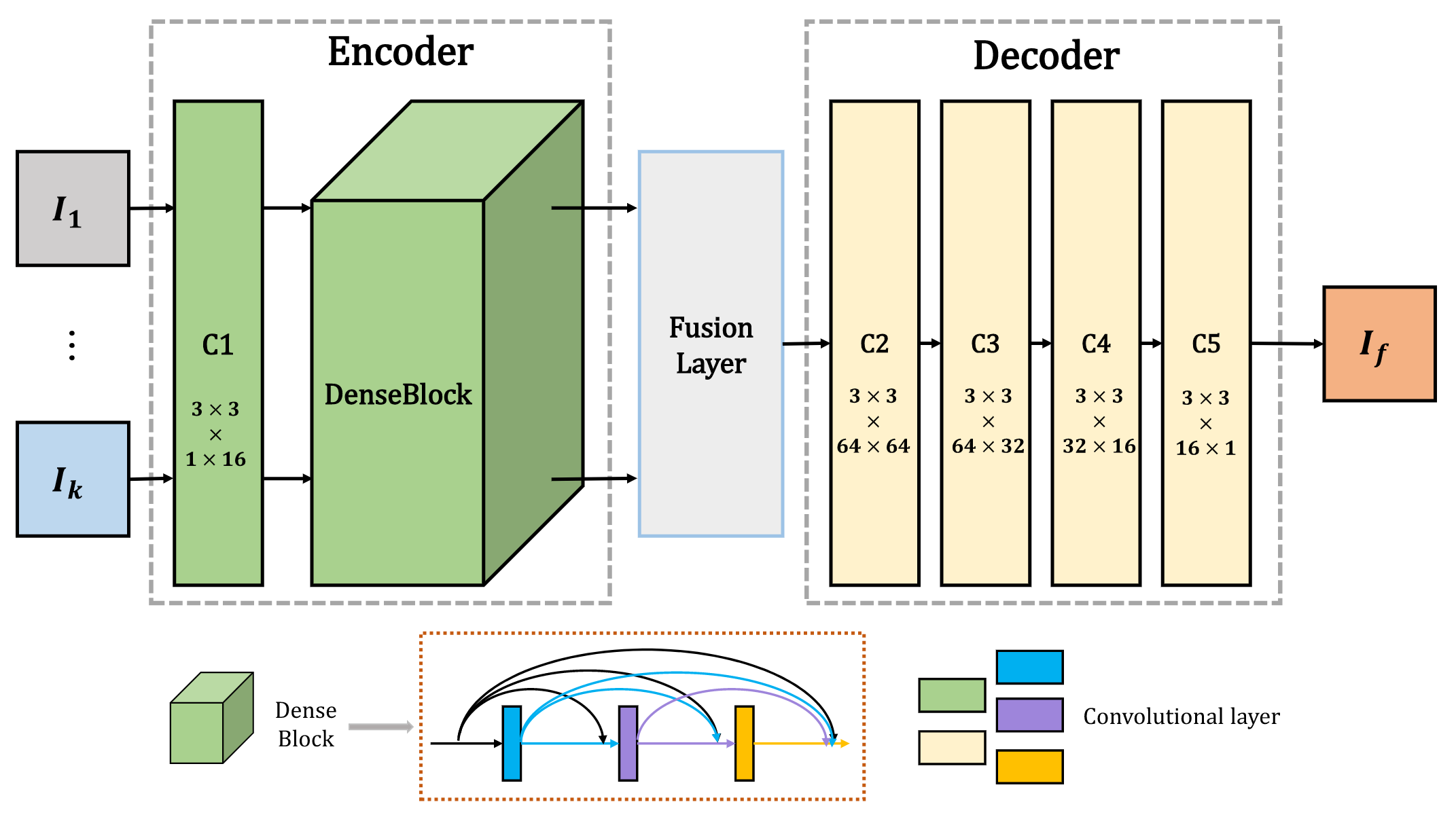
如上图所示,编码器包含两个部分(C1和DenseBlock),用于提取深度特征。第一层(C1)包含3×3卷积以提取粗糙特征,而DenseBlock包含三个卷积层(每个层的输出级联为随后的层的输入),其中也包含3×3卷积。编码器的体系结构具有两个优点。首先,滤波器的大小和卷积运算的步幅分别为3×3和1。使用此策略,输入图像可以是任何大小。其次,DenseBlock可以在编码网络中尽可能保留深度特征,并且该操作可以确保融合策略中使用所有显著特征。解码器包含四个卷积层(3×3卷积)。融合层的输出将是解码器的输入。使用这种简单有效的架构来重构最终融合的图像。
[损失函数]
作者采用了以下损失函数,由像素损失函数
L
p
L_p
Lp和结构相似性损失函数
L
s
s
i
m
L_{ssim}
Lssim加权得到:
L
p
=
∣
∣
O
−
I
∣
∣
2
L_p=||O-I||_2
Lp=∣∣O−I∣∣2
L
s
s
i
m
=
1
−
S
S
I
M
(
O
,
I
)
L_{ssim}=1-SSIM(O,I)
Lssim=1−SSIM(O,I)
L
=
λ
L
s
s
i
m
+
L
p
L=λL_{ssim}+L_p
L=λLssim+Lp
其中O和I分别表示输出图像和输入图像。
L
p
L_p
Lp是输出O和输入I之间的欧几里得距离,
S
S
I
M
(
⋅
)
SSIM(·)
SSIM(⋅)表示结构相似性,它表示两个图像的结构相似性。 由于像素损失和SSIM损失之间存在三个数量级的差异,因此在训练阶段,将
λ
λ
λ分别设置为1、10、100和1000。
[训练过程]
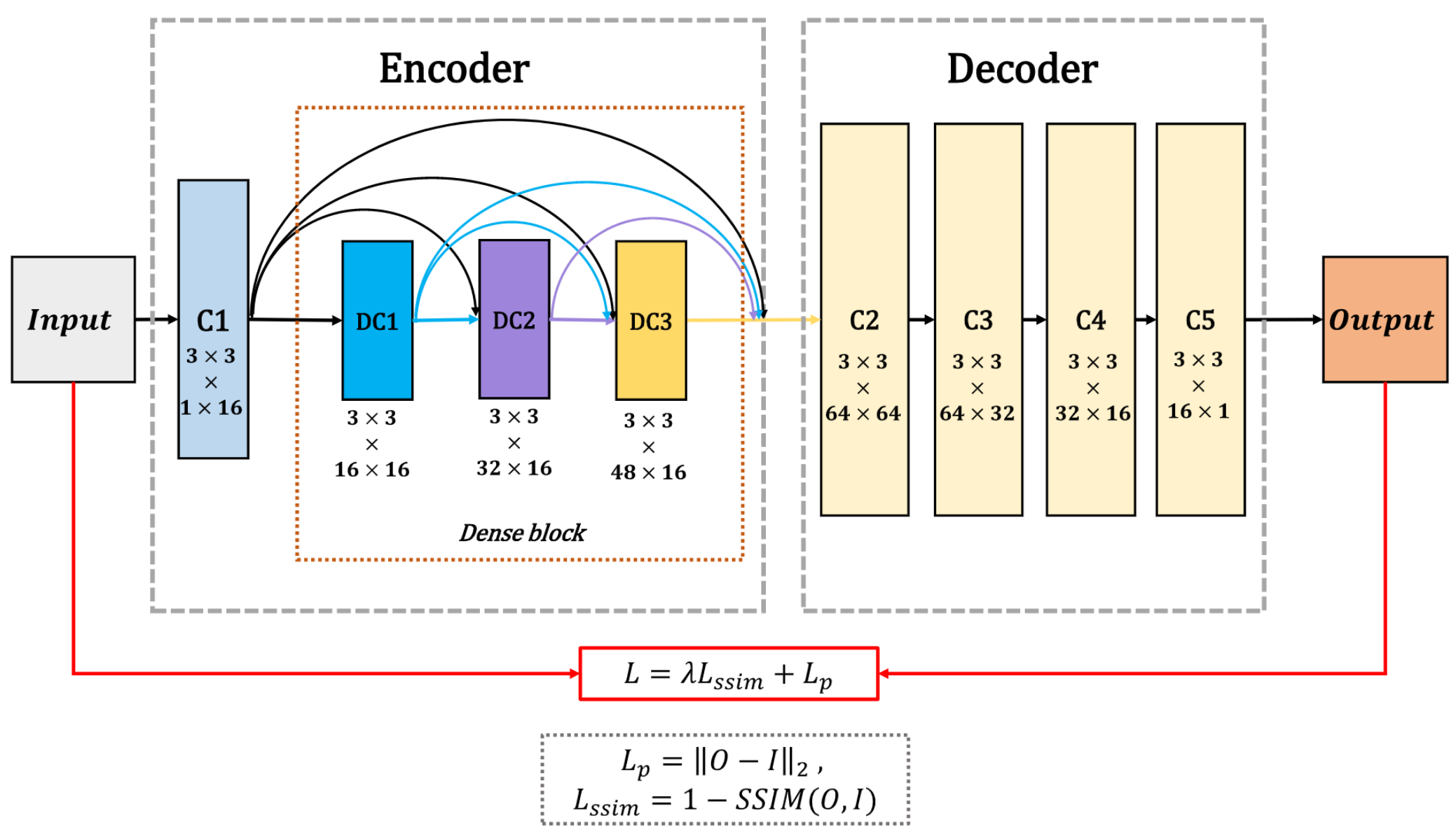
在训练阶段,作者只考虑编码器和解码器网络(融合层被丢弃),尝试训练编码器和解码器网络以重建输入图像。 固定编码器和解码器权重后,采用自适应融合策略融合编码器获得的深层特征。 下图展示了在训练阶段网络的详细结构。
下表概述了网络的体系结构。
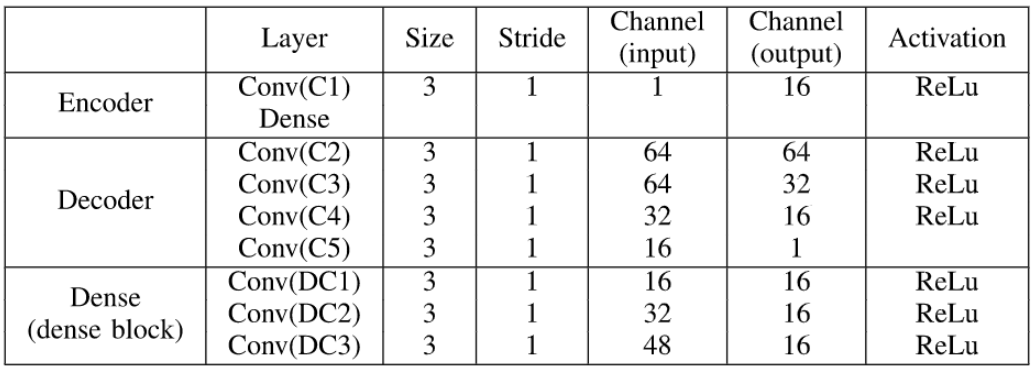
训练阶段的目的是训练具有更好特征提取和重构能力的自动编码器网络(编码器,解码器)。 由于红外和可见光图像的训练数据不足,使用MS-COCO的灰度图像来训练模型并且所有图像均被调整为 256 × 256 256×256 256×256大小并转换为灰度图像。 学习率设置为 1 × 1 0 − 4 1×10^{-4} 1×10−4。Batch_size和Epoch分别为2和4。
[融合策略]
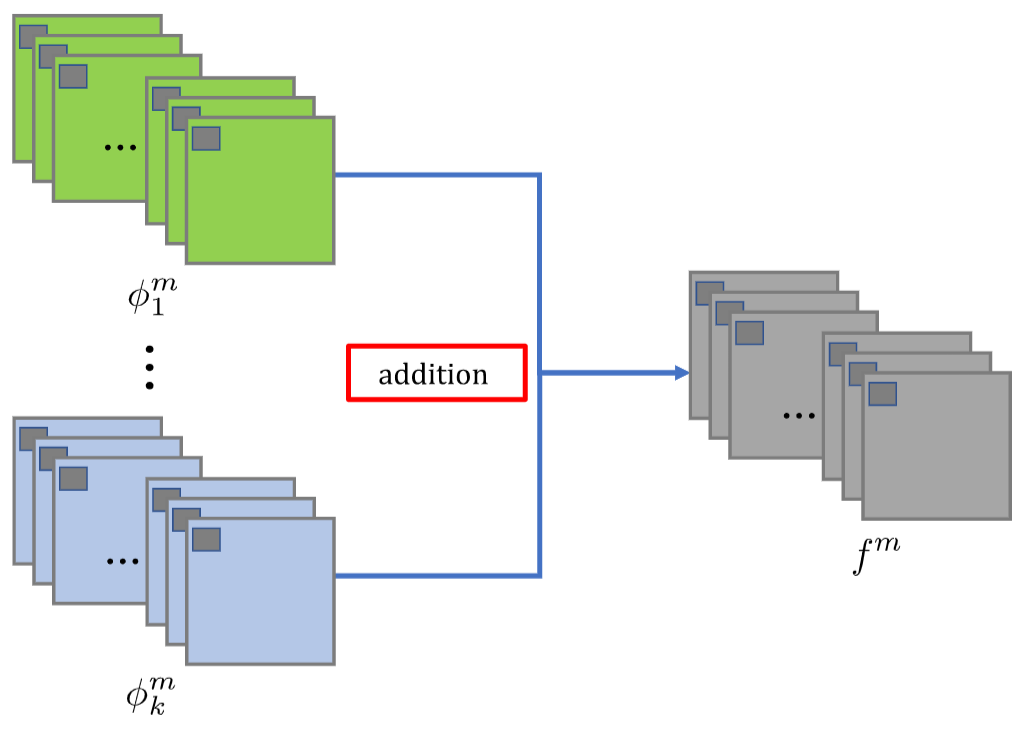
相加策略流程如下图所示。 测试阶段,在编码器和解码器网络后,将两个输入图像分别输入编码器。 作者选择两种融合策略(加法和l1-范数策略)融合编码器获得的特征图。
[相加策略]
其中
ϕ
k
m
\phi_{k}^{m}
ϕkm表示第
k
k
k种数据的第
m
m
m通道,
m
∈
{
1
,
2
,
.
.
.
,
64
}
,
k
≥
2
m \in \{1,2,...,64\},k \ge 2
m∈{1,2,...,64},k≥2,
f
m
f_m
fm为融合结果,满足:
f
m
=
∑
i
=
1
k
ϕ
i
m
(
x
,
y
)
f_m=\sum_{i=1}^{k}\phi_i^m(x,y)
fm=i=1∑kϕim(x,y)
[L1范数策略]
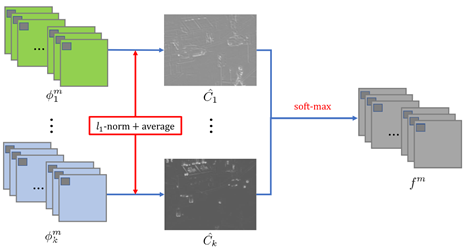
作者在网络中应用了基于L1范数和softmax运算的新策略。这种策略的示意图如下图所示。在图中,特征图由
φ
i
m
φ^m_i
φim表示,作用程度的图像
C
^
i
\hat{C}_{i}
C^i将由L1范数和基于块的平均算子计算,而
f
m
f_m
fm还是表示融合的特征图。L1范数可以作为特征图的作用程度的度量。 因此,由下式计算的初始作用程度图
C
i
C_i
Ci
C
i
(
x
,
y
)
=
∣
∣
ϕ
i
1
:
M
(
x
,
y
)
∣
∣
1
C_i(x,y)=||\phi_i^{1:M}(x,y)||_1
Ci(x,y)=∣∣ϕi1:M(x,y)∣∣1
然后根据下式进行范围内的平均:
C
^
i
(
x
,
y
)
=
∑
a
=
−
r
r
∑
b
=
−
r
r
C
i
(
x
+
a
,
y
+
b
)
(
2
r
+
1
)
2
\hat C_i(x,y)=\frac{\sum^r_{a=-r}\sum^r_{b=-r}C_i(x+a,y+b)}{(2r+1)^2}
C^i(x,y)=(2r+1)2∑a=−rr∑b=−rrCi(x+a,y+b)
其中
r
=
1
r=1
r=1决定一个像素是由以其为中心的3×3的范围内进行平均得到。
之后可以通过下式进行融合图生成:
f
m
(
x
,
y
)
=
∑
i
=
1
k
w
i
(
x
,
y
)
×
ϕ
i
m
(
x
,
y
)
w
i
(
x
,
y
)
=
C
^
i
(
x
,
y
)
∑
n
=
1
k
C
^
n
(
x
,
y
)
\begin{aligned} f^{m}(x, y) &=\sum_{i=1}^{k} w_{i}(x, y) \times \phi_{i}^{m}(x, y) \\ w_{i}(x, y) &=\frac{\hat{C}_{i}(x, y)}{\sum_{n=1}^{k} \hat{C}_{n}(x, y)} \end{aligned}
fm(x,y)wi(x,y)=i=1∑kwi(x,y)×ϕim(x,y)=∑n=1kC^n(x,y)C^i(x,y)
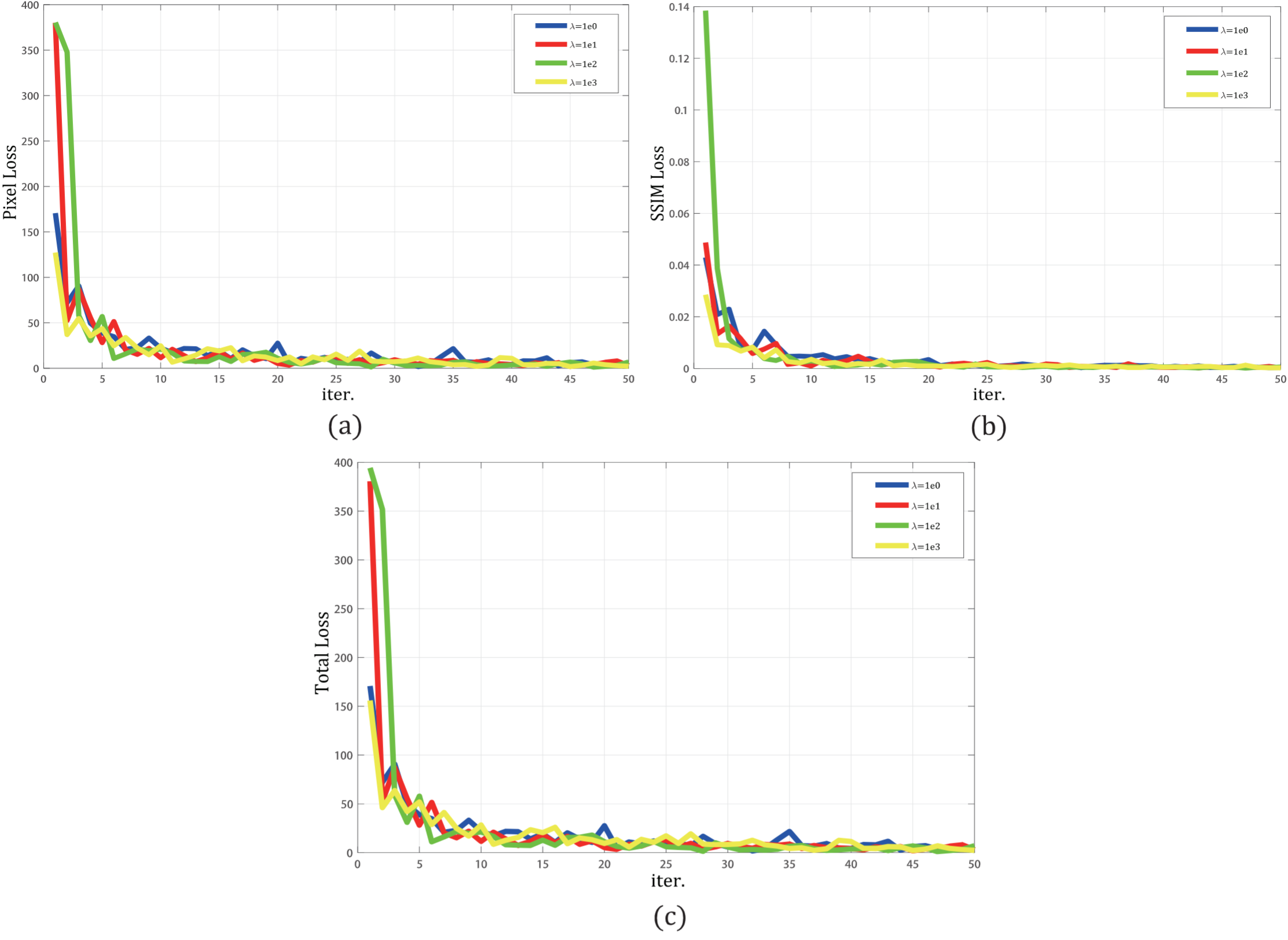
[结果分析]
[训练阶段]
下图展示了训练过程,像素损失(a),SSIM损失(b)和总损失(c)的变化图。 水平轴上的每个点表示100个Epoch,作者选择前5000次迭代。 并且“蓝色”为 λ = 1 λ= 1 λ=1;“红色”为 λ = 10 λ= 10 λ=10; “绿色”为 λ = 100 λ= 100 λ=100;“黄色”为 λ = 1000 λ= 1000 λ=1000。
下图展示了验证过程,像素损失(a)和SSIM损失(b)的变化图。
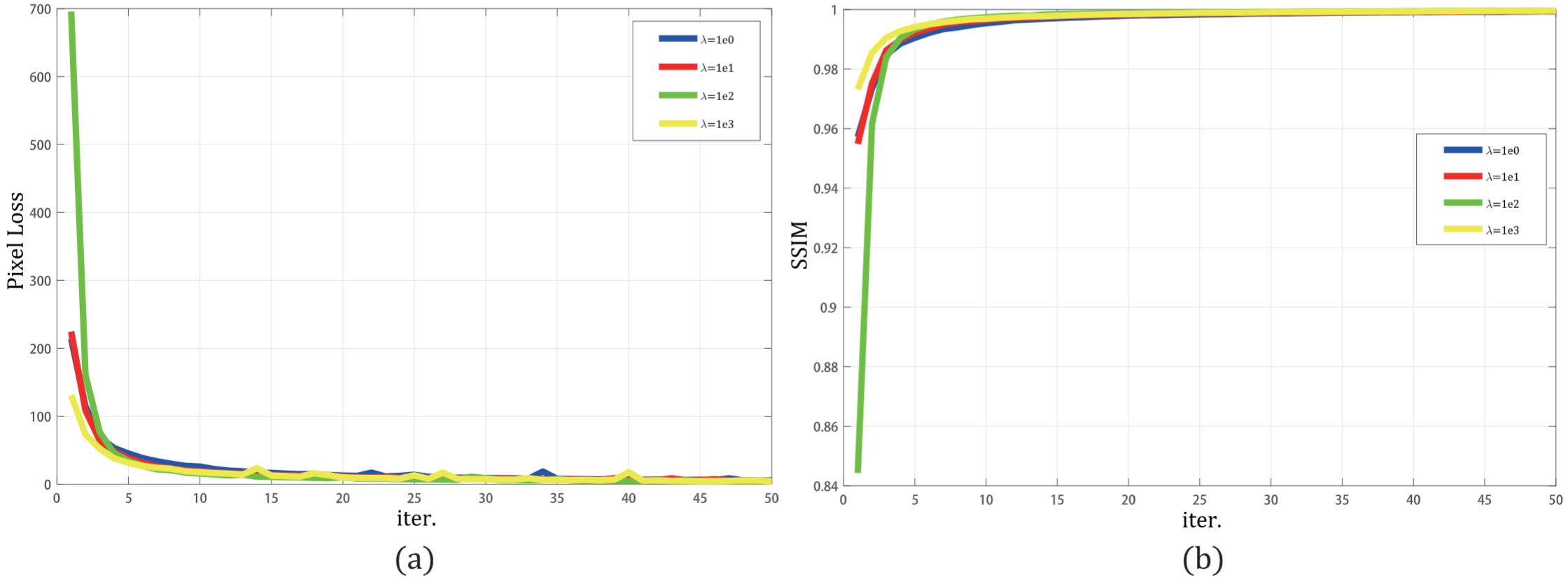
在训练阶段,作者使用MS-COCO作为输入图像。在这些源图像中,约有79000张图像被用作输入图像,在每次迭代中使用1000张图像来验证重构能力。
在训练过程的损失函数变化所示,在前2000次迭代中,随着SSIM损失权重
λ
λ
λ数值指数的增加,网络具有快速收敛性。 像素损失和SSIM损失之间的数量级是不同的。当
λ
λ
λ增大时,SSIM损失在训练阶段起着更重要的作用。
在验证过程中,作者从MS-COCO中选择1000张图像作为训练网络的输入。 利用像素损失和SSIM评估重建能力。 从验证过程的损失函数可以看出,验证图显示SSIM损耗随
λ
λ
λ的增加而起重要作用。 当迭代次数增加到500时,将
λ
λ
λ设置为较大的值时,像素损失和SSIM会达到更好的值。但是,当迭代次数大于40000时,无论选择哪种损失权重,都会获得最佳权重。所以,网络在早期训练阶段会随着
λ
λ
λ的增加而获得更快的收敛速度,较大的
λ
λ
λ将减少训练阶段的时间消耗。
[实验设置]
在作者的实验中,从其他论文收集了输入图像 k = 2 k=2 k=2的源红外和可见图像。 作者的方法与几种典型的融合方法进行了比较,包括交叉双边滤波融合方法(CBF),联合稀疏表示模型(JSR),梯度转移和总变异最小化(GTF),显着性检测融合方法(JSRSD)的JSR模型,基于深度卷积神经网络的方法(CNN)和DeepFuse方法(DeepFuse)。 在作者的实验中,DeepFuse方法的卷积大小设置为3×3。
[评价指标]
为了在融合方法上和其他现有算法之间进行定量比较,作者使用了七个质量度量。 它们是:
①熵(En);
②Qabf:差异相关性之和(SCD);
③
F
M
I
w
FMI_w
FMIw和
F
M
I
d
c
t
FMI_{dct}
FMIdct,分别计算小波特征和离散余弦特征的互信息(FMI);
④修改无参考图像的结构相似度(
S
S
I
M
a
SSIM_a
SSIMa); 以及新的无参考图像融合性能指标(
M
S
_
S
S
I
M
MS\_SSIM
MS_SSIM)。由下式计算出的
S
S
I
M
a
SSIM_a
SSIMa:
S
S
I
M
a
(
F
)
=
(
S
S
I
M
(
F
,
I
1
)
+
S
S
I
M
(
F
,
I
2
)
)
×
0.5
SSIM_a(F)=(SSIM(F,I_1)+SSIM(F,I_2))×0.5
SSIMa(F)=(SSIM(F,I1)+SSIM(F,I2))×0.5
其中,
S
S
I
M
(
⋅
)
SSIM(·)
SSIM(⋅)表示结构相似性操作,
F
F
F是融合图像,
I
1
I_1
I1、
I
2
I_2
I2是源图像。
S
S
I
M
a
SSIM_a
SSIMa的值表示保留结构信息的能力。
融合性能随着所有这七个指标的增加而提高。
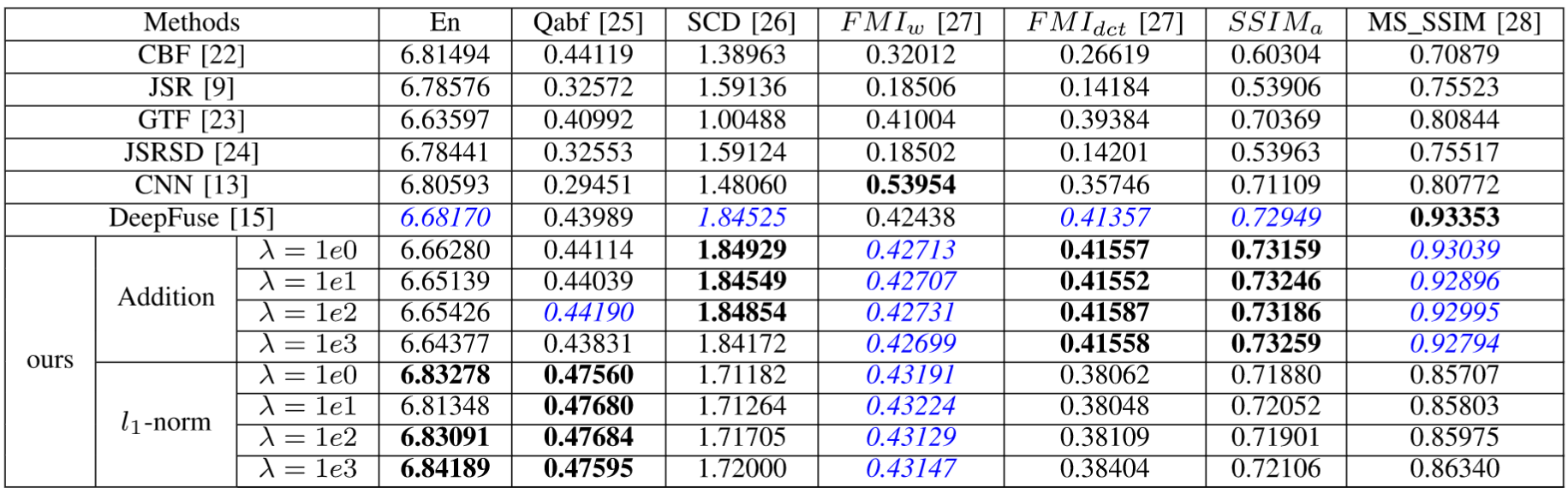
[融合结果评估]
下表中质量指标的最佳值以粗体表示,次优值以蓝色和斜体表示。这意味着作者的网络是红外和可见光图像融合的有效架构。
[RGB图像与红外图像的测试]
除了灰度图像融合任务外,融合算法还可用于融合包括RGB通道和红外图像的可见图像。处理RGB图像时,将RGB中的每个通道都视为一个灰度图像。 因此,一对RGB红外图像有四个通道,每个通道作为网络的输入图像。

🚪传送门
◉ 🎨RGB💥🔥红外
📦数据集
[TNO-RGB红外图像]
[FLIR-RGB红外图像]
[Multispectral Image Recognition-RGB红外目标检测]
[Multispectral Image Recognition-RGB红外语义分割]
[INO-RGB红外视频]
[SYSU-MM01行人重识别可见光红外数据]
📚论文
[VIF-Net:RGB和红外图像融合的无监督框架]
[SiamFT:通过完全卷积孪生网络进行的RGB红外融合跟踪方法]
[TU-Net/TDeepLab:基于RGB和红外的地形分类]
[RTFNet:用于城市场景语义分割的RGB和红外融合网络]
[DenseFuse:红外和可见图像的融合方法]
[MAPAN:基于自适应行人对准的可见红外跨模态行人重识别网络]
◉ 🌆多光谱💥🌁高光谱
📦数据集
[高光谱图像数据]
📚论文
[Deep Attention Network:基于深层注意力网络的高光谱与多光谱图像融合]
◉ 🎨RGB💥🥓SAR
📦数据集
[待更新]
📚论文
[待更新]
◉ 🎨RGB💥🔥红外💥🥓SAR
📦数据集
[待更新]
📚论文
[待更新]
💕大家有数据融合方向的优秀论文可以在评论分享一下,感谢。🤘















 6941
6941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









