







目录
📝论文下载地址
🔨代码下载地址
👨🎓论文作者
📦模型讲解
[背景介绍]
图像融合时信息融合的一种,本质就是增强技术,运用多传感器获得的不同数据来提高网络性能。相对于单传感器的数据局限于一种数据的特性,多传感器能同时利用多中数据的特性,在视频监控、卫星成像、军事上都有很好的发展前景。对于本文来说,可见图像提供了丰富的纹理细节和环境信息,而红外图像则受益于夜间可见性和对高动态区域的抑制。如下图所示,左边时红外图像,右边是可见光图像。

图像融合最关键的技术是怎么样能融合利用多种数据的优势。往往引入多种数据是双面性的,所以要抑制数据的不同带来的干扰。例如做变化检测的时候,往往因为成像不同而网络会错误地检测为变化。

上图展示了图像融合的基本操作,将可见光和红外图像同时输入网络中,进行特征提取,之后进行特征融合,最后特征重建,生成融合图像。中间网络的部分也就是作者提出的VIF-Net。
[论文解读]
作者主要针对其他融合方法有计算成本的局限性,而且需要手动设计融合规则。由此,作者提出了自适应的端到端深度融合框架VIF-Net,旨在生成信息更丰富的图像,包含大量的热信息和纹理细节。
[VIF-Net网络结构]
VIF-Net的全称为Visible and Infrared image Fusion Network就是可见光和红外图像融合网络。VIF-Net体系结构如下图所示,它由三个主要组件组成:特征提取,融合和重建。
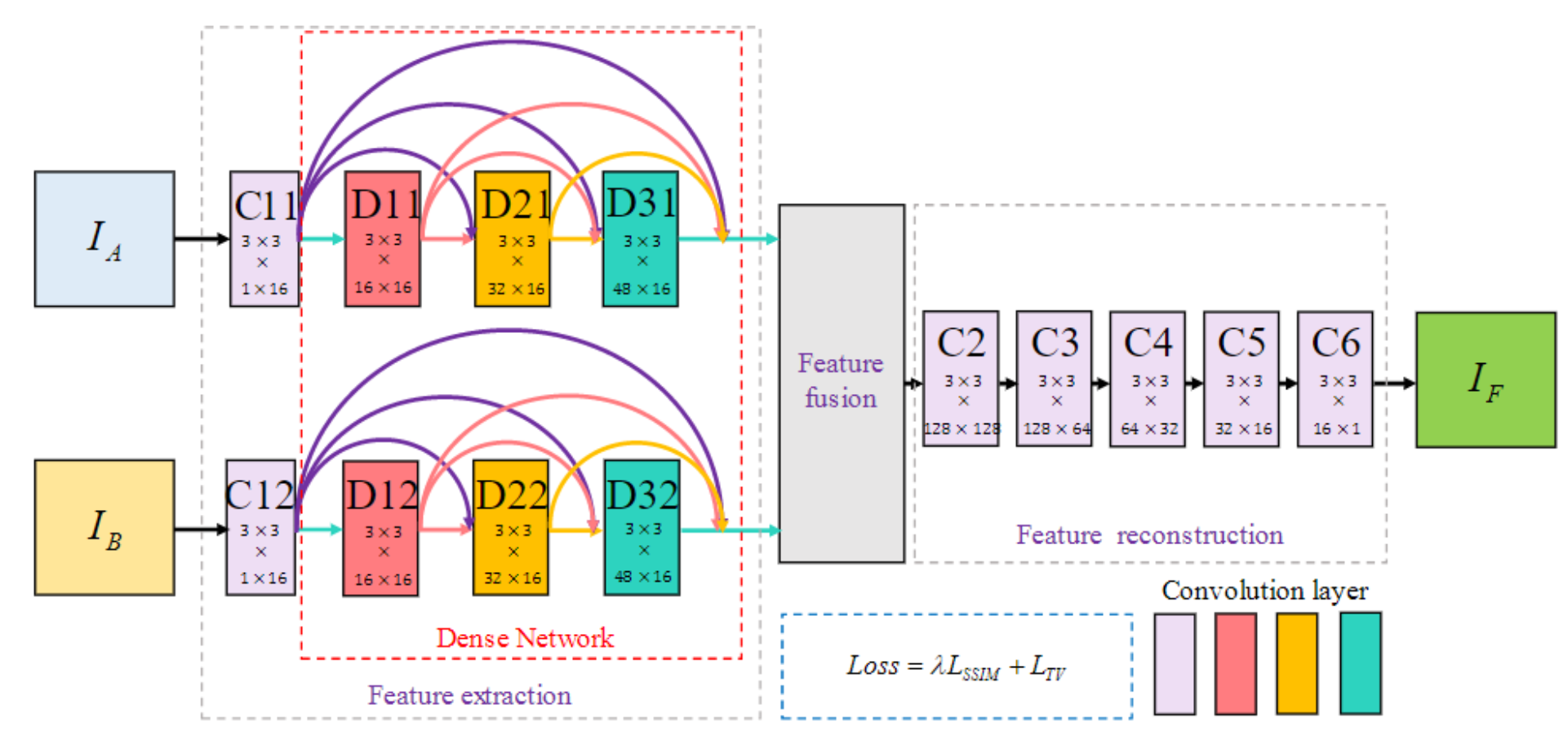
可见图像和红外图像分别表示为 I A I_A IA和 I B I_B IB,它们输入到双通道中。通道 A A A由 C 11 C11 C11和包含 D 11 D11 D11、 D 21 D21 D21和 D 31 D31 D31的block组成。通道 B B B由 C 12 C12 C12和一个包含 D 12 D12 D12, D 22 D22 D22和 D 32 D32 D32的block组成。第一层( C 11 C11 C11和 C 12 C12 C12)包含3×3的卷积以提取底层特征,每个 D D D中的三个卷积层也都是3×3的卷积。由于这两个通道共享相同的权重以提取相同类型的深度特征,因此此结构在降低计算复杂度方面也具有优势。在特征融合部分,作者尝试直接连接深层特征,也就是通道进行叠加。最后,特征融合层的结果通过另外五个卷积层( C 2 C2 C2, C 3 C3 C3, C 4 C4 C4, C 5 C5 C5和 C 6 C6 C6)来从融合特征中重建融合结果。下表概述了网络的更详细的体系结构:
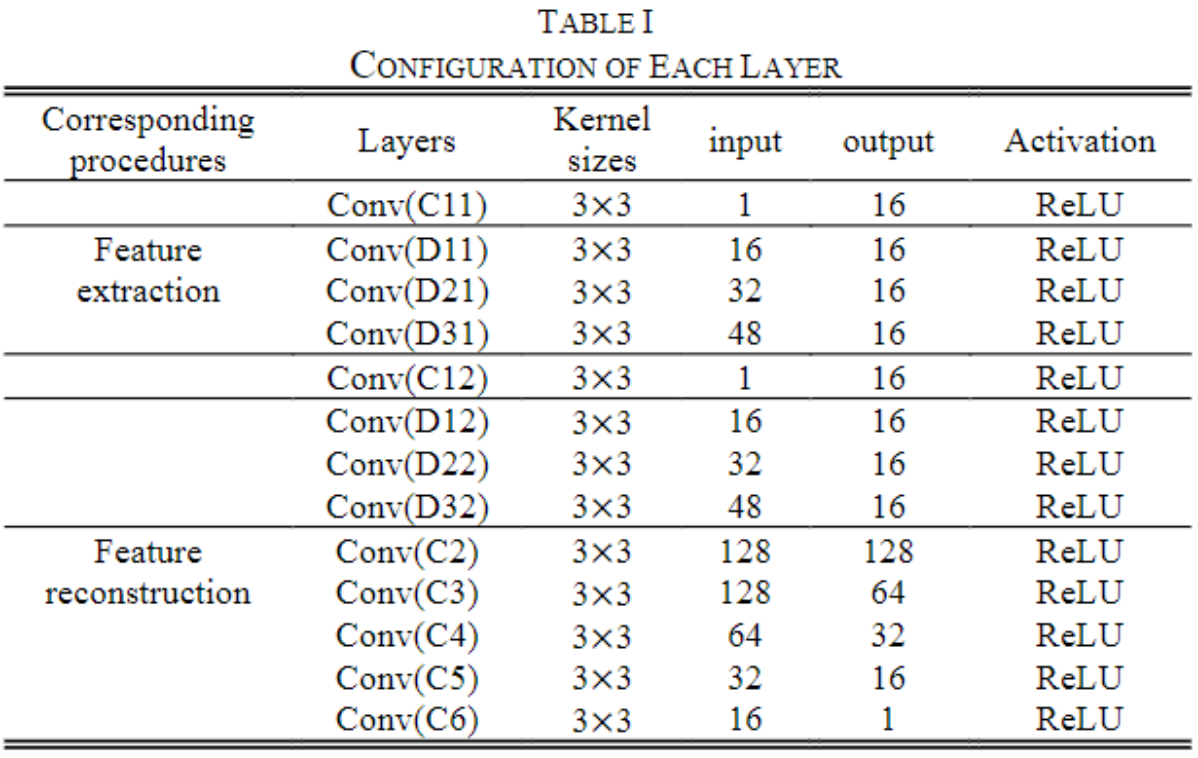
从表格的结构可以看出,假设输出都是单通道的图像,经过前面的特征提取层,每一层的输出都会与后面所有层的输出直接相连,这里是通道叠加。这样,可见光通道会输出 16 + 16 + 16 + 16 = 64 16+16+16+16=64 16+16+16+16=64通道的特征图,两个网络通道会生成 128 128 128通道,在特征融合层进行通道叠加,输入特征重建的就是 128 128 128通道的特征图。
[M-SSIM+TV损失]
从上面的结构图可以看到,损失函数主要分为两部分
L
S
S
I
M
L_{SSIM}
LSSIM和
L
T
V
L_{TV}
LTV,作者设计的损失函数为:
L
o
s
s
=
λ
L
S
S
I
M
+
L
T
V
Loss=λL_{SSIM}+L_{TV}
Loss=λLSSIM+LTV
[SSIM]
SSIM是一种衡量图像结构相似性的算法,结合了图像的亮度,对比度和结构三方面对图像质量进行测量。原本的SSIM公式为:
S
S
I
M
(
x
,
y
)
=
[
l
(
x
,
y
)
]
α
×
[
c
(
x
,
y
)
]
β
×
[
s
(
x
,
y
)
]
γ
SSIM(x,y)=[l(x,y)]^α×[c(x,y)]^β×[s(x,y)]^γ
SSIM(x,y)=[l(x,y)]α×[c(x,y)]β×[s(x,y)]γ
其中
l
(
x
,
y
)
l(x,y)
l(x,y)为亮度部分:
l
(
x
,
y
)
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
l(x,y)=\frac{2μ_xμ_y+C_1}{μ_x^2+μ_y^2+C_1}
l(x,y)=μx2+μy2+C12μxμy+C1
其中
c
(
x
,
y
)
c(x,y)
c(x,y)为对比度部分:
c
(
x
,
y
)
=
2
σ
x
σ
y
+
C
2
σ
x
2
+
σ
y
2
+
C
2
c(x,y)=\frac{2σ_xσ_y+C_2}{σ_x^2+σ_y^2+C_2}
c(x,y)=σx2+σy2+C22σxσy+C2
其中
s
(
x
,
y
)
s(x,y)
s(x,y)为结构部分:
s
(
x
,
y
)
=
σ
x
y
+
C
3
σ
x
σ
y
+
C
3
s(x,y)=\frac{σ_{xy}+C_3}{σ_xσ_y+C_3}
s(x,y)=σxσy+C3σxy+C3
其中
μ
x
μ_x
μx与
μ
y
μ_y
μy是图像的像素平均值,
σ
x
σ_x
σx和
σ
y
σ_y
σy为像素的标准差,
σ
x
y
σ_{xy}
σxy为
x
y
xy
xy的协方差,
C
1
C_1
C1、
C
2
C_2
C2和
C
3
C_3
C3是常数,防止分母为0。一般情况下,
α
=
β
=
γ
=
1
、
C
2
=
2
×
C
3
α=β=γ=1、C_2=2×C_3
α=β=γ=1、C2=2×C3则:
S
S
I
M
(
x
,
y
)
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
×
2
σ
x
σ
y
+
2
C
3
σ
x
2
+
σ
y
2
+
2
C
3
×
σ
x
y
+
C
3
σ
x
σ
y
+
C
3
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
×
2
σ
x
y
+
2
C
3
σ
x
2
+
σ
y
2
+
2
C
3
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
×
2
σ
x
y
+
C
2
σ
x
2
+
σ
y
2
+
C
2
SSIM(x,y)=\frac{2μ_xμ_y+C_1}{μ_x^2+μ_y^2+C_1}×\frac{2σ_xσ_y+2C_3}{σ_x^2+σ_y^2+2C_3}×\frac{σ_{xy}+C_3}{σ_xσ_y+C_3} \\=\frac{2μ_xμ_y+C_1}{μ_x^2+μ_y^2+C_1}×\frac{2σ_{xy}+2C_3}{σ_x^2+σ_y^2+2C_3}\\=\frac{2μ_xμ_y+C_1}{μ_x^2+μ_y^2+C_1}×\frac{2σ_{xy}+C_2}{σ_x^2+σ_y^2+C_2}
SSIM(x,y)=μx2+μy2+C12μxμy+C1×σx2+σy2+2C32σxσy+2C3×σxσy+C3σxy+C3=μx2+μy2+C12μxμy+C1×σx2+σy2+2C32σxy+2C3=μx2+μy2+C12μxμy+C1×σx2+σy2+C22σxy+C2
作者认为图像分辨率很低亮度就不是很重要,所以去除了亮度,重写公式:
S
S
I
M
M
(
x
,
y
∣
W
)
=
2
σ
x
y
+
C
σ
x
2
+
σ
y
2
+
C
SSIM_M(x,y|W)=\frac{2σ_{xy}+C}{σ_x^2+σ_y^2+C}
SSIMM(x,y∣W)=σx2+σy2+C2σxy+C
根据以上公式可以计算
S
S
I
M
M
(
I
A
,
I
F
∣
W
)
SSIM_M(I_A,I_F|W)
SSIMM(IA,IF∣W)和
S
S
I
M
M
(
I
B
,
I
F
∣
W
)
SSIM_M(I_B,I_F|W)
SSIMM(IB,IF∣W),其中
W
W
W代表一个滑动窗口,大小为
m
×
n
m×n
m×n,作者设置窗口为
11
×
11
11×11
11×11、
C
=
9
×
1
0
−
4
C=9×10^{-4}
C=9×10−4,利用这个公式来衡量
I
F
I_F
IF与
I
A
I_A
IA或者
I
B
I_B
IB哪个更相似。例如
S
S
I
M
M
(
I
B
,
I
F
∣
W
)
>
S
S
I
M
M
(
I
A
,
I
F
∣
W
)
SSIM_M(I_B,I_F|W)>SSIM_M(I_A,I_F|W)
SSIMM(IB,IF∣W)>SSIMM(IA,IF∣W)则
I
F
I_F
IF与
I
B
I_B
IB在窗口
W
W
W中更相似,
I
F
I_F
IF在窗口
W
W
W保留更多红外的信息。这样就能按以下公式自适应学习深度特征:
E
(
I
∣
W
)
=
1
m
×
n
∑
i
=
1
m
×
n
P
i
E(I | W)=\frac{1}{m \times n} \sum_{i=1}^{m \times n} P_{i}
E(I∣W)=m×n1i=1∑m×nPi
Score
(
I
A
,
I
B
,
I
F
∣
W
)
=
{
SSIM
M
(
I
A
,
I
F
∣
W
)
if
E
(
I
A
∣
W
)
>
E
(
I
B
∣
W
)
SSIM
M
(
I
B
,
I
F
∣
W
)
if
E
(
I
A
∣
W
)
≤
E
(
I
B
∣
W
)
\text { Score }\left(I_{A}, I_{B}, I_{F} | W\right)=\left\{\begin{array}{l} \operatorname{SSIM}_{M}\left(I_{A}, I_{F} | W\right) \text { if } E\left(I_{A} | W\right)>E\left(I_{B} | W\right) \\ \operatorname{SSIM}_{M}\left(I_{B}, I_{F} | W\right) \text { if } E\left(I_{A} | W\right) \leq E\left(I_{B} | W\right) \end{array}\right.
Score (IA,IB,IF∣W)={SSIMM(IA,IF∣W) if E(IA∣W)>E(IB∣W)SSIMM(IB,IF∣W) if E(IA∣W)≤E(IB∣W)
L
S
S
I
M
=
1
−
1
N
∑
W
=
1
N
Score
(
I
A
,
I
B
,
I
F
∣
W
)
L_{S S IM}=1-\frac{1}{N} \sum_{W=1}^{N} \operatorname{Score}\left(I_{A}, I_{B}, I_{F} | W\right)
LSSIM=1−N1W=1∑NScore(IA,IB,IF∣W)
上面第一个公式是计算窗口内的平均值,之后计算SSIM如果包含更多
A
A
A的信息,那么将
S
S
I
M
M
(
I
A
,
I
F
∣
W
)
SSIM_M(I_A,I_F|W)
SSIMM(IA,IF∣W)作为得分;如果包含更多
B
B
B的信息,那么将
S
S
I
M
M
(
I
B
,
I
F
∣
W
)
SSIM_M(I_B,I_F|W)
SSIMM(IB,IF∣W)作为得分。第三个公式给出了
L
S
S
I
M
L_{SSIM}
LSSIM的计算方法,
N
N
N为滑窗的总个数,将其取平均值后与1相减作为损失函数。
[TV]
TV全称是Total Variation译为总体变化,是一种衡量图片噪声的指标,传统的TV计算的公式为:
R
V
β
(
x
)
=
∑
i
,
j
(
(
x
i
,
j
+
1
−
x
i
j
)
2
+
(
x
i
+
1
,
j
−
x
i
j
)
2
)
β
2
\mathcal{R}_{V^{\beta}}(\mathbf{x})=\sum_{i, j}\left(\left(x_{i, j+1}-x_{i j}\right)^{2}+\left(x_{i+1, j}-x_{i j}\right)^{2}\right)^\frac{β}{2}
RVβ(x)=i,j∑((xi,j+1−xij)2+(xi+1,j−xij)2)2β
其中,
x
i
x_i
xi代表一个像素,将其与水平方向+1的像素做差的平方,和垂直方向+1的像素做差的平方,两者之和开
β
2
\frac{β}{2}
2β次方,对每个像素求和(除最后一行和列像素),这样就计算出TV。所以如果他有噪声的话,TV会明显变大,因为像素之间的变化会很大。然而,TV很小的话,图像会很模糊,因为相近的像素相等TV最小。作者运用以下公式求取
L
T
V
L_{TV}
LTV。
R
(
i
,
j
)
=
I
A
(
i
,
j
)
−
I
F
(
i
,
j
)
L
T
V
=
∑
i
,
j
(
∥
R
(
i
,
j
+
1
)
−
R
(
i
,
j
)
∥
2
+
∥
R
(
i
+
1
,
j
)
−
R
(
i
,
j
)
∥
2
)
\begin{array}{c} R(i, j)=I_{A}(i, j)-I_{F}(i, j) \\ L_{T V}=\sum_{i, j}\left(\|R(i, j+1)-R(i, j)\|_{2}+\|R(i+1, j)-R(i, j)\|_{2}\right) \end{array}
R(i,j)=IA(i,j)−IF(i,j)LTV=∑i,j(∥R(i,j+1)−R(i,j)∥2+∥R(i+1,j)−R(i,j)∥2)
首先对
I
A
I_A
IA和
I
F
I_F
IF对应像素相减,得到
R
(
i
,
j
)
R(i,j)
R(i,j),对
R
(
i
,
j
)
R(i,j)
R(i,j)求TV,作者取
β
=
2
β=2
β=2。接下来作者提到,
L
S
S
I
M
L_{SSIM}
LSSIM和
L
T
V
L_{TV}
LTV不在统一数量级,
L
S
S
I
M
L_{SSIM}
LSSIM会比
L
T
V
L_{TV}
LTV低
1
0
2
−
1
0
3
10^2-10^3
102−103。所以,这会导致网络更偏重于TV,使得图像分辨率,对比度较低,这也符合TV过低的情况。作者于是引入平衡参数
λ
λ
λ使两种损失函数在同一水平上。
L
o
s
s
=
λ
L
S
S
I
M
+
L
T
V
Loss=λL_{SSIM}+L_{TV}
Loss=λLSSIM+LTV
[VIF-Net的训练]
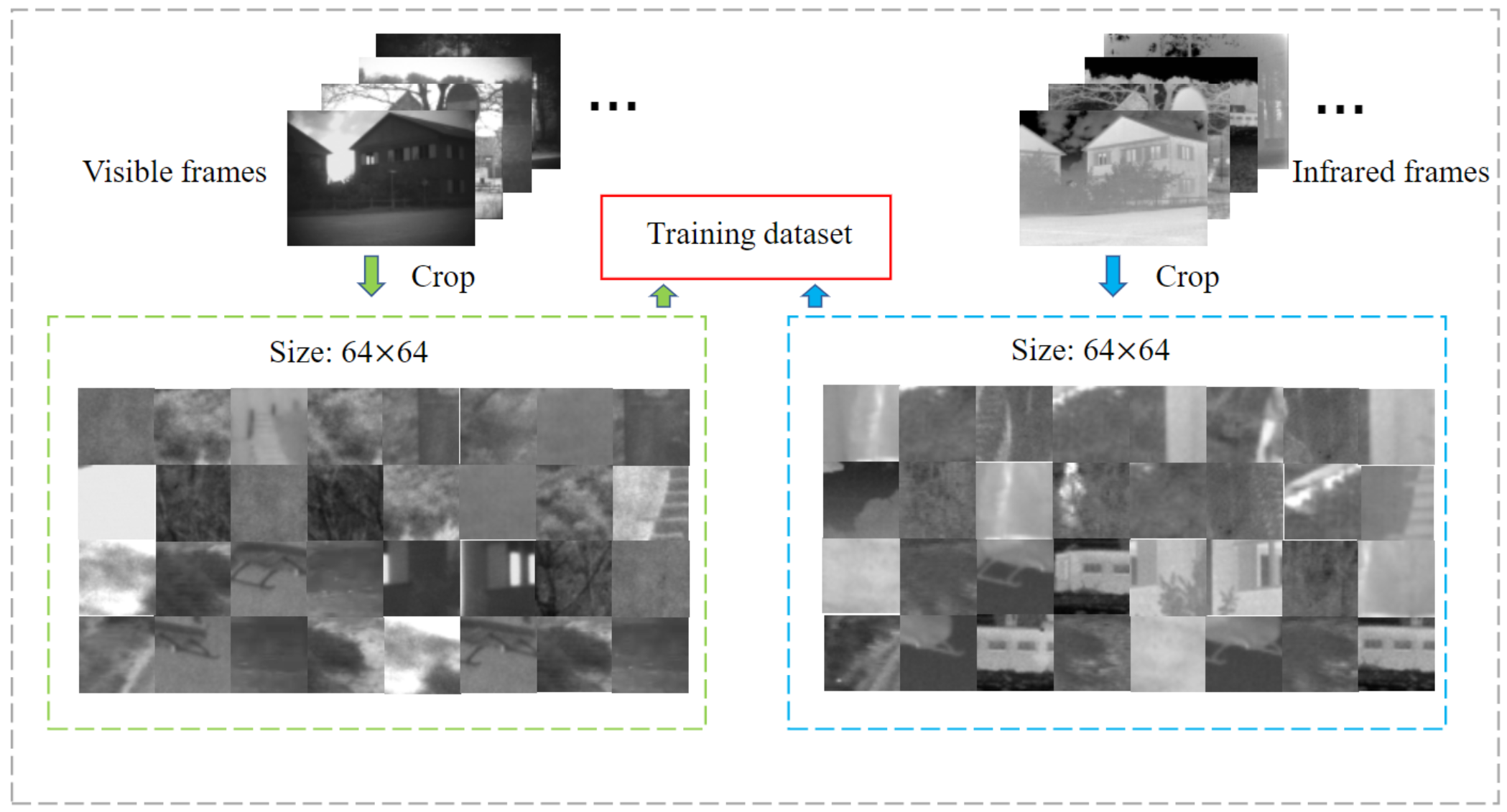
作者从公开可用的TNO图像数据集和INO视频数据集中收集了25对覆盖不同场景的可见和红外图像。 由于此数据集太小而无法满足训练要求,因此裁剪了约25000个尺寸为64×64的补丁,以扩展训练数据集而没有任何人工标签; 数据集的样本如下图所示。此外,作者将网络训练了50个epoch,使用Adam优化器以 1 0 − 4 10^{-4} 10−4的学习率将损失。 作者的网络是在TensorFlow上实现的,并在配备Intel E5 2670 2.6 GHz CPU,16 GB RAM和NVIDIA GTX1080Ti GPU的PC上进行了训练。
[结果分析]
[评价指标]
为了防止主观视觉的人为因素,作者使用物种可靠的量化指标:互信息/mutual information/ M I MI MI、边缘保持/edge retentiveness/ Q A B / F Q^{AB/F} QAB/F、相位一致性/phase congruency/ P C PC PC、非线性相关信息熵/nonlinear correlation information entropy/ Q N C I E Q^{NCIE} QNCIE、通用图像质量指数/universal image quality index/ U I Q I UIQI UIQI。
[ M I MI MI]
M
I
MI
MI分数越高,表示从源图像获得的信息越丰富。公式如下:
M
I
=
∑
i
A
∈
I
A
F
∑
i
∈
I
F
p
(
i
A
,
i
F
)
log
2
p
(
i
A
,
i
F
)
p
(
i
A
)
p
(
i
F
)
+
∑
i
B
∈
I
B
∑
i
F
∈
I
F
p
(
i
B
,
i
F
)
log
2
p
(
i
B
,
i
F
)
p
(
i
B
)
p
(
i
F
)
M I=\sum_{i_{A} \in I_{A_{F}}} \sum_{i \in I_{F}} p\left(i_{A}, i_{F}\right) \log _{2} \frac{p\left(i_{A}, i_{F}\right)}{p\left(i_{A}\right) p\left(i_{F}\right)}+\sum_{i_{B} \in I_{B}} \sum_{i_{F} \in I_{F}} p\left(i_{B}, i_{F}\right) \log _{2} \frac{p\left(i_{B}, i_{F}\right)}{p\left(i_{B}\right) p\left(i_{F}\right)}
MI=iA∈IAF∑i∈IF∑p(iA,iF)log2p(iA)p(iF)p(iA,iF)+iB∈IB∑iF∈IF∑p(iB,iF)log2p(iB)p(iF)p(iB,iF)
其中
p
(
i
A
,
i
F
)
p(i_A,i_F)
p(iA,iF)为
i
A
i_A
iA与
i
F
i_F
iF的联合概率分布,
p
(
i
A
)
p(i_A)
p(iA)为
i
A
i_A
iA的边缘概率分布。
[ Q A B / F Q^{AB/F} QAB/F]
Q
A
B
/
F
Q^{AB/F}
QAB/F测量了从原图像到融合图像转移的图像边缘数量。公式如下:
Q
A
B
/
F
=
∑
i
=
1
N
∑
j
=
1
M
(
Q
A
F
(
i
,
j
)
w
A
(
i
,
j
)
+
Q
B
F
(
i
,
j
)
w
B
(
i
,
j
)
)
∑
i
N
∑
j
M
(
w
A
(
i
,
j
)
+
w
B
(
i
,
j
)
)
Q^{AB/F}=\frac{\sum_{i=1}^{N} \sum_{j=1}^{M}\left(Q^{A F}(i, j) w^{A}(i, j)+Q^{B F}(i, j) w^{B}(i, j)\right)}{\sum_{i}^{N} \sum_{j}^{M}\left(w^{A}(i, j)+w^{B}(i, j)\right)}
QAB/F=∑iN∑jM(wA(i,j)+wB(i,j))∑i=1N∑j=1M(QAF(i,j)wA(i,j)+QBF(i,j)wB(i,j))
这里比较难理解计算,简单来说,会通过边缘检测算法(Sobel边缘检测算法)计算出输入图像和融合图像的边缘信息,在通过上式得出指标,指标越高越好。具体的过程可以访问[多聚焦图像像素级融合方法研究-总第27页-论文页码第14页-⑥]
[ P C PC PC]
PC表示融合图像的结构,定义如下:
P
C
=
(
P
p
)
α
(
P
M
)
β
(
P
m
)
γ
PC=(P_p)^α(P_M)^β(P_m)^γ
PC=(Pp)α(PM)β(Pm)γ
其中
p
p
p,
M
M
M和
m
m
m分别是相位,最大力矩和最小力矩,且
α
=
β
=
γ
=
1
α=β=γ=1
α=β=γ=1。
[ Q N C I E Q^{NCIE} QNCIE]
Q
N
C
I
E
Q^{NCIE}
QNCIE度量源图像和融合图像之间的非线性相关熵,定义如下:
Q
N
C
I
E
=
1
+
∑
i
=
1
3
λ
i
3
log
256
(
λ
i
3
)
Q^{N C I E}=1+\sum_{i=1}^{3} \frac{\lambda_{i}}{3} \log _{256}\left(\frac{\lambda_{i}}{3}\right)
QNCIE=1+i=1∑33λilog256(3λi)
其中
λ
i
\lambda_{i}
λi是非线性相关矩阵的特征值。
[ U I Q I UIQI UIQI]
另外,
U
I
Q
I
UIQI
UIQI是一种从相关损失,亮度和对比度三个方面来测量图像质量的评估指标。 定义如下:
U
I
Q
I
=
[
4
σ
I
,
I
F
μ
I
μ
I
F
(
σ
I
A
2
+
σ
I
F
2
)
(
μ
I
A
2
+
μ
I
F
2
)
+
4
σ
I
B
I
F
μ
I
B
μ
I
F
(
σ
I
B
2
+
σ
I
F
2
)
(
μ
I
B
2
+
μ
I
F
2
)
]
2
U I Q I=\frac{\left[\frac{4 \sigma_{I, I_{F}} \mu_{I} \mu_{I_{F}}}{\left(\sigma_{I_{A}}^{2}+\sigma_{I_{F}}^{2}\right)\left(\mu_{I_{A}}^{2}+\mu_{I_{F}}^{2}\right)}+\frac{4 \sigma_{I_{B} I_{F}} \mu_{I_{B}} \mu_{I_{F}}}{\left(\sigma_{I_{B}}^{2}+\sigma_{I_{F}}^{2}\right)\left(\mu_{I_{B}}^{2}+\mu_{I_{F}}^{2}\right)}\right]}{2}
UIQI=2[(σIA2+σIF2)(μIA2+μIF2)4σI,IFμIμIF+(σIB2+σIF2)(μIB2+μIF2)4σIBIFμIBμIF]
其中
μ
μ
μ和
σ
σ
σ分别表示平均值和标准偏差,
σ
I
A
I
F
σ_{I_AI_F}
σIAIF是
I
A
I_A
IA和
I
F
I_F
IF之间的互相关。
[不同方法之间的对比实验]
下面三个表格展示了三种图像(“Human”、“Street”、“Kaptein”)的测试结果。可以看出VIF-Net取得不错的性能。
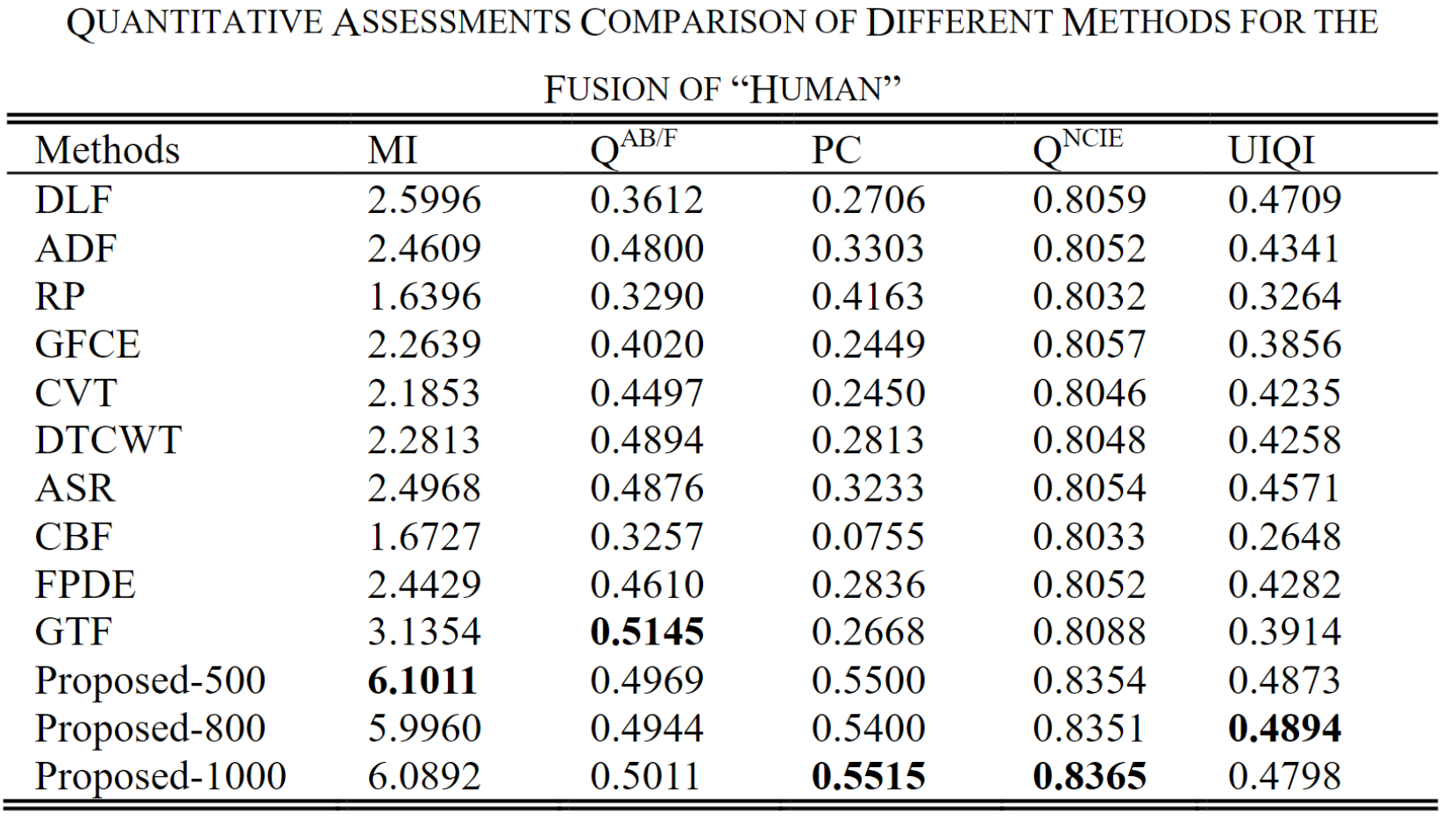
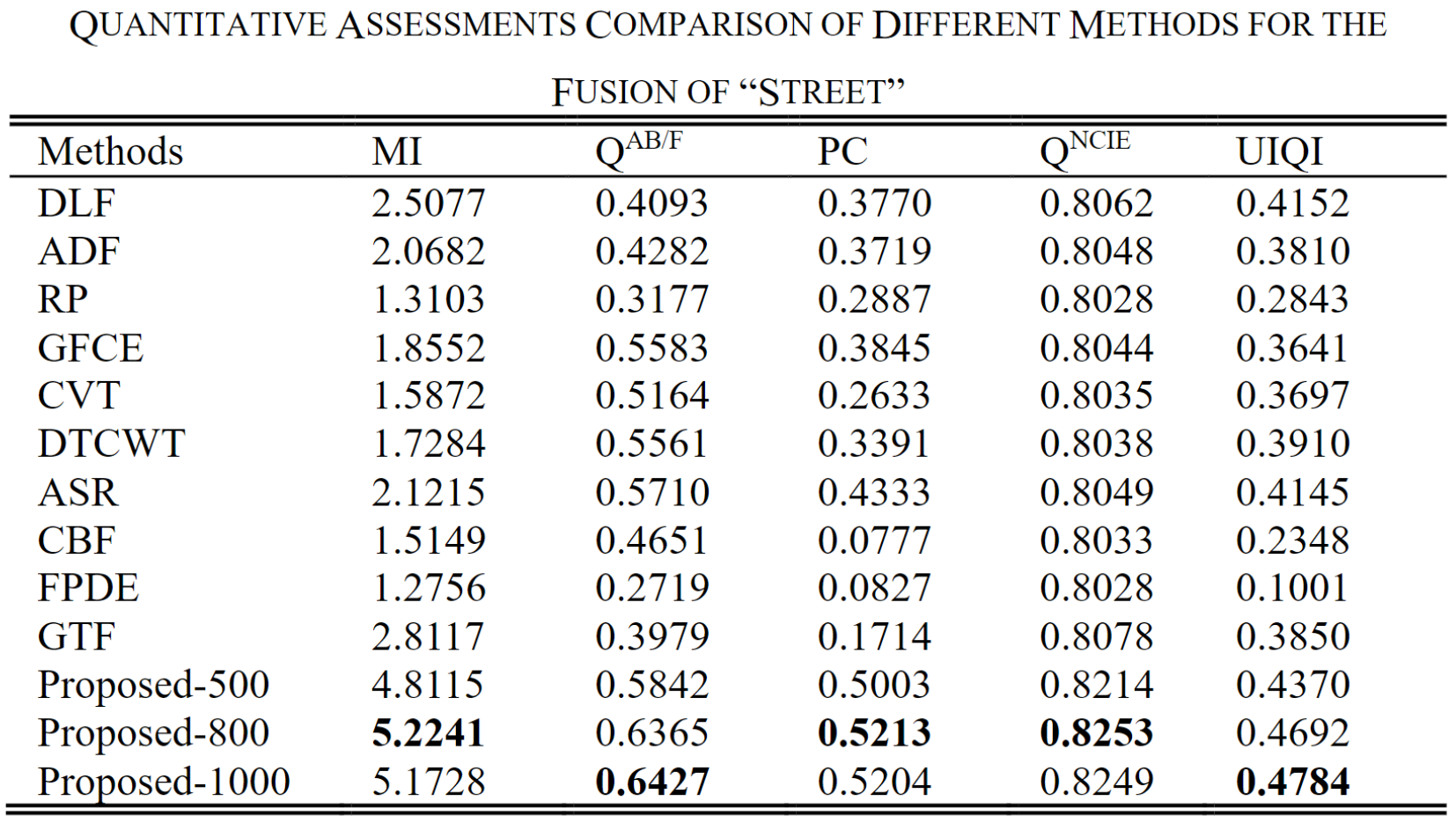
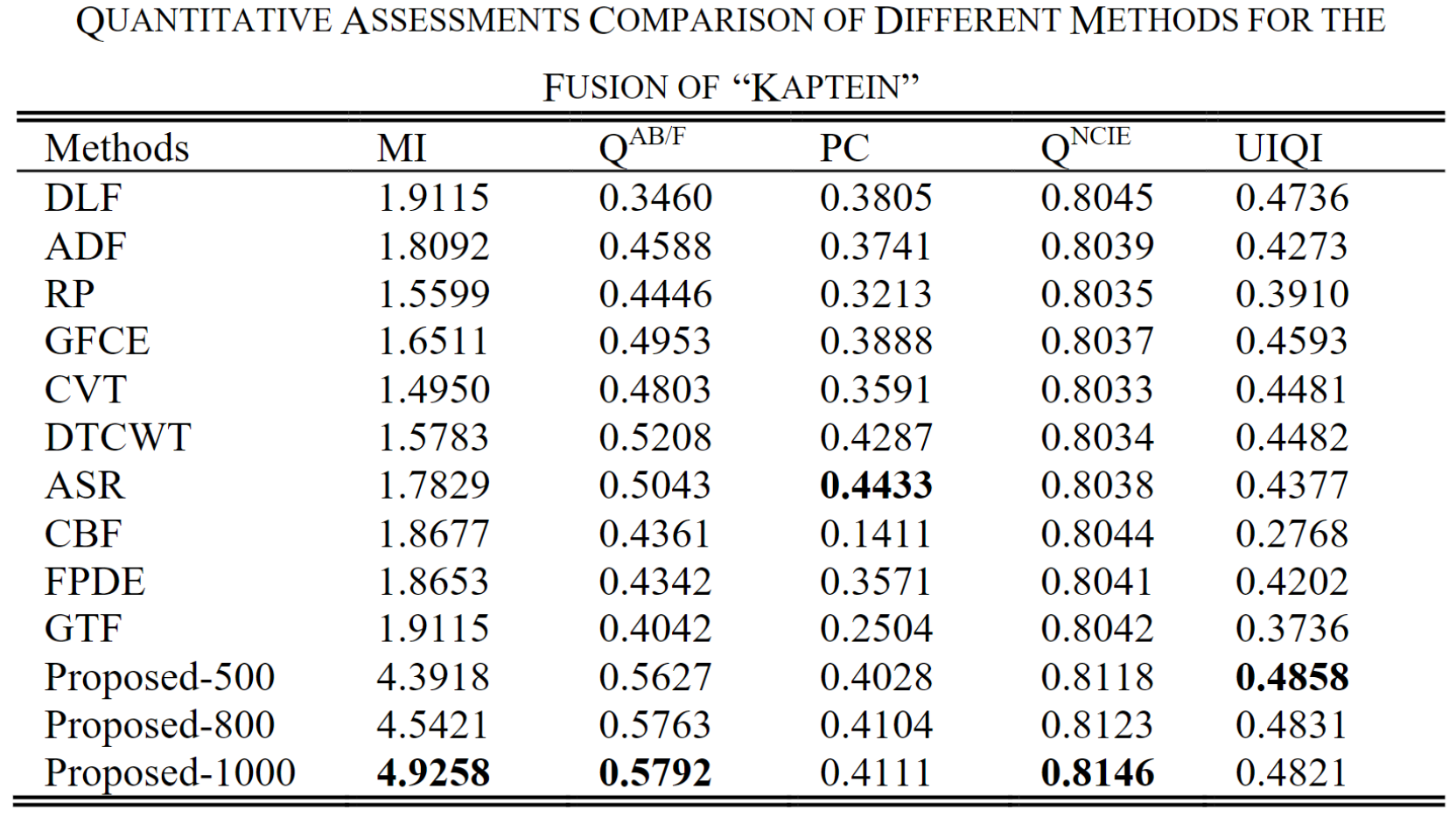
其中作者对损失函数的超参数的取值进行对比,Proposed-500/800/1000分别对应
λ
=
500
/
800
/
1000
\lambda =500/800/1000
λ=500/800/1000也就是下式:
L
o
s
s
=
λ
L
S
S
I
M
+
L
T
V
Loss=λL_{SSIM}+L_{TV}
Loss=λLSSIM+LTV
下图是三种图像的展示(自上向下是“Human”、“Street”、“Kaptein”),红色框是一些关键特征,可以看出效果很好:

从上图中可以看到,由于大量的人工噪声,RP和CBF的结果具有较差的视觉效果。 此外,DLF,ADF,CVT,DTCWT,ASR,FPDE的结果看起来非常相似,并且会产生伪像,目标尚不清楚。 此外,GFCE和GTF包含明亮而显眼的目标,但是基于GFCE的融合图像的背景由于细节和亮度的增强而失真。 由于GTF可以平滑纹理,因此可见的细节和边缘会在一定程度上丢失。作者的方法会突出显示红外目标并保留纹理细节,从而在这些方法中提供最佳的融合性能。

上图示出了“Street”的融合结果。 主要目标是将行人和路灯之类的信息融合到单个图像中,并尽可能保留车辆等环境信息。 更具体地说,作者所提出的方法的结果完全保留了信号灯,板上的字母和行人信息。 相反,GTF的结果会丢失大部分可见的细节,如标记区域所示。 DLF,ADF和FPDE的结果分辨率低,CVT,DTCWT和ASR将伪边缘引入融合图像,并且由于GFCE过度增强,融合结果中出现了伪影和失真。

上图中显示的结果与上述两组相似,并且在作者的结果中保留了突出特征,例如天空,雨伞,帐篷,尤其是行人特征。 总而言之,GTF的结果会平滑可见的细节和边缘,GFCE会导致图像失真,CBF和RP引入噪声,而基于DLF,ADF,CVT,DTCWT,ASR和FPDE的方法会导致对比度和分辨率低。 相反,作者的方法产生最佳的视觉效果。 此外,在作者的方法中基于不同参数的结果非常相似,在视觉评估水平上的差异可以忽略不计。
通常,由于单个度量无法客观地测量融合质量,因此作者选择这五个可靠的度量来评估不同的方法。 所提出的方法在
M
I
MI
MI,
Q
A
B
/
F
Q^{AB / F}
QAB/F,
P
C
PC
PC,
Q
N
C
I
E
Q^{NCIE}
QNCIE和
U
I
Q
I
UIQI
UIQI方面达到了最新的性能。 特别是,
M
I
MI
MI指标表明,VIF-Net在保留显着特征和纹理细节方面没有明显的伪像和失真,具有很高的能力。
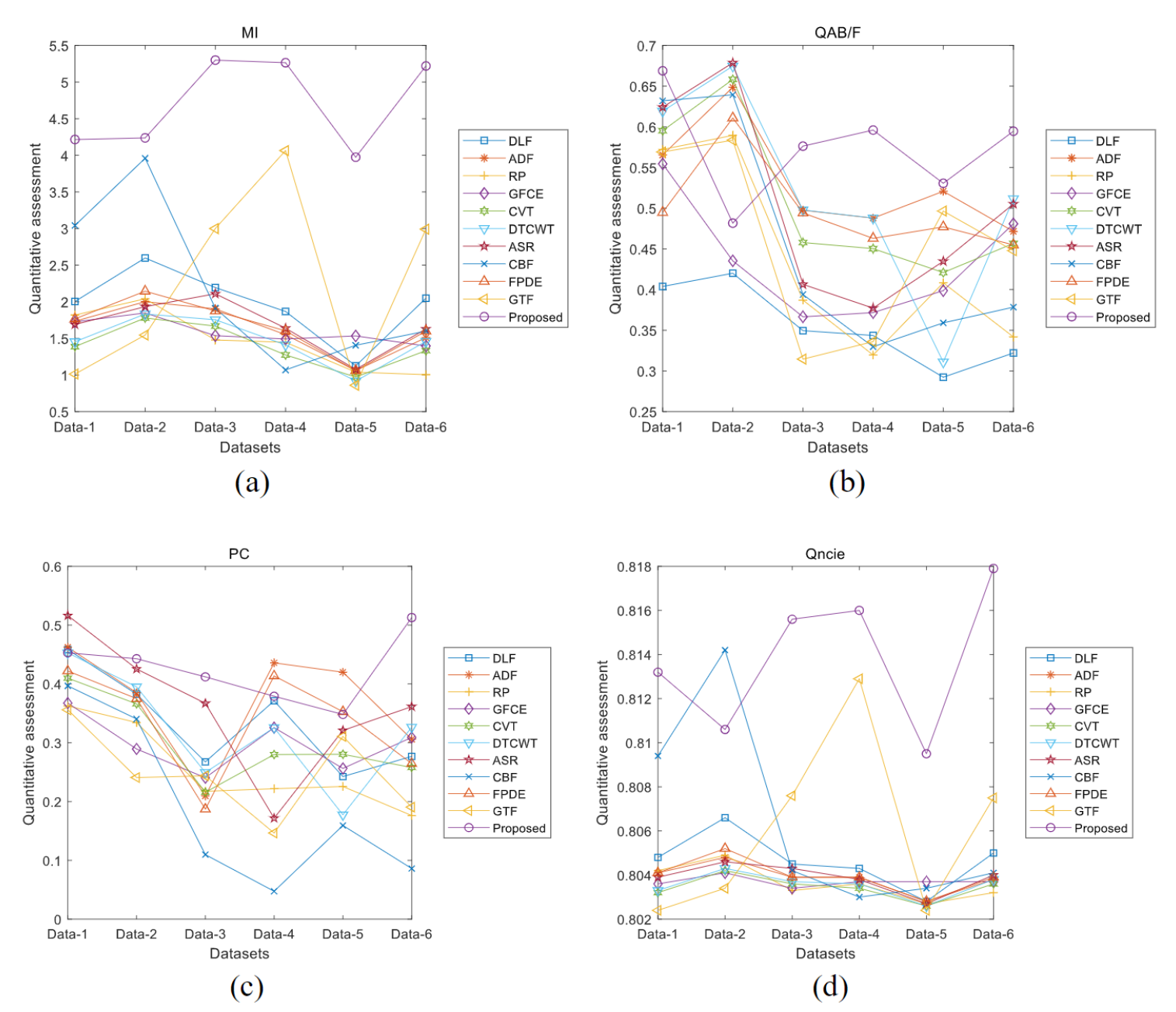
其他数据上的结果如下图所示:

其他数据上的结果在定量上的对比如下图所示, M I MI MI指标比其他比较方法的 M I MI MI指标高得多,而其余的指标通常要好于其他比较方法:
[不同λ之间的对比实验]
首先作者选取 λ = 50 / 500 / 5000 \lambda =50/500/5000 λ=50/500/5000得到下图结果:

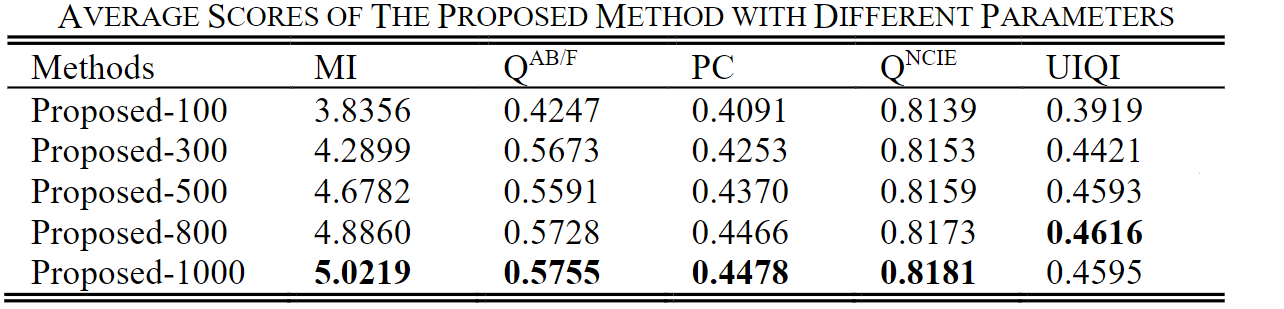
从实验结果来看,当 λ = 500 λ= 500 λ=500和 λ = 5000 λ= 5000 λ=5000时,融合结果差异不大,但后者丢失了一些纹理细节。 直观地,为了进一步突出红外目标,作者假设最佳 λ λ λ将略大于500。为估计VIF-Net的性能,将 λ λ λ的平均得分参数 λ λ λ设置为100、300、500、800和1,000。 提议的方法列于下表。
通过进一步分析,使用"Kaptein"对典型图像来证明VIF-Net的通用适应性,如下图所示。以"Kaptein"图中的结果为例,执行减法运算以方便观察差异。如下图所示,在视觉评估水平上的差异可以忽略不计。

作者认为可以在λ= 1000时获得最佳融合结果,以下结果均是采用此参数。
[推理时间对比]
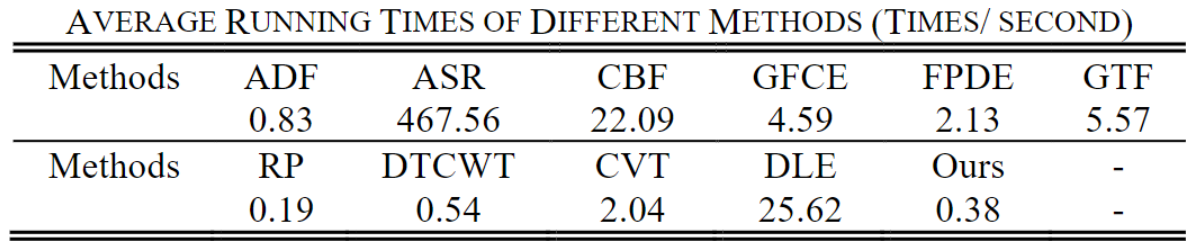
其他方法(包括DLF,CBF,GTF,GFCE,CVT,DTCWT和FPDE)包含优化算法或复杂的比例转换,并且需要大量迭代,因此平均运行时间较长。 相比之下,由于降维算法和结构简单,ADF和RP的计算复杂度较低。 总体而言,由于VIF-Net具有简单的网络结构和较高的运行效率,因此在实时视频融合中也很有效,下表展示运行一次所用的平均时间:
[扩展实验-视频融合]
作者选取两组视频进行试验,选择计算复杂度较低的ADF和DTCWT和作者提出的方法:
① “ ParkingSnow”,共有2941帧,大小为448×324。
第一行是ADF方法,第二行是DTCWT方法,第三行是VIF-Net,最后一行是标定的移动物体。

②“ TreesAndRunner”,共有558帧,大小为328×254。
第一行是ADF方法,第二行是DTCWT方法,第三行是VIF-Net,最后一行是标定的移动物体。

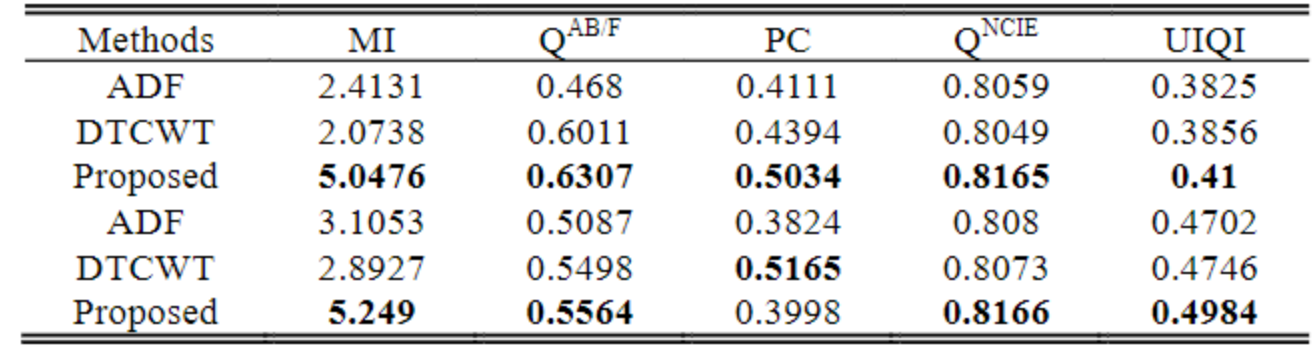
在绿色标记区域中,作者发现行人特征丢失,并且融合帧的对比度在ADF和DTCWT的结果中较弱。此外,DTCWT的结果导致目标边界周围出现重影伪影。但是,VIF-Net克服了这些缺点。表VII中列出了视频融合的平均客观评价指标。 VIF-Net在视频融合方面也表现出色。VIF-Net每帧的平均运行时间为0.22s和0.15s,基本可以满足实时融合应用的要求。
下面是融合后的指标对比,前三行是第一组视频,后三行是第二组视频。
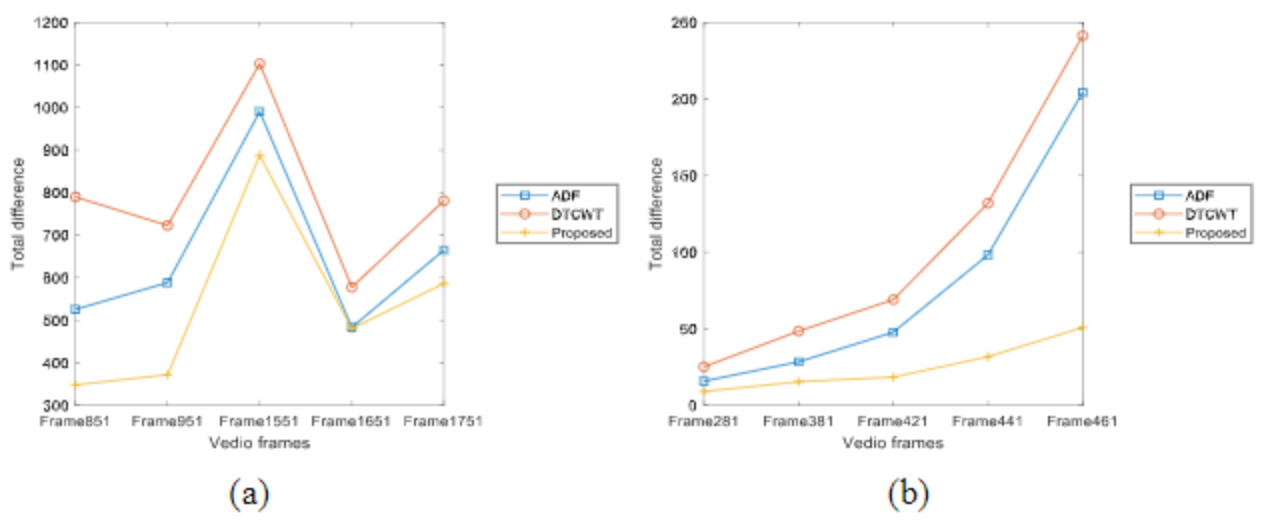
作者认为视频中移动的物体都是在红外图像比较明显的物体。将融合后的图像与红外图像中的移动物体抠出来,利用每一帧的Groundtruth,抠出来的图像相互做差,取绝对值。差值越小说明融合图融合红外图像效果更好。下图展示了三种方法在第一组视频(左)和第二组视频(右)上的差值对比。
🚪传送门
◉ 🎨RGB💥🔥红外
📦数据集
[TNO-RGB红外图像]
[FLIR-RGB红外图像]
[Multispectral Image Recognition-RGB红外目标检测]
[Multispectral Image Recognition-RGB红外语义分割]
[INO-RGB红外视频]
[SYSU-MM01行人重识别可见光红外数据]
📚论文
[VIF-Net:RGB和红外图像融合的无监督框架]
[SiamFT:通过完全卷积孪生网络进行的RGB红外融合跟踪方法]
[TU-Net/TDeepLab:基于RGB和红外的地形分类]
[RTFNet:用于城市场景语义分割的RGB和红外融合网络]
[DenseFuse:红外和可见图像的融合方法]
[MAPAN:基于自适应行人对准的可见红外跨模态行人重识别网络]
◉ 🌆多光谱💥🌁高光谱
📦数据集
[高光谱图像数据]
📚论文
[Deep Attention Network:基于深层注意力网络的高光谱与多光谱图像融合]
◉ 🎨RGB💥🥓SAR
📦数据集
[待更新]
📚论文
[待更新]
◉ 🎨RGB💥🔥红外💥🥓SAR
📦数据集
[待更新]
📚论文
[待更新]
💕大家有数据融合方向的优秀论文可以在评论分享一下,感谢。🤘

















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









