









目录
📝论文下载地址
🔨代码下载地址
👨🎓论文作者
📦模型讲解
[背景介绍]
[Transformer]
Transformer相关背景见[Transformer]。Transformer在处理计算机视觉任务取得不错的效果,但是始终没能超过卷积神经网络的相关方法。例如,针对图像识别任务的ViT网络,针对图像目标检测任务的DETR网络。目前大多数的针对CV的Transformer方法都是首先将输入图像拆分为补丁,补丁的处理方式与 NLP 应用程序中相同。然后使用几个自监督层进行全局的信息交流,提取特征进行分类。
[图像质量评估/IQA]
图像质量评估本质上是一项识别任务,即识别质量图像的优劣。现有深度学习的IQA模型用CNN实现。例如使用CNN作为特征提取器和MLP预测图像质量。将CNN应用于小图像块,然后结合补丁的质量预测成为一个单一的质量指标。
图像质量会受到空间分辨率影响。例如,缩小采样图像可能会降低其感知质量。Transformer 可以接受输入具有不同的长度。因此,也可以调整 Transformer编码器对不同分辨率的图像构建一个通用IQA模型。相关图像质量指标以及评估图像质量指标的指标可参考[IQA]。
[模型解读]
在本文中作者提出TRIQ的Transformer网络评估图像质量。
[总体结构]
作者参考了ViT网络结构。ViT包含两种方法:基于图像补丁的方法与混合方法。
基于图像补丁的方法:图像划分为固定大小的补丁(例如,32×32 像素),直接送入Transformer编码器。
混合方法:使用一个CNN网络进行特征提取。然后将特征进行通道压缩后送入Transformer编码器。
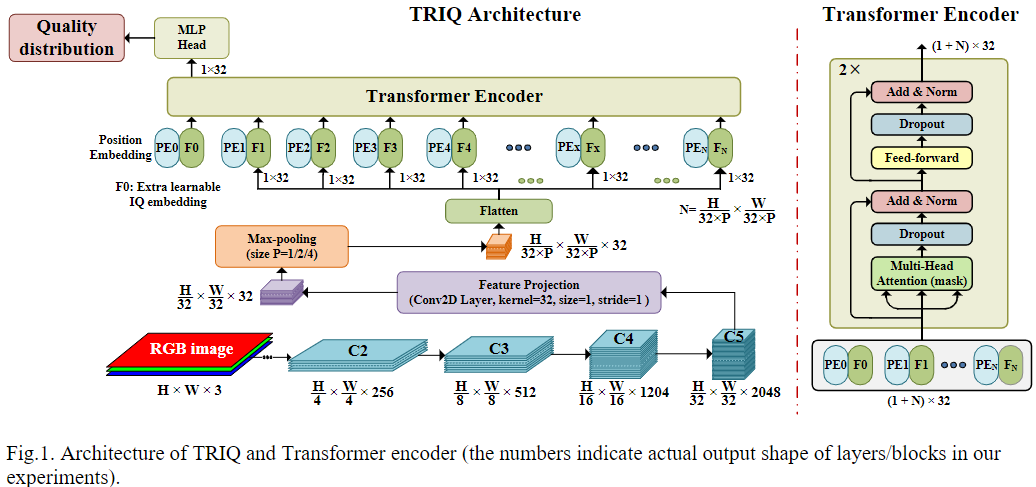
TRIQ网络的总体结构如上图所示。作者引入了一个卷积层Feature Projection层进行特征的映射。将2048通道的特征图再通道维度上压缩至与Transformer输入维度相同的大小,图中取值为32,表示每一个图像补丁用32长度的向量表示。那么对于基于图像补丁的方法的TRIQ,图像补丁取 32 × 32 32\times32 32×32。对于混合方法的TRIQ,通过CNN提取的特征尺寸为 [ H / 32 , W / 32 , D ] [H/32, W/32, D] [H/32,W/32,D], H H H、 W W W分别为输入图像的高、宽。例如,如果使用ResNet50作为backbone,它生成形状为 [ H / 32 , W / 32 , 2048 ] [H/32, W/32,2048] [H/32,W/32,2048],其中2048是通道维度。Feature Projection层中的卷积核大小和步长设置为1。投影的特征为 [ H / 32 , W / 32 , D ] [H/32, W/32, D] [H/32,W/32,D]。
[通用TRIQ模型]
用于图像识别的 ViT 采用恒定的输入大小。然而,IQA 中应该避免调整图像大小。所以,TRIQ 需要处理不同分辨率的图像。作者定义具有足够长度的位置编码来覆盖数据集中的最大图像分辨率。
另外,当输入图像具有大分辨率时,图像块或CNN特征的数量
[
H
/
32
,
W
/
32
]
[H/32,W/32]
[H/32,W/32]很大。这会导致两个潜在的问题。
硬件需求大:需要大量内存来运行Transformer。
网络鲁棒性差:大量图像补丁使得Transformer难以捕捉图像补丁之间的依赖性。
因此,作者加入最大池化层,池化范围取决于输入图像分辨率。对于混合方法的TRIQ,在送入Transformer之前使用最大池化。对于图像补丁方法的TRIQ,图像补丁先输入到Feature Projection层,然后执行最大池化。因此,输入Transformer的特征尺寸为
[
H
/
(
32
×
P
)
,
W
/
(
32
×
P
)
,
D
]
[H/(32\times P), W/(32\times P), D]
[H/(32×P),W/(32×P),D],其中
P
P
P是最大池化的大小。
随后,将特征展平为
[
N
=
(
H
×
W
)
/
(
32
×
32
×
P
×
P
)
,
D
]
[N=(H×W)/(32×32×P×P),D]
[N=(H×W)/(32×32×P×P),D],加入可学习的位置编码(PE)。在前面还多加了一个额外的特征token。下式大致说明投影,最大池化和位置编码,其中
F
M
FM
FM表示特征图。
{
F
j
=
Max
[
Conv
2
D
−
proj
(
F
M
)
]
,
j
=
1
,
⋯
N
Z
0
=
[
F
0
+
P
E
0
;
⋯
F
N
+
P
E
N
]
,
P
E
j
∈
R
(
1
+
N
)
×
D
\left\{\begin{array}{l} F_{j}=\operatorname{Max}\left[\operatorname{Conv} 2 D_{-} \operatorname{proj}(F M)\right], \quad j=1, \cdots N \\ Z_{0}=\left[F_{0}+P E_{0} ; \cdots F_{N}+P E_{N}\right], P E_{j} \in R^{(1+N) \times D} \end{array}\right.
{Fj=Max[Conv2D−proj(FM)],j=1,⋯NZ0=[F0+PE0;⋯FN+PEN],PEj∈R(1+N)×D
[TRIQ的Transformer]
Transformer 编码器主要由四个超参数:层数
L
=
2
L=2
L=2,输入维度
D
=
32
D=32
D=32、Head数目
H
=
8
H=8
H=8和 MLP的中间特征尺寸
d
f
f
=
64
d_{ff}=64
dff=64。如上图右侧,每个编码器层包含两个子层:第一个是多头注意力(MHA),第二个是前馈网络,使用层归一化 (LN)、跨层连接。Transformer编码器输出为
(
1
+
N
)
×
D
(1+N)\times D
(1+N)×D。
{
Z
l
′
=
L
N
(
M
H
A
(
Z
l
−
1
)
+
Z
l
−
1
)
Z
l
=
L
N
(
F
F
(
Z
l
′
)
+
Z
l
′
)
l
=
1
,
⋯
L
\left\{\begin{array}{l} Z_{l}^{\prime}=L N\left(M H A\left(Z_{l-1}\right)+Z_{l-1}\right) \\ Z_{l}=L N\left(F F\left(Z_{l}^{\prime}\right)+Z_{l}^{\prime}\right) \end{array} \quad l=1, \cdots L\right.
{Zl′=LN(MHA(Zl−1)+Zl−1)Zl=LN(FF(Zl′)+Zl′)l=1,⋯L
最后是输出的是加入的token尺寸为
1
×
32
1\times 32
1×32,之后送入MLP头由两个全连接层组成。网络预测投票等级的质量分布(例如1=差,2=较差,3=一般,4=好,5=优秀)经常提供比单个 MOS 值更可靠的结果。在最后一个 FC 层中使用Softmax激活函数归一化五个质量等级的概率。最后,选择交叉熵作为损失函数来衡量预测图像质量分布之间的距离和真实分布。假设
p
(
x
)
p(x)
p(x)表示TRIQ 预测的归一化概率,单个MOS值可以通过下式计算。
M
O
S
=
∑
x
∈
{
1
,
2
,
3
,
4
,
5
}
x
⋅
p
(
x
)
M O S=\sum_{x \in\{1,2,3,4,5\}} x \cdot p(x)
MOS=x∈{1,2,3,4,5}∑x⋅p(x)
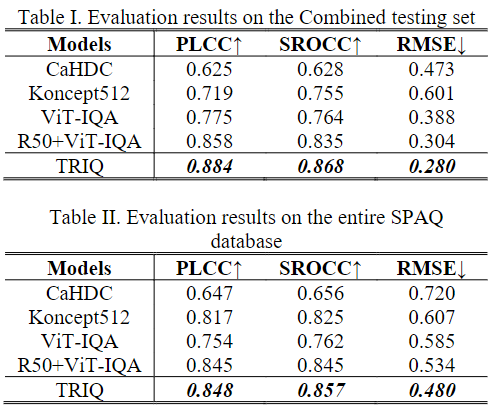
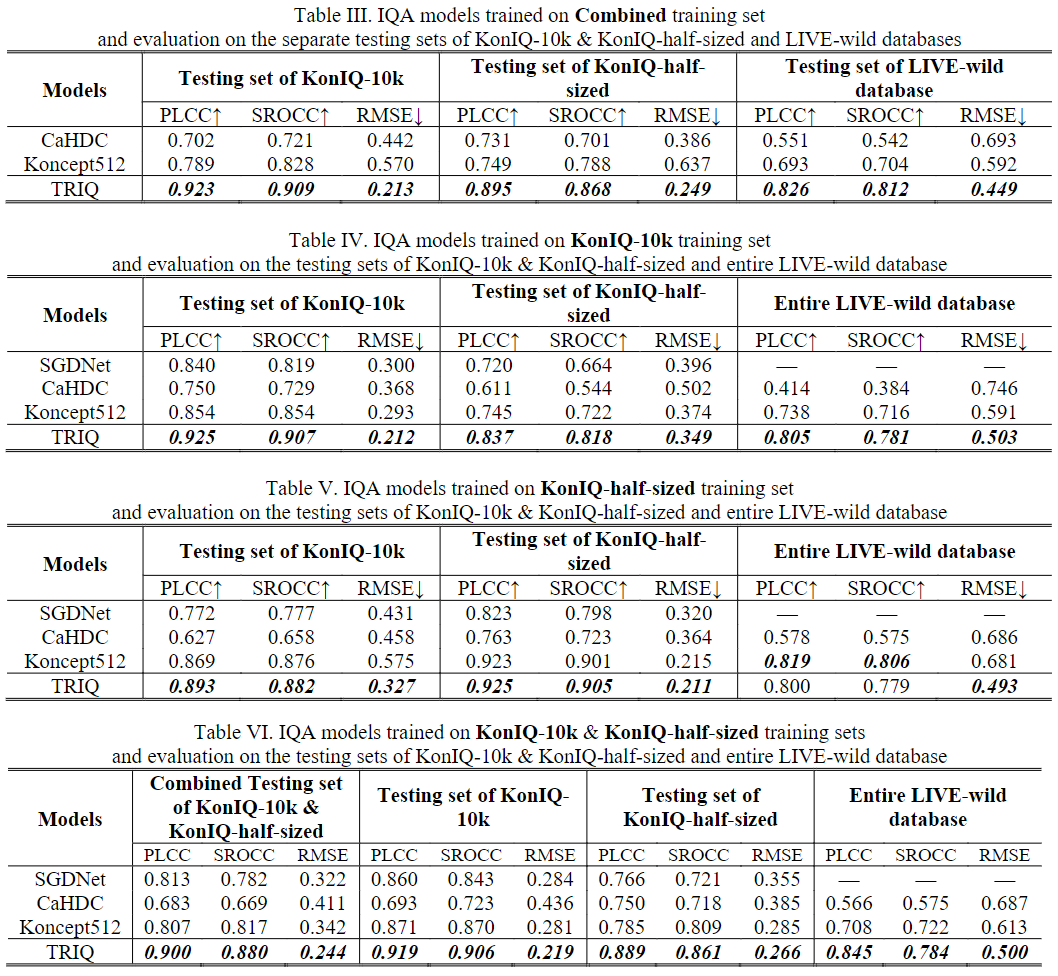
[结果分析]
相关图像质量指标以及评估图像质量指标的指标可参考[IQA]。
















 2657
2657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









