







不懂就问ABOUT PYTHON
- 问题一:Python中列表和元组、字典的区别是什么?
- 问题二:pycharm中换行符是什么
- 问题三:什么是素数,质数,合数?
- 问题四:python中单引号,双引号,三个单引号及三个双引号区别是什么
- 问题五:让注释更加醒目,标记需要去做的工作,一旦工作完成需要及时删除TODO标记
- 问题六:shebang和添加可执行权限
- 问题七:拆包语法
- 问题八:__init__,__new__代表的意义。__方法名 代表的意义。
- 问题九:什么情况下用def 方法名(self, 参数列表):
- 问题十:is与==的区别
- 问题十一:方法重写
- 问题十二:类方法,类属性;实例方法,实例属性;静态方法,静态属性区别、使用场景 和用法。
- 问题十三:如果方法内部,既需要访问实例属性,也需要访问类属性,应该定义成什么方法?
- 问题十四:关于__new__方法
- 问题十五:发布模块
- 问题十六:文件访问方式(open函数默认以只读方式打开文件,并返回文件对象)
- 问题十七:什么时候用read(),什么时候用readline()?
- 问题十八:文件和目录的管理操作,备份文件
- 问题十九:怎样在python2中使用中文
- 问题二十:eval函数(千万不要用eval直接转换input的结果)
- 问题二十一:ubuntu中文件的定位
- 问题二十二:pycharm快捷键大全
- 问题二十三:python中的getter and setter
- 问题二十四:about Decorator
- 问题二十五:Closure
- 问题二十六:新式类和旧式类的区别
- 问题二十七:操作系统在表示内存的时候,最小寻址的单位是按照字节来设置的,一个字节代表一个地址单元
- 问题二十八:Linux下MySQL的卸载与安装、查询
- 问题二十九:设置字符串格式(填充与格式化、精度与进制 )
- 问题三十:Pycharm安装matplotlib
- 问题三十一:Django数据库操作中You are trying to add a non-nullable field 'name' to contact without a default错误处理
- 问题三十二:模板标签(tags)的介绍及如何自定义模板标签
- 问题三十三:递归(自己用笔写写就能明白)
- 问题三十四:lambda表达式:
- 问题三十五:map(),reduce(),filter()
- 问题三十六:typing模块的作用
- 问题三十七:解决pyinstaller打包生成的exe运行完直接退出的问题
- 问题三十七:class, class()和class(object)的区别
问题一:Python中列表和元组、字典的区别是什么?
列表是由一系列按特定顺序排列的元素组成。元素之间没有任何关系。因为通常包含多个元素,所以一般列表的命名都是复数。用[ ]来表示列表,用,来分割其中的元素。
例如:bicycles = [‘trek’, ’cannondale’, ‘redline’]
元组是不可修改的列表。元祖看起来犹如列表,但是使用()来标识。
例如:dimensions = (200, 50)
可以将长度,宽度定义在一个元组中,从而确保他们是不能被修改的。
字典用放在{}中的一对键值对表示
例如:alien = {‘color’: ‘green’, ‘points’: ‘5’}
问题二:pycharm中换行符是什么
Linux和pycharm中 \n
Windows中 \r\n
Atom编辑器中 \r
问题三:什么是素数,质数,合数?
素数又称质数,是指一个大于1的自然数,除了1和他本身之外不能被其他自然数整除。否则称之为合数。
问题四:python中单引号,双引号,三个单引号及三个双引号区别是什么
单引号双引号都能用来表示字符串,所以
Str = ‘python is ok’
Str = “python is ok”
这两个是没有区别的。但是为了避免转义字符不好理解语义,单引号和双引号可以同时出现在一个语句中,例如:
Str = “we all know that ‘A’ and ‘B’ are two capital letters”
Str = ’we all know that “A” and “B” are two capital letters’
Str = ‘we all know that \‘A\’ and \‘B\’ are two capital letters’
问题五:让注释更加醒目,标记需要去做的工作,一旦工作完成需要及时删除TODO标记
TODO (小明)显示功能菜单
通过左下角的小方框里面的TODO选项可以很轻松地知道谁做了什么工作,便于查找。
TODO 显示功能菜单
问题六:shebang和添加可执行权限
Shebang是指在unix脚本中第一行写入编辑器路径,例如#! /usr/bin/python3。如此,可在终端中直接执行.py程序。
若遇到权限不够情况:chmod +x cards_main.py.
然后再执行./cards_main.py即可
问题七:拆包语法
在调用带有多值参数的函数时,如果希望:
将一个元组变量直接传递给args
将一个字典变量直接传递给kwargs
就可以使用拆包,简化参数传递,拆包方式是:
在元组变量前增加一个*
在字典变量前增加两个*
例如:def demo(*args, **kwargs):
Print(args)
Print(kwargs)
gl_num = (1,2,3)
gl_xiaoming = {“name”: “小明”, “age”: “18”}
demo(*gl_num, **gl_xiaoming)
运行结果为:
(1,2,3)
{“name”: “小明”, “age”: “18”}
# 对元组拆包
def return_num():
return 100, 200
num1, num2 = return_num()
print(f'num1是{num1}')
print(f'num2是{num2}')
# 对字典拆包
dict1 = {'name': '风清扬', 'age': 18, 'gender': 'male'}
a, b, c = dict1
print(a)
print(b)
print(c)
print('\n----------------------------------------')
print(dict1[a])
print(dict1[b])
print(dict1[c])
print('\n----------------------------------------')
for i in dict1:
print(f'{i}是{dict1[i]}')
console:
num1是100
num2是200
name
age
gender
----------------------------------------
风清扬
18
male
----------------------------------------
name是风清扬
age是18
gender是male
问题八:init,__new__代表的意义。__方法名 代表的意义。
__格式的方法__是python提供的内置方法/属性,各有各的含义,例如:
init:对象被初始化时会被自动调用。是专门用来定义一个类具有哪些属性的方法
new:创建对象时会被自动调用
del:对象被从内存中销毁前会被自动调用
利用好dir()内置函数,可以查看对象的所有属性及方法
__方法名 :私有属性。在对象内部使用,不希望被外部访问到。
问题九:什么情况下用def 方法名(self, 参数列表):
Tip:视频在H:\python研究\python基础班\1-3 面向对象\01-面向对象基础\010-self-02-利用self在类封装的方法中输出对象属性.flv
当定义只包含方法的类时,语法格式如下(封装在类中的方法第一个参数必须是self):
class 类名:
def 方法1(slef,参数列表):
pass
def 方法2(self,参数列表):
pass
方法的定义格式和之前学习过的函数几乎一样,区别在于第一个参数必须是self。哪一个对象调用的方法,self就是哪一个对象的引用。在类封装的方法内部,self就表示当前调用方法的对象自己。调用方法时,不需要传递self参数。在方法内部,可以通过self.访问对象的属性。也可以通过self.调用其他的对象方法。
class Cat:
def eat(self):
print(“%s 爱吃鱼”% self.name)
tom = Cat()
tom.name = “Tom”
tom.eat()
lazy_cat = Cat()
lazy_cat.name = “大懒猫”
lazy_cat.eat()
注意:tom.name = “Tom”在类的外部给对象添加属性不推荐使用,因为他改变的是方法内的变量。真正的项目中容易混乱。
问题十:is与==的区别
is是判断两个变量引用对象是否为同一个。==是判断两个引用变量的值是否相等。
问题十一:方法重写
当父类的方法实现不能满足子类需求时,可以对方法进行重写(override)
重写父类方法有两种情况:
1.覆盖父类的方法
如果在开发中,父类的方法实现和子类的方法实现完全不同,就可以使用覆盖的方式,在子类中重新编写父类的方法实现。具体实现方式:在子类中定义一个和父类同名的方法并且重写此方法。在运行时,只会调用子类重写的方法,而不会再调用父类封装的方法。
2.对父类的方法进行扩展
如果在开发中子类的方法实现中包含父类的方法实现,父类原本封装的方法实现是子类方法的一部分,就可以使用扩展方式。
1.在子类中重写父类的方法
2.在需要的位置使用super().父类方法来调用父类方法的执行
3.代码其他的位置针对子类的需求,编写子类特有的代码实现。
问题十二:类方法,类属性;实例方法,实例属性;静态方法,静态属性区别、使用场景 和用法。
静态方法:如果在方法内部不需要访问实例属性和类属性,那么就把这个方法封装成一个静态方法,通过类名调用静态方法,不需要创建对象。
实例方法:如果方法内部需要访问实例属性时,就把这个方法封装成一个实例方法。
实例属性:应该在初始化内部方法中定义。即在__init__()中定义
类方法:如果方法内部只访问类属性或只调用类方法时,才把这个方法封装成类方法
例如:
class game(object):
#历史最高分
top_score = 0 #类属性
def init(self, player_name): #定义一个初始化方法
self.player_name = player_name #实例属性
@staticmethod
def show_help(): # 定义一个静态方法
Print(“帮助信息:让僵尸进入大门”)
@classmethod
def show_top_score(cls): # 类方法
print(“历史记录 %d”% cls.top_score)
def start_game(self): # 实例方法
print(“%s 开始游戏啦…”% self.player_name)
- 查看游戏帮助信息
game.show_help()
- 查看历史最高分
game.show_top_score()
- 创建游戏对象
game = Game(“小明”)
game.start_game()
问题十三:如果方法内部,既需要访问实例属性,也需要访问类属性,应该定义成什么方法?
应该封装成一个实例方法。因为类只有一个,在实例方法内部可以使用类名.属性名访问类属性。
问题十四:关于__new__方法
参考H:\python研究\python基础班\1-3 面向对象\08-单例模式\060-单例-03-重写new方法
问题十五:发布模块
参考H:\python研究\python基础班\1-3 面向对象\10-模块和包\083-制作模块-02-制作模块压缩包
问题十六:文件访问方式(open函数默认以只读方式打开文件,并返回文件对象)
r:以只读方式打开文件。文件指针将会放在文件的开头,这是默认模式。如果文件不存在,则抛出异常
w:以只写方式打开文件。如果文件存在会被覆盖,如果文件不存在,会创建新文件。
a:以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果不存在,创建新文件进行写入。
r+:以读写方式打开文件。文件指针将会放在文件的开头。如果文件不存在,抛出异常。
w+:以读写方式打开文件。如果文件存在会覆盖。如果不存在,创建新文件。
a+:以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入。
问题十七:什么时候用read(),什么时候用readline()?
read()方法默认会把文件的所有内容一次性读取到内存,如果文件太大,对内存的占用会非常严重。
readline()可以一次读取一行内容,方法执行后,会把文件指针移动到下一行,准备再次读取。读取大文件时应该这样:
打开文件
file = open(“readme”)
While True:
#读取一行内容
text - file.radline()
#判断是否读到内容
if not text:
break
每读取到一行的末尾已经有了一个\n
print(text, end = “”)
关闭文件
file.close()
问题十八:文件和目录的管理操作,备份文件
Python rfind() 返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。
如果⽤户输⼊ .txt ,这是⼀个⽆效⽂件,程序如何更改才能限制只有有效的⽂件名才能备份?
答:添加条件判断即可。
old_name = input('请输⼊您要备份的⽂件名:')
index = old_name.rfind('.')
if index > 0:
postfix = old_name[index:]
new_name = old_name[:index] + '[备份]' + postfix
old_f = open(old_name, 'rb')
new_f = open(new_name, 'wb')
while True:
con = old_f.read(1024)
if len(con) == 0:
break
new_f.write(con)
old_f.close()
new_f.close()
H:\python研究\python基础班\1-3 面向对象\11-文件操作\095-导入os模块执行文件和目录管理操作
问题十九:怎样在python2中使用中文
Python默认使用ASCII编码格式
Python3默认使用UTF-8编码格式
在Python2文件的第一行增加以下代码,解释器会以UTF-8编码来处理python文件
- coding:utf8 -
这个方式是官方推荐使用的。也可以用:
coding=utf8
Python2中,引号前面的u告诉解释器这是一个utf8编码格式的字符串
hello_str = u”hello世界”
print(hello_str)
问题二十:eval函数(千万不要用eval直接转换input的结果)
将字符串当成有效的表达式来求值并返回计算结果
详情见:H:\python研究\python基础班\1-3 面向对象\13-内建函数eval
问题二十一:ubuntu中文件的定位
1.whereis 文件名
特点:快速,但是是模糊查找,例如 找 #whereis mysql 它会把mysql,mysql.ini,mysql.*所在的目录都找出来.
2.find / -name 文件名
特点:准确,但速度慢,消耗资源大,例如我想找到php.ini的准确位置,就需要用
#find / -name php.ini
3.locate 文件名
强力推荐的方法,最快,最好的方法.
注意:第一次使用该命令,可能需要更新数据库,按照提示的命令执行一下就好了.
问题二十二:pycharm快捷键大全
1、编辑
Ctrl + Space 基本的代码完成(类、方法、属性)
Ctrl + Alt + Space 快速导入任意类
Ctrl + Shift + Enter 语句完成
Ctrl + P 参数信息(在方法中调用参数)
Ctrl + Q 快速查看文档
F1 外部文档
Shift + F1 外部文档,进入web文档主页
Ctrl + Shift + Z --> Redo 重做
Ctrl + 鼠标 简介/进入代码定义
Ctrl + F1 显示错误描述或警告信息
Alt + Insert 自动生成代码
Ctrl + O 重新方法
Ctrl + Alt + T 选中
Ctrl + / 行注释/取消行注释
Ctrl + Shift + / 块注释
Ctrl + W 选中增加的代码块
Ctrl + Shift + W 回到之前状态
Ctrl + Shift + ]/[ 选定代码块结束、开始
Alt + Enter 快速修正
Ctrl + Alt + L 代码格式化
Ctrl + Alt + O 优化导入
Ctrl + Alt + I 自动缩进
Tab / Shift + Tab 缩进、不缩进当前行
Ctrl+X/Shift+Delete 剪切当前行或选定的代码块到剪贴板
Ctrl+C/Ctrl+Insert 复制当前行或选定的代码块到剪贴板
Ctrl+V/Shift+Insert 从剪贴板粘贴
Ctrl + Shift + V 从最近的缓冲区粘贴
Ctrl + D 复制选定的区域或行
Ctrl + Y 删除选定的行
Ctrl + Shift + J 添加智能线
Ctrl + Enter 智能线切割
Shift + Enter 另起一行
Ctrl + Shift + U 在选定的区域或代码块间切换
Ctrl + Delete 删除到字符结束
Ctrl + Backspace 删除到字符开始
Ctrl + Numpad+/- 展开/折叠代码块(当前位置的:函数,注释等)
Ctrl + shift + Numpad+/- 展开/折叠所有代码块
Ctrl + F4 关闭运行的选项卡
2、查找/替换(Search/Replace)
F3 下一个
Shift + F3 前一个
Ctrl + R 替换
Ctrl + Shift + F 或者连续2次敲击shift 全局查找{可以在整个项目中查找某个字符串什么的,如查找某个函数名字符串看之前是怎么使用这个函数的}
Ctrl + Shift + R 全局替换
3、运行(Running)
Alt + Shift + F10 运行模式配置
Alt + Shift + F9 调试模式配置
Shift + F10 运行
Shift + F9 调试
Ctrl + Shift + F10 运行编辑器配置
Ctrl + Alt + R 运行manage.py任务
4、调试(Debugging)
F8 跳过
F7 进入
Shift + F8 退出
Alt + F9 运行游标
Alt + F8 验证表达式
Ctrl + Alt + F8 快速验证表达式
F9 恢复程序
Ctrl + F8 断点开关
Ctrl + Shift + F8 查看断点
5、导航(Navigation)
Ctrl + N 跳转到类
Ctrl + Shift + N 跳转到符号
Alt + Right/Left 跳转到下一个、前一个编辑的选项卡
F12 回到先前的工具窗口
Esc 从工具窗口回到编辑窗口
Shift + Esc 隐藏运行的、最近运行的窗口
Ctrl + Shift + F4 关闭主动运行的选项卡
Ctrl + G 查看当前行号、字符号
Ctrl + E 当前文件弹出,打开最近使用的文件列表
Ctrl+Alt+Left/Right 后退、前进
Ctrl+Shift+Backspace 导航到最近编辑区域
Alt + F1 查找当前文件或标识
Ctrl+B / Ctrl+Click 跳转到声明
Ctrl + Alt + B 跳转到实现
Ctrl + Shift + I 查看快速定义
Ctrl + Shift + B 跳转到类型声明
Ctrl + U 跳转到父方法、父类
Alt + Up/Down 跳转到上一个、下一个方法
Ctrl + ]/[ 跳转到代码块结束、开始
Ctrl + F12 弹出文件结构
Ctrl + H 类型层次结构
Ctrl + Shift + H 方法层次结构
Ctrl + Alt + H 调用层次结构
F2 / Shift + F2 下一条、前一条高亮的错误
F4 / Ctrl + Enter 编辑资源、查看资源
Alt + Home 显示导航条F11书签开关
Ctrl + Shift + F11 书签助记开关
Ctrl + #[0-9] 跳转到标识的书签
Shift + F11 显示书签
6、搜索相关(Usage Search)
Alt + F7/Ctrl + F7 文件中查询用法
Ctrl + Shift + F7 文件中用法高亮显示
Ctrl + Alt + F7 显示用法
7、重构(Refactoring)
F5复制F6剪切
Alt + Delete 安全删除
Shift + F6 重命名
Ctrl + F6 更改签名
Ctrl + Alt + N 内联
Ctrl + Alt + M 提取方法
Ctrl + Alt + V 提取属性
Ctrl + Alt + F 提取字段
Ctrl + Alt + C 提取常量
Ctrl + Alt + P 提取参数
8、控制VCS/Local History
Ctrl + K 提交项目
Ctrl + T 更新项目
Alt + Shift + C 查看最近的变化
Alt + BackQuote(’)VCS 快速弹出
9、模版(Live Templates)
Ctrl + Alt + J 当前行使用模版
Ctrl +J 插入模版
10、基本(General)
Alt + #[0-9] 打开相应的工具窗口
Ctrl + Alt + Y 同步
Ctrl + Shift + F12 最大化编辑开关
Alt + Shift + F 添加到最喜欢
Alt + Shift + I 根据配置检查当前文件
Ctrl + BackQuote(’) 快速切换当前计划
Ctrl + Alt + S 打开设置页
Ctrl + Shift + A 查找编辑器里所有的动作
Ctrl + Tab 在窗口间进行切换
问题二十三:python中的getter and setter
在编写java或者scala的时候,对一个类的变量等经常用到getter setter方法,在python里面同样也有对应的实例:
可以直接用 类.变量 的方式获取数据实现getter,类.变量(值)的方式实现setter方法:
定义方法如下:使用@property 和@xx.setter 标注的变量名的同名定义方法前即可实现
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
调用也相对简单:
s = Student()
s.score = 60 # OK,实际转化为s.set_score(60)
s.score # OK,实际转化为s.get_score()
60
s.score = 9999
Traceback (most recent call last):
…
ValueError: score must between 0 ~ 100!
问题二十四:about Decorator
在学习Python的过程中,我相信有很多人和我一样,对Python的装饰器一直觉得很困惑,我也是困惑了好久,并通过思考和查阅才能略有领悟,我希望以下的内容会对你有帮助,我也努力通过通俗的方式使得对Python装饰器的理解更加的透彻。在文中如有遗漏和不足,欢迎交流和指点。
允许转载并注明出处:http://blog.csdn.net/u013471155
很多人对装饰器难以理解,原因是由于以下三点内容没有搞清楚:
1.关于函数“变量”(或“变量”函数)的理解
2.关于高阶函数的理解
3.关于嵌套函数的理解
那么如果能对以上的问题一一攻破,同时遵循装饰器的基本原则,相信会对装饰器有个很好的理解的。那么我们先来看以下装饰器的目的及其原则。
1、装饰器
装饰器实际上就是为了给某程序增添功能,但该程序已经上线或已经被使用,那么就不能大批量的修改源代码,这样是不科学的也是不现实的,因为就产生了装饰器,使得其满足:
1.不能修改被装饰的函数的源代码
2.不能修改被装饰的函数的调用方式
3.满足1、2的情况下给程序增添功能
那么根据需求,同时满足了这三点原则,这才是我们的目的。因为,下面我们从解决这三点原则入手来理解装饰器。
等等,我要在需求之前先说装饰器的原则组成:
< 函数+实参高阶函数+返回值高阶函数+嵌套函数+语法糖 = 装饰器 >
这个式子是贯穿装饰器的灵魂所在!
2、需求的实现
假设有代码:
improt time
def test():
time.sleep(2)
print(“test is running!”)
test()
很显然,这段代码运行的结果一定是:等待约2秒后,输出
test is running
那么要求在满足三原则的基础上,给程序添加统计运行时间(2 second)功能
在行动之前,我们先来看一下文章开头提到的原因1(关于函数“变量”(或“变量”函数)的理解)
2.1、函数“变量”(或“变量”函数)
假设有代码:
x = 1
y = x
def test1():
print(“Do something”)
test2 = lambda x:x*2
那么在内存中,应该是这样的:
很显然,函数和变量是一样的,都是“一个名字对应内存地址中的一些内容”
那么根据这样的原则,我们就可以理解两个事情:
1.test1表示的是函数的内存地址
2.test1()就是调用对在test1这个地址的内容,即函数
如果这两个问题可以理解,那么我们就可以进入到下一个原因(关于高阶函数的理解)
2.2高阶函数
那么对于高阶函数的形式可以有两种:
1.把一个函数名当作实参传给另外一个函数(“实参高阶函数”)
2.返回值中包含函数名(“返回值高阶函数”)
那么这里面所说的函数名,实际上就是函数的地址,也可以认为是函数的一个标签而已,并不是调用,是个名词。如果可以把函数名当做实参,那么也就是说可以把函数传递到另一个函数,然后在另一个函数里面做一些操作,根据这些分析来看,这岂不是满足了装饰器三原则中的第一条,即不修改源代码而增加功能。那我们看来一下具体的做法:
还是针对上面那段代码:
improt time
def test():
time.sleep(2)
print(“test is running!”)
def deco(func):
start = time.time()
func() #2
stop = time.time()
print(stop-start)
deco(test) #1
我们来看一下这段代码,在#1处,我们把test当作实参传递给形参func,即func=test。注意,这里传递的是地址,也就是此时func也指向了之前test所定义的那个函数体,可以说在deco()内部,func就是test。在#2处,把函数名后面加上括号,就是对函数的调用(执行它)。因此,这段代码运行结果是:
test is running!
the run time is 3.0009405612945557
我们看到似乎是达到了需求,即执行了源程序,同时也附加了计时功能,但是这只满足了原则1(不能修改被装饰的函数的源代码),但这修改了调用方式。假设不修改调用方式,那么在这样的程序中,被装饰函数就无法传递到另一个装饰函数中去。
那么再思考,如果不修改调用方式,就是一定要有test()这条语句,那么就用到了第二种高阶函数,即返回值中包含函数名
如下代码:
improt time
def test():
time.sleep(2)
print(“test is running!”)
def deco(func):
print(func)
return func
t = deco(test) #3
#t()#4
test()
我们看这段代码,在#3处,将test传入deco(),在deco()里面操作之后,最后返回了func,并赋值给t。因此这里test => func => t,都是一样的函数体。最后在#4处保留了原来的函数调用方式。
看到这里显然会有些困惑,我们的需求不是要计算函数的运行时间么,怎么改成输出函数地址了。是因为,单独采用第二张高阶函数(返回值中包含函数名)的方式,并且保留原函数调用方式,是无法计时的。如果在deco()里计时,显然会执行一次,而外面已经调用了test(),会重复执行。这里只是为了说明第二种高阶函数的思想,下面才真的进入重头戏。
2.3 嵌套函数
嵌套函数指的是在函数内部定义一个函数,而不是调用,如:
def func1():
def func2():
pass
而不是
def func1():
func2()
另外还有一个题外话,函数只能调用和它同级别以及上级的变量或函数。也就是说:里面的能调用和它缩进一样的和他外部的,而内部的是无法调用的。
那么我们再回到我们之前的那个需求,想要统计程序运行时间,并且满足三原则。
代码:
improt time
def timer(func) #5
def deco():
start = time.time()
func()
stop = time.time()
print(stop-start)
return deco
test = timer(test) #6
def test():
time.sleep(2)
print(“test is running!”)
test() #7
这段代码可能会有些困惑,怎么忽然多了这么多,暂且先接受它,分析一下再来说为什么是这样。
首先,在#6处,把test作为参数传递给了timer(),此时,在timer()内部,func = test,接下来,定义了一个deco()函数,当并未调用,只是在内存中保存了,并且标签为deco。在timer()函数的最后返回deco()的地址deco。
然后再把deco赋值给了test,那么此时test已经不是原来的test了,也就是test原来的那些函数体的标签换掉了,换成了deco。那么在#7处调用的实际上是deco()。
那么这段代码在本质上是修改了调用函数,但在表面上并未修改调用方式,而且实现了附加功能。
那么通俗一点的理解就是:
把函数看成是盒子,test是小盒子,deco是中盒子,timer是大盒子。程序中,把小盒子test传递到大盒子temer中的中盒子deco,然后再把中盒子deco拿出来,打开看看(调用)
这样做的原因是:
我们要保留test(),还要统计时间,而test()只能调用一次(调用两次运行结果会改变,不满足),再根据函数即“变量”,那么就可以通过函数的方式来回闭包。于是乎,就想到了,把test传递到某个函数,而这个函数内恰巧内嵌了一个内函数,再根据内嵌函数的作用域(可以访问同级及以上,内嵌函数可以访问外部参数),把test包在这个内函数当中,一起返回,最后调用这个返回的函数。而test传递进入之后,再被包裹出来,显然test函数没有弄丢(在包裹里),那么外面剩下的这个test标签正好可以替代这个包裹(内含test())。
至此,一切皆合,大功告成,单只差一步。
3、 真正的装饰器
根据以上分析,装饰器在装饰时,需要在每个函数前面加上:
test = timer(test)
显然有些麻烦,Python提供了一种语法糖,即:
@timer
这两句是等价的,只要在函数前加上这句,就可以实现装饰作用。
以上为无参形式
4、装饰有参函数
improt time
def timer(func)
def deco():
start = time.time()
func()
stop = time.time()
print(stop-start)
return deco
@timer
def test(parameter): #8
time.sleep(2)
print(“test is running!”)
test()
\对于一个实际问题,往往是有参数的,如果要在#8处,给被修饰函数加上参数,显然这段程序会报错的。错误原因是test()在调用的时候缺少了一个位置参数的。而我们知道test = func = deco,因此test()=func()=deco()
,那么当test(parameter)有参数时,就必须给func()和deco()也加上参数,为了使程序更加有扩展性,因此在装饰器中的deco()和func(),加如了可变参数*agrs和 **kwargs。
完整代码如下:
improt time
def timer(func)
def deco(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
stop = time.time()
print(stop-start)
return deco
@timer
def test(parameter): #8
time.sleep(2)
print(“test is running!”)
test()
那么我们再考虑个问题,如果原函数test()的结果有返回值呢?比如:
def test(parameter):
time.sleep(2)
print(“test is running!”)
return “Returned value”
那么面对这样的函数,如果用上面的代码来装饰,最后一行的test()实际上调用的是deco()。有人可能会问,func()不就是test()么,怎么没返回值呢?
其实是有返回值的,但是返回值返回到deco()的内部,而不是test()即deco()的返回值,那么就需要再返回func()的值,因此就是:
def timer(func)
def deco(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)#9
stop = time.time()
print(stop-start)
return res#10
return deco
其中,#9的值在#10处返回。
完整程序为:
improt time
def timer(func)
def deco(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
stop = time.time()
print(stop-start)
return res
return deco
@timer
def test(parameter): #8
time.sleep(2)
print(“test is running!”)
return “Returned value”
test()
5、带参数的装饰器
又增加了一个需求,一个装饰器,对不同的函数有不同的装饰。那么就需要知道对哪个函数采取哪种装饰。因此,就需要装饰器带一个参数来标记一下。例如:
@decorator(parameter = value)
比如有两个函数:
def task1():
time.sleep(2)
print(“in the task1”)
def task2():
time.sleep(2)
print(“in the task2”)
task1()
task2()
要对这两个函数分别统计运行时间,但是要求统计之后输出:
the task1/task2 run time is : 2.00……
于是就要构造一个装饰器timer,并且需要告诉装饰器哪个是task1,哪个是task2,也就是要这样:
@timer(parameter=‘task1’) #
def task1():
time.sleep(2)
print(“in the task1”)
@timer(parameter=‘task2’) #
def task2():
time.sleep(2)
print(“in the task2”)
task1()
task2()
那么方法有了,但是我们需要考虑如何把这个parameter参数传递到装饰器中,我们以往的装饰器,都是传递函数名字进去,而这次,多了一个参数,要怎么做呢?
于是,就想到再加一层函数来接受参数,根据嵌套函数的概念,要想执行内函数,就要先执行外函数,才能调用到内函数,那么就有:
def timer(parameter): #
print(“in the auth :”, parameter)
def outer_deco(func): #
print(“in the outer_wrapper:”, parameter)
def deco(*args, **kwargs):
return deco
return outer_deco
首先timer(parameter),接收参数parameter=’task1/2’,而@timer(parameter)也恰巧带了括号,那么就会执行这个函数, 那么就是相当于:
timer = timer(parameter)
task1 = timer(task1)
后面的运行就和一般的装饰器一样了:
import time
def timer(parameter):
def outer_wrapper(func):
def wrapper(*args, **kwargs):
if parameter == ‘task1’:
start = time.time()
func(*args, **kwargs)
stop = time.time()
print(“the task1 run time is :”, stop - start)
elif parameter == ‘task2’:
start = time.time()
func(*args, **kwargs)
stop = time.time()
print(“the task2 run time is :”, stop - start)
return wrapper
return outer_wrapper
@timer(parameter=‘task1’)
def task1():
time.sleep(2)
print(“in the task1”)
@timer(parameter=‘task2’)
def task2():
time.sleep(2)
print(“in the task2”)
task1()
task2()
问题二十五:Closure
Python-闭包详解
在函数编程中经常用到闭包。闭包是什么,它是怎么产生的及用来解决什么问题呢。给出字面的定义先:闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境)(想想Erlang的外层函数传入一个参数a, 内层函数依旧传入一个参数b, 内层函数使用a和b, 最后返回内层函数)。这个从字面上很难理解,特别对于一直使用命令式语言进行编程的程序员们。本文将结合实例代码进行解释。
函数是什么
地球人都知道:函数只是一段可执行代码,编译后就“固化”了,每个函数在内存中只有一份实例,得到函数的入口点便可以执行函数了。在函数式编程语言中,函 数是一等公民(First class value:第一类对象,我们不需要像命令式语言中那样借助函数指针,委托操作函数),函数可以作为另一个函数的参数或返回值,可以赋给一个变量。函数可 以嵌套定义,即在一个函数内部可以定义另一个函数,有了嵌套函数这种结构,便会产生闭包问题。如:
def ExFunc(n):
sum=n
def InsFunc():
return sum+1
return InsFunc
myFunc=ExFunc(10)
myFunc()
11
myAnotherFunc=ExFunc(20)
myAnotherFunc()
21
myFunc()
11
myAnotherFunc()
21
在这段程序中,函数InsFunc是函数ExFunc的内嵌函数,并且是ExFunc函数的返回值。我们注意到一个问题:内嵌函数InsFunc中 引用到外层函数中的局部变量sum,IronPython会这么处理这个问题呢?先让我们来看看这段代码的运行结果。当我们调用分别由不同的参数调用 ExFunc函数得到的函数时(myFunc(),myAnotherFunc()),得到的结果是隔离的,也就是说每次调用ExFunc函数后都将生成并保存一个新的局部变量sum。其实这里ExFunc函数返回的就是闭包。
引用环境
按照命令式语言的规则,ExFunc函数只是返回了内嵌函数InsFunc的地址,在执行InsFunc函数时将会由于在其作用域内找不到sum变量而出 错。而在函数式语言中,当内嵌函数体内引用到体外的变量时,将会把定义时涉及到的引用环境和函数体打包成一个整体(闭包)返回。现在给出引用环境的定义就 容易理解了:引用环境是指在程序执行中的某个点所有处于活跃状态的约束(一个变量的名字和其所代表的对象之间的联系)所组成的集合。闭包的使用和正常的函 数调用没有区别。
由于闭包把函数和运行时的引用环境打包成为一个新的整体,所以就解决了函数编程中的嵌套所引发的问题。如上述代码段中,当每次调用ExFunc函数 时都将返回一个新的闭包实例,这些实例之间是隔离的,分别包含调用时不同的引用环境现场。不同于函数,闭包在运行时可以有多个实例,不同的引用环境和相同 的函数组合可以产生不同的实例。
一,定义
python中的闭包从表现形式上定义(解释)为:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure).这个定义是相对直白的,好理解的,不像其他定义那样学究味道十足(那些学究味道重的解释,在对一个名词的解释过程中又充满了一堆让人抓狂的其他陌生名词,不适合初学者)。下面举一个简单的例子来说明。
def addx(x): >>> def adder(y): return x + y >>> return adder >>> c = addx(8) >>> type© <type ‘function’>
c.name ‘adder’
c(10) 18
结合这段简单的代码和定义来说明闭包:
如果在一个内部函数里:adder(y)就是这个内部函数,
对在外部作用域(但不是在全局作用域)的变量进行引用:x就是被引用的变量,x在外部作用域addx里面,但不在全局作用域里,
则这个内部函数adder就是一个闭包。
再稍微讲究一点的解释是,闭包=函数块+定义函数时的环境,adder就是函数块,x就是环境,当然这个环境可以有很多,不止一个简单的x。
二,使用闭包注意事项
1,闭包中是不能修改外部作用域的局部变量的
def foo():
… m = 0
… def foo1():
… m = 1
… print m
…
… print m
… foo1()
… print m
… >>> foo()
0 1
0
从执行结果可以看出,虽然在闭包里面也定义了一个变量m,但是其不会改变外部函数中的局部变量m。
2,以下这段代码是在python中使用闭包时一段经典的错误代码
def foo():
a = 1
def bar():
a = a + 1
return a
return bar
这段程序的本意是要通过在每次调用闭包函数时都对变量a进行递增的操作。但在实际使用时
c = foo() >>> print c()
Traceback (most recent call last):
File “”, line 1, in
File “”, line 4, in bar
UnboundLocalError: local variable ‘a’ referenced before assignment
这是因为在执行代码 c = foo()时,python会导入全部的闭包函数体bar()来分析其的局部变量,python规则指定所有在赋值语句左面的变量都是局部变量,则在闭包bar()中,变量a在赋值符号"="的左面,被python认为是bar()中的局部变量。再接下来执行print c()时,程序运行至a = a + 1时,因为先前已经把a归为bar()中的局部变量,所以python会在bar()中去找在赋值语句右面的a的值,结果找不到,就会报错。解决的方法很简单
def foo():
a = [1]
def bar():
a[0] = a[0] + 1
return a[0]
return bar
只要将a设定为一个容器就可以了。这样使用起来多少有点不爽,所以在python3以后,在a = a + 1 之前,使用语句nonloacal a就可以了,该语句显式的指定a不是闭包的局部变量。
3,还有一个容易产生错误的事例也经常被人在介绍python闭包时提起,我一直都没觉得这个错误和闭包有什么太大的关系,但是它倒是的确是在python函数式编程是容易犯的一个错误,我在这里也不妨介绍一下。先看下面这段代码
for i in range(3):
print i
在程序里面经常会出现这类的循环语句,Python的问题就在于,当循环结束以后,循环体中的临时变量i不会销毁,而是继续存在于执行环境中。还有一个python的现象是,python的函数只有在执行时,才会去找函数体里的变量的值。
flist = [] for i in range(3):
def foo(x): print x + i
flist.append(foo) for f in flist:
f(2)
可能有些人认为这段代码的执行结果应该是2,3,4.但是实际的结果是4,4,4。这是因为当把函数加入flist列表里时,python还没有给i赋值,只有当执行时,再去找i的值是什么,这时在第一个for循环结束以后,i的值是2,所以以上代码的执行结果是4,4,4.
解决方法也很简单,改写一下函数的定义就可以了。
for i in range(3):
def foo(x,y=i): print x + y
flist.append(foo)
三,作用
说了这么多,不免有人要问,那这个闭包在实际的开发中有什么用呢?闭包主要是在函数式开发过程中使用。以下介绍两种闭包主要的用途。
用途1,当闭包执行完后,仍然能够保持住当前的运行环境。
比如说,如果你希望函数的每次执行结果,都是基于这个函数上次的运行结果。我以一个类似棋盘游戏的例子来说明。假设棋盘大小为50*50,左上角为坐标系原点(0,0),我需要一个函数,接收2个参数,分别为方向(direction),步长(step),该函数控制棋子的运动。棋子运动的新的坐标除了依赖于方向和步长以外,当然还要根据原来所处的坐标点,用闭包就可以保持住这个棋子原来所处的坐标。
origin = [0, 0] # 坐标系统原点
legal_x = [0, 50] # x轴方向的合法坐标
legal_y = [0, 50] # y轴方向的合法坐标 def create(pos=origin):
def player(direction,step):
# 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等
# 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。
new_x = pos[0] + direction[0]*step
new_y = pos[1] + direction[1]*step
pos[0] = new_x
pos[1] = new_y
#注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过
return pos
return player
player = create() # 创建棋子player,起点为原点 print player([1,0],10) # 向x轴正方向移动10步 print player([0,1],20) # 向y轴正方向移动20步 print player([-1,0],10) # 向x轴负方向移动10步
输出为
[10, 0]
[10, 20]
[0, 20]
用途2,闭包可以根据外部作用域的局部变量来得到不同的结果,这有点像一种类似配置功能的作用,我们可以修改外部的变量,闭包根据这个变量展现出不同的功能。比如有时我们需要对某些文件的特殊行进行分析,先要提取出这些特殊行。
def make_filter(keep):
def the_filter(file_name):
file = open(file_name)
lines = file.readlines()
file.close()
filter_doc = [i for i in lines if keep in i]
return filter_doc
return the_filter
如果我们需要取得文件"result.txt"中含有"pass"关键字的行,则可以这样使用例子程序
filter = make_filter(“pass”)
filter_result = filter(“result.txt”)
以上两种使用场景,用面向对象也是可以很简单的实现的,但是在用Python进行函数式编程时,闭包对数据的持久化以及按配置产生不同的功能,是很有帮助的。
参考:http://www.cnblogs.com/Jifangliang/archive/2008/08/05/1260602.html
参考:http://blog.csdn.net/marty_fu/article/details/7679297
问题二十六:新式类和旧式类的区别
主要是继承方式不同。
例如:class A:
class B(A):
class C(A):
class D(B, C):
d = D()
那么d.a怎么找a?
新式类:先找B,再找C,最后找A
旧式类:先找B,再找A。
问题二十七:操作系统在表示内存的时候,最小寻址的单位是按照字节来设置的,一个字节代表一个地址单元
问题二十八:Linux下MySQL的卸载与安装、查询
PS:重启/打开/关闭MySQL的方法是:sudo service mysql restart/start/stop
卸载:删除mysql
sudo apt-get autoremove --purge mysql-server-5.7
sudo apt-get remove mysql-server
sudo apt-get autoremove mysql-server
sudo apt-get remove mysql-common
上面的可能会有些是多余的,之后需要清理残余数据
dpkg -l |grep ^rc|awk ‘{print $2}’ |sudo xargs dpkg -P
安装:看自己是否已经安装过了mysql
命令: sudo netstat -tap | grep mysql
如果无任何反应说明没有安装,接下来就可以安装mysql的sever和client
命令:sudo apt-get install mysql-server
sudo apt-get install mysql-client 会出现下面的界面然后输入y
就行了。过程中会让你输入数据库的密码按照自己的喜好添加不要忘了就好
sudo apt-get install libmysql+±dev
问题:
1、sudo apt-get install mysql-server mysql-client正在读取软件包列表… 完成
正在分析软件包的依赖关系树
正在读取状态信息… 完成
有一些软件包无法被安装。如果您用的是 unstable 发行版,这也许是
因为系统无法达到您要求的状态造成的。该版本中可能会有一些您需要的软件
包尚未被创建或是它们已被从新到(Incoming)目录移出。
下列信息可能会对解决问题有所帮助:
下列软件包有未满足的依赖关系:
mysql-client : 依赖: mysql-client-5.5 但是它将不会被安装
mysql-server : 依赖: mysql-server-5.5 但是它将不会被安装
E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破坏了软件包间的依赖关系。
解决方法:
sudo apt-get install mysql-client-core-5.7
2、MySQL安装、安装时未提示输入密码、如何修改密码小结
打开一个文件sudo vim /etc/mysql/debian.cnf
在这个文件里面有着MySQL默认的用户名和用户密码,
最最重要的是:用户名默认的不是root,而是debian-sys-maint,如下所示
Automatically generated for Debian scripts. DO NOT TOUCH!
[client]
host = localhost
user = debian-sys-maint
password = Z1fVrmTiZNxxw29o
socket = /var/run/mysqld/mysqld.sock
[mysql_upgrade]
host = localhost
user = debian-sys-maint
password = Z1fVrmTiZNxxw29o
socket = /var/run/mysqld/mysqld.sock
密码会随即给一个很复杂的,这个时候,要进入MySQL的话,就是需要在终端把root更改为debian-sys-maint,如下代码
mysql -u debian-sys-maint -p
然后终端会提示你输入密码
Enter password:
这是输入文件中的密码即可成功登陆。
当然了,这之后就要修改密码了,毕竟密码太难记。
经过度娘的指导,我所安装的版本是5.7,所以password字段已经被删除,取而代之的是authentication_string字段,所以要更改密码:
mysql> update mysql.user set authentication_string=password(‘password’) where user='root’and Host = ‘localhost’;
如果显示:
Query OK, 1 row affected, 1 warning (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 1
则代表成功修改,之后需要*重启**MySQL,方可登录成功。
问题二十九:设置字符串格式(填充与格式化、精度与进制 )
————————————————
版权声明:本文为CSDN博主「旅立の涯秸」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
————————————————
原文链接:https://blog.csdn.net/jamfiy/article/details/87916657
所有标准序列操作(索引、切片、乘法、成员资格检查、长度、最小值和最大值)都适用于字符串,但别忘了字符串是不可变的,因此所有的元素赋值和切片赋值都是非法的。
website = ‘http://www.python.org’
website[-3:] = ‘com’
Traceback (most recent call last):
File “<pyshell#19>”, line 1, in ?
website[-3:] = ‘com’
TypeError: object doesn’t support slice assignment
设置字符串的格式
1.字符串格式运算符——百分号%
Python提供了多种字符串格式设置方法。以前,主要的解决方案是使用字符串格式设置运算符——百分号。在%左边指定一个字符串(格式字符串),并在右边指定要设置其格式的值。指定要设置其格式的值时,可使用单个值(如字符串或数字),可使用元组(如果要设置多个值的格式),还可使用字典,其中最常见的是元组。
format = “Hello, %s.% s enough for ya?”
values = (‘world’, ‘Hot’)
format values %
‘Hello, world. Hot enough for ya?’
上述格式字符串中的%s称为转换说明符,指出了要将值插入什么地方。s意味着将值视为字符串进行格式设置。如果指定的值不是字符串,将使用str将其转换为字符串。其他说明符将导致其他形式的转换。例如,%.3f将值的格式设置为包含3位小数的浮点数。可能遇到的另一种解决方案是所谓的模板字符串。它使用类似于UNIX shell的语法,旨在简化基本的格式设置机制。
2.字符串格式运算符——format
编写新代码时,应选择使用字符串方法format,它融合并强化了早期方法的优点。使用这种方法时,每个替换字段都用花括号括起,其中可能包含名称,还可能包含有关如何对相应的值进行转换和格式设置的信息。在最简单的情况下,替换字段没有名称或将索引用作名称。
“{}, {} and {}”.format(“first”, “second”, “third”)
‘first, second and third’
“{0}, {1} and {2}”.format(“first”, “second”, “third”)
‘first, second and third’
然而,索引无需像上面这样按顺序排列。
“{3} {0} {2} {1} {3} {0}”.format(“be”, “not”, “or”, “to”)
‘to be or not to be’
命名字段的工作原理与你预期的完全相同。
from math import pi
“{name} is approximately {value:.2f}.”.format(value=pi, name=“π”)
‘π is approximately 3.14.’
包含等号的参数称为关键字参数。在字符串格式设置中,可将关键字参数视为一种向命名替换字段提供值的方式。当然,关键字参数的排列顺序无关紧要。在这里,我还指定了格式说明符.2f,并使用冒号将其与字段名隔开。它意味着要使用包含2位小数的浮点数格式。如果没有指定.2f,结果将如下:
“{name} is approximately {value}.”.format(value=pi, name=“π”)
‘π is approximately 3.141592653589793.’
最后,在Python 3.6中,如果变量与替换字段同名,还可使用一种简写。在这种情况下,可使用f字符串——在字符串前面加上f。
from math import e
f"Euler’s constant is roughly {e}."
“Euler’s constant is roughly 2.718281828459045.”
在这里,创建最终的字符串时,将把替换字段e替换为变量e的值。这与下面这个更明确一些的表达式等价:
“Euler’s constant is roughly {e}.”.format(e=e)
“Euler’s constant is roughly 2.718281828459045.”
替换字段
替换字段由如下部分组成,其中每个部分都是可选的。
字段名:索引或标识符,指出要设置哪个值的格式并使用结果来替换该字段。除指定值外,还可指定值的特定部分,如列表的元素。
转换标志:跟在叹号后面的单个字符。当前支持的字符包括r(表示repr)、s(表示str)和a(表示ascii)。如果你指定了转换标志,将不使用对象本身的格式设置机制,而是使用指定的函数将对象转换为字符串,再做进一步的格式设置。
格式说明符:跟在冒号后面的表达式(这种表达式是使用微型格式指定语言表示的)。格式说明符让我们能够详细地指定最终的格式,包括格式类型(如字符串、浮点数或十六进制数),字段宽度和数的精度,如何显示符号和千位分隔符,以及各种对齐和填充方式。下面详细介绍其中的一些要素。
1.替换字段名
在最简单的情况下,只需向format提供要设置其格式的未命名参数,并在格式字符串中使用未命名字段。此时,将按顺序将字段和参数配对。你还可给参数指定名称,这种参数将被用于相应的替换字段中。你可混合使用这两种方法。
“{foo} {} {bar} {}”.format(1, 2, bar=4, foo=3)
‘3 1 4 2’
还可通过索引来指定要在哪个字段中使用相应的未命名参数,这样可不按顺序使用未命名参数。
“{foo} {1} {bar} {0}”.format(1, 2, bar=4, foo=3)
‘3 2 4 1’
然而,不能同时使用手工编号和自动编号,因为这样很快会变得混乱不堪。你并非只能使用提供的值本身,而是可访问其组成部分(就像在常规Python代码中一样),如下所示:
fullname = [“Alfred”, “Smoketoomuch”]
“Mr {name[1]}”.format(name=fullname)
‘Mr Smoketoomuch’
import math
tmpl = “The {mod.name} module defines the value {mod.pi} for π”
tmpl.format(mod=math)
‘The math module defines the value 3.141592653589793 for π’
如你所见,可使用索引,还可使用句点表示法来访问导入的模块中的方法、属性、变量和函数(看起来很怪异的变量__name__包含指定模块的名称)。
2.基本转换
指定要在字段中包含的值后,就可添加有关如何设置其格式的指令了。首先,可以提供一个转换标志。
print(“{pi!s} {pi!r} {pi!a}”.format(pi=“π”))
π ‘π’ ‘\u03c0’
上述三个标志(s、r和a)指定分别使用str、repr和ascii进行转换。函数str通常创建外观普通的字符串版本(这里没有对输入字符串做任何处理)。函数repr尝试创建给定值的Python表示(这里是一个字符串字面量)。函数ascii创建只包含ASCII字符的表示,类似于Python 2中的repr。你还可指定要转换的值是哪种类型,更准确地说,是要将其视为哪种类型。例如,你可能提供一个整数,但将其作为小数进行处理。为此可在格式说明(即冒号后面)使用字符f(表示定点数)。
“The number is {num}”.format(num=42)
‘The number is 42’
“The number is {num:f}”.format(num=42)
‘The number is 42.000000’
你也可以将其作为二进制数进行处理。
“The number is {num:b}”.format(num=42)
‘The number is 101010’
字符串格式设置中的类型说明符
3.宽度、精度和千位分隔符
设置浮点数(或其他更具体的小数类型)的格式时,默认在小数点后面显示6位小数,并根据需要设置字段的宽度,而不进行任何形式的填充。当然,这种默认设置可能不是你想要的,在这种情况下,可根据需要在格式说明中指定宽度和精度。宽度是使用整数指定的,如下所示:
“{num:10}”.format(num=3)
’ 3’
“{name:10}”.format(name=“Bob”)
‘Bob ’
如你所见,数和字符串的对齐方式不同。精度也是使用整数指定的,但需要在它前面加上一个表示小数点的句点。
“Pi day is {pi:.2f}”.format(pi=pi)
‘Pi day is 3.14’
这里显式地指定了类型f,因为默认的精度处理方式稍有不同。当然,可同时指定宽度和精度。
“{pi:10.2f}”.format(pi=pi)
’ 3.14’
实际上,对于其他类型也可指定精度,但是这样做的情形不太常见。
“{:.5}”.format(“Guido van Rossum”)
‘Guido’
最后,可使用逗号来指出你要添加千位分隔符。
‘One googol is {:,}’.format(10**100)
'One googol is 10,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,00
0,000,000,000,000,000,000,000,000,000,000,000,000,000,000
同时指定其他格式设置元素时,这个逗号应放在宽度和表示精度的句点之间
4.符号、对齐和用 0 填充
有很多用于设置数字格式的机制,比如便于打印整齐的表格。在大多数情况下,只需指定宽度和精度,但包含负数后,原本漂亮的输出可能不再漂亮。另外,正如你已看到的,字符串和数的默认对齐方式不同。在一栏中同时包含字符串和数时,你可能想修改默认对齐方式。在指定宽度和精度的数前面,可添加一个标志。这个标志可以是零、加号、减号或空格,其中零表示使用0来填充数字。
‘{:010.2f}’.format(pi) #第一个0是用0来填充,10是表示10格宽度,.2f表示保留小数点后面2位数
‘0000003.14’
要指定左对齐、右对齐和居中,可分别使用<、>和^。
print(‘{0:<10.2f}\n{0:^10.2f}\n{0:>10.2f}’.format(pi))
3.14 左对齐
3.14 居中
3.14 右对齐
可以使用填充字符来扩充对齐说明符,这样将使用指定的字符而不是默认的空格来填充。
“{:@^15}”.format(" WIN BIG ")
‘@@@ WIN BIG @@@’
还有更具体的说明符=,它指定将填充字符放在符号和数字之间。
print(‘{0:10.2f}\n{1:10.2f}’.format(pi, -pi))
3.14
-3.14
print(‘{0:10.2f}\n{1:=10.2f}’.format(pi, -pi))
3.14
-
3.14
如果要给正数加上符号,可使用说明符+(将其放在对齐说明符后面),而不是默认的-。如果将符号说明符指定为空格,会在正数前面加上空格而不是+。
print(‘{0:-.2}\n{1:-.2}’.format(pi, -pi)) #默认设置
3.1
-3.1
print(‘{0:+.2}\n{1:+.2}’.format(pi, -pi))
+3.1
-3.1
print(‘{0: .2}\n{1: .2}’.format(pi, -pi))
3.1
-3.1
需要介绍的最后一个要素是井号(#)选项,你可将其放在符号说明符和宽度之间(如果指定了这两种设置)。这个选项将触发另一种转换方式,转换细节随类型而异。例如,对于二进制、八进制和十六进制转换,将加上一个前缀。
“{:b}”.format(42)
‘101010’
“{:#b}”.format(42)
‘0b101010’
对于各种十进制数,它要求必须包含小数点(对于类型g,它保留小数点后面的零)。
“{:g}”.format(42)
‘42’
“{:#g}”.format(42)
‘42.0000’
问题三十:Pycharm安装matplotlib
在终端中通过pip3安装matplotlib后,发现pycharm中引入会报错,查了一下发现可以在Pycharm中安装matplotlib来解决:
1.打开Preferences,找到Project Interpreter,点“+”添加
在输入框中输入matplotlib进行搜索,然后选中要安装的包并点击下方的install package
2.此时如果发现安装特别慢,可以点“manage repositories”切换为阿里云的下载地址(我直接将默认的下载地址删除了,只留了阿里云的地址)
3.切换完之后记得刷新然后点安装,可能会报错,可以通过在右侧添加Options :–trusted-host mirrors.aliyun.com来解决问题
4.还有个方法就是将上面的repository的地址从http改为https(只是在某个包安装的时候试过可以使用)之后,就可以成功安装了!
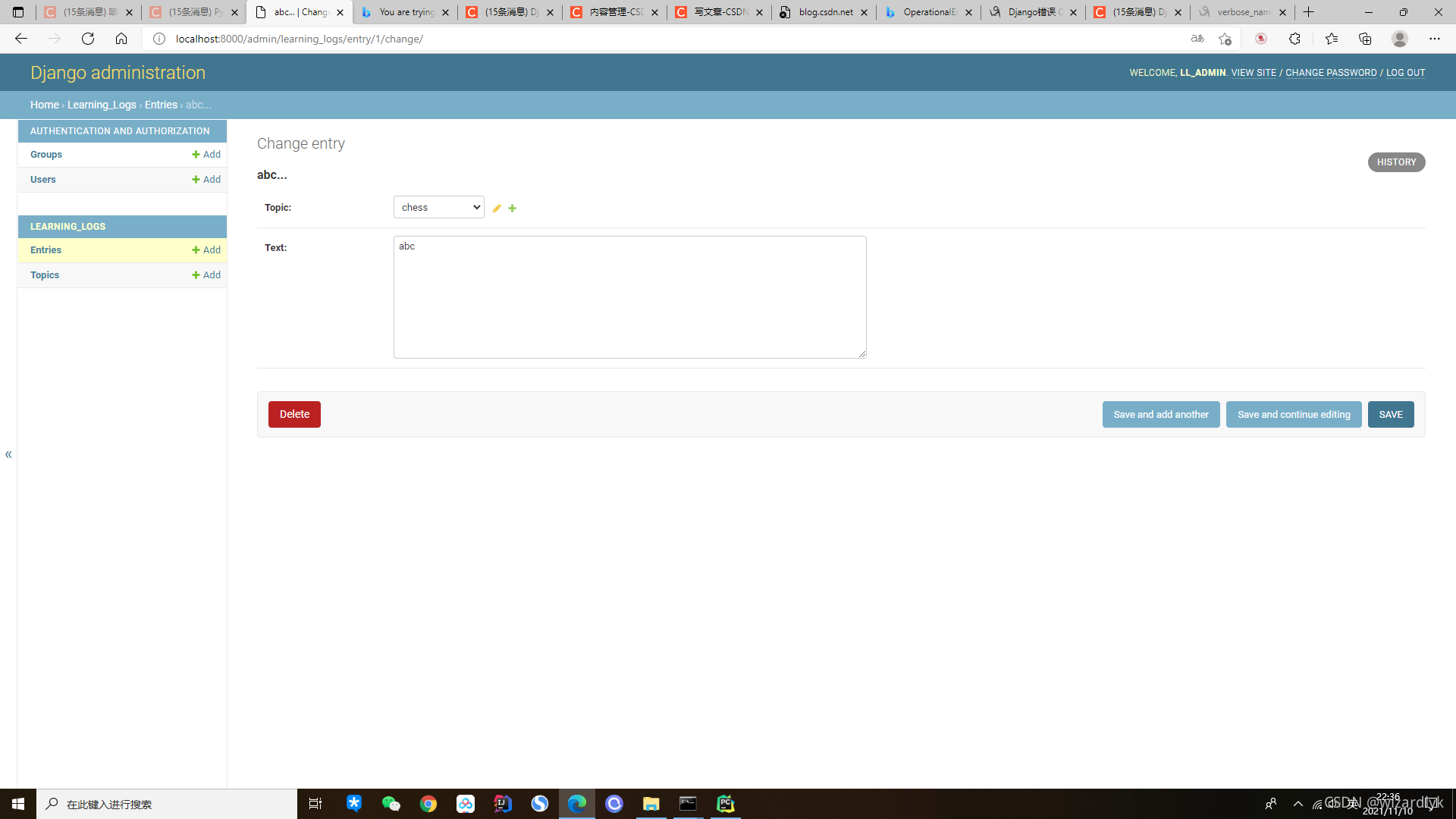
问题三十一:Django数据库操作中You are trying to add a non-nullable field ‘name’ to contact without a default错误处理
—————————————————————————————————————————————
版权声明:本文为CSDN博主「Wkyao_Check」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/check2255/article/details/70338443
—————————————————————————————————————————————
name = models.CharField(max_length=50)
执行:python manage.py makemirations出现以下错误:
You are trying to add a non-nullable field ‘name’ to contact without a default; we can’t do that (the database needs something to populate existing rows).
Please select a fix:
- Provide a one-off default now (will be set on all existing rows with a null value for this column)
- Quit, and let me add a default in models.py
Select an option:
解决方法:
先给’name’任意初始值:name = models.CharField(max_length=50, default=‘abc’)
然后执行:python manage.py makemirations
再执行:python manage.py migrate
再将default删去,即执行:name = models.CharField(max_length=50)
执行:python manage.py makemirations
再执行:python manage.py migrate
解决!
注意:在开发过程中,数据库同步误操作之后,难免会遇到后面不能同步成功的情况,解决这个问题的一个简单粗暴方法是把migrations目录下的脚本(除__init__.py之外)全部删掉,再把数据库删掉之后创建一个新的数据库,数据库同步操作再重新做一遍。
问题三十二:模板标签(tags)的介绍及如何自定义模板标签
什么是模板标签(tags)
模板标签都是放在{% %}括号里的,常见的模板标签有{% load xxxx %}, {% block xxxx %}, {% if xxx %}, {% url 'xxxx' %}。这些模板标签的本质也是函数,标签名一般即为函数名。这些标签的主要作用包括载入代码渲染模板或对传递过来的参数进行一定的逻辑判断或计算后返回。
比如下例中的url标签接收两个参数,一是命名的url, 一个是文章id,将其进行反向解析,生成一个类似blog/article/4/的链接。
<a href="{% url 'blog:article_detail' article.id %}">详情</a>
Django模板标签(tags)的分类
Django的模板标签(tag)一共分2类:
simple_tag (简单标签 : 处理数据,返回一个字符串或者给context设置或添加变量。
inclusion_tag (包含标签) : 处理数据,返回一个渲染过的模板。
熟悉Django的都知道,我们一般在视图view里设置context,然后通过它来传递数据给模板。 一个context是一系列变量和它们值的集合。通过使用simple_tag, 我们可以在视图外给context设置或添加变量。注: Django 1.9以后不再支持assignment_tag了,均使用simple_tag。
如何自定义模板标签
首先你要在你的app目录下新建一个叫templatetags的文件夹(不能取其它名字), 里面必需包含__init__.py的空文件。在该目录下你还要新建一个python文件专门存放你自定义的模板标签函数,本例中为blog_extras.py,当然你也可以取其它名字。整个目录结构如下所示:
blog/
__init__.py
models.py
templatetags/
__init__.py
blog_extras.py
views.py
在模板中使用自定义的模板标签时,需要先使用{% load blog_extras %}载入自定义的过滤器,然后通过{% tag_name %} 使用它。
自定义模板标签的3个简单例子
我们将定义3个简单模板标签,一个返回string, 一个给模板context传递变量,一个显示渲染过的模板。我们在blog_extra.py里添加下面代码。
-
#blog_extra.py
-
-
from django
import template
-
import datetime
-
from blog.models
import Article
-
-
register = template.Library()
-
-
# use simple tag to show string
-
@register.simple_tag
-
def
total_articles():
-
return Article.objects.
filter(status=
'p').count()
-
-
# use simple tag to set context variable
-
@register.simple_tag
-
def
get_first_article():
-
return Article.objects.
filter(status=
'p').order_by(
'-pub_date')[
0]
-
-
# show rendered template
-
@register.inclusion_tag('blog/latest_article_list.html')
-
def
show_latest_articles(
count=5):
-
latest_articles = Article.objects.
filter(status=
'p').order_by(
'-pub_date')[:count]
-
return {
'latest_articles': latest_articles, }
-
# latest_article_list.html
-
-
<ul>
-
{%
for article
in latest_articles %}
-
<li>{{ article.title }} </li>
-
{% endfor %}
-
</ul>
-
# index.html (使用我们自定义的模板标签)
-
-
{% extends
"blog/base.html" %}
-
{% load blog_extras %}
-
-
{% block content %}
-
-
<p>文章数: {% total_articles %}</p>
-
{% show_latest_articles %}
-
-
{% get_first_article
as first_article %}
-
<p>第一篇文章: </p>
-
<p>{{ first_article.title }}</p>
-
-
{% endblock %}
一个复杂的例子: 从模板或context接收参数后返回结果
上述3个简单例子的信息传递都是单向的,更常见的情况是标签函数接收从模板或context传递过来的参数,处理后再返回字符串或渲染过的模板。
下例中show_results标签需要接收模板传递的poll这个参数,才能返回poll结果。
{% show_results poll %}
这时我们可以这样写show_results函数。
@register.inclusion_tag('results.html')
def show_results(poll):
choices = poll.choice_set.all()
return {'choices': choices}
当然poll这个变量出现在模板中并不是必需的,很多时候一个对象或一个对象清单已经存在全局变量context里,我们可以使用takes_context=True来直接使用context里的变量。假设poll已经存在context里,我们上面代码可以改为:
@register.inclusion_tag('results.html', takes_context=True)
def show_results(context):
choices = context['poll'].choice_set.all()
return {'choices': choices}
此时模板可以简化为如下代码,不再需要poll这个参数,即可显示poll的结果。
{% show_results %}
如何处理从模板中传递过来的多个参数
{% show_results poll %}中我们自定义的标签函数只接收了从模板传递过来的一个poll参数。一个模板也可以传递多个参数,如果参数名字或数量已知,Django的tag函数是可以按位置处理传递过来的参数的。
{% my_tag "abcd" book.title warning=message profile=user.profile %}
@register.inclusion_tag('my_template.html')
def my_tag(a, b, *args, **kwargs):
warning = kwargs['warning']
profile = kwargs['profile']
...
return ...
但类似{% url "article_detail" article.id article.slug %}中的url标签显然要复杂得多。它可以接收未知数量的参数和未知名字的参数, 而且参数中有的带双引号,有的不带双引号。
对于这种情况Django的做法是先对标签所在的节点进行解析(parser), 把接收过来的字符串整体作为一个token,先对token进行split拆分,然后再分别处理。
我们现在来看看{% format_time %}这个标签是如何时间日期的格式化的。
<p>Published at at {% format_time article.pub_date "%Y-%m-%d %I:%M %p" %}.</p>
自定义的format_time标签函数完整代码如下。
from django import template
register = template.Library()
@register.tag(name="format_time")
def do_format_time(parser, token):
try:
# split_contents() knows not to split quoted strings.
tag_name, date_to_be_formatted, format_string = token.split_contents()
except ValueError:
raise template.TemplateSyntaxError(
"%r tag requires exactly two arguments" % token.contents.split()[0]
)
if not (format_string[0] == format_string[-1] and format_string[0] in ('"', "'")):
raise template.TemplateSyntaxError(
"%r tag's argument should be in quotes" % tag_name
)
return FormatTimeNode(date_to_be_formatted, format_string[1:-1])
class FormatTimeNode(template.Node):
def __init__(self, date_to_be_formatted, format_string):
self.date_to_be_formatted = template.Variable(date_to_be_formatted)
self.format_string = format_string
def render(self, context):
try:
actual_date = self.date_to_be_formatted.resolve(context)
return actual_date.strftime(self.format_string)
except template.VariableDoesNotExist:
return ''
我们现在来着重看下上面这段代码是如何工作的。
Django模板解析器扫描整个模板,碰到了format_time这个标签,把其当作一个新的节点Node,获取了format_time article.pub_date "%Y-%m-%d" 这一长串字符串作为token
get_format_time方法利用token自带的split_contents方法把上述字符串拆分成三部分: 标签名(tag_name), 需要格式化的日期(date)和指定格式(format), 并返回需要格式化的日期和格式交由FormatTimeNode处理。format_string[1:-1]的作用是去掉双引号。
FormatTimeNode这个节点类负责渲染节点,通过render方法渲染新的节点,还可以通过context给模板传递其它的变量(如下所示)。当render方法不返回一个具体的值的时候,需要返回一个空字符串。
def render(self, context):
actual_date = self.date_to_be_formatted.resolve(context)
context['formatted_time'] = actual_date.strftime(self.format_string)
return ''
问题三十三:递归(自己用笔写写就能明白)
# 用递归实现100以内的数相加
def sum_numbers(num):
if num == 1:
return 1
else:
return num + sum_numbers(num - 1)
sum_result = sum_numbers(100)
print(sum_result)
分析:100+(99+(98+(97+(96+…+(2+(1))))
问题三十四:lambda表达式:
如果一个函数有一个返回值,并且只有一句代码,这个时候可以用lambda表达式。
fn1 = lambda a, b: a * b
print(fn1(5, 9))
Console:45
问题三十五:map(),reduce(),filter()
list1 = [1, 2, 3, 4, 5, 6]
# map() --返回一个map对象
def func1(x):
return x ** 2
result = map(func1, list1)
print(result)
print(list(result))
# reduce()
import functools
def func2(a, b):
return a + b
result2 = functools.reduce(func2, list1)
print(result2)
# filter() --返回一个filter对象
def func3(x):
return x % 2 == 0
result3 = filter(func3, list1)
print(result3)
print(list(result3))
问题三十六:typing模块的作用
自python3.5开始,PEP484为python引入了类型注解(type hints)
- 类型检查,防止运行时出现参数和返回值类型、变量类型不符合。
- 作为开发文档附加说明,方便使用者调用时传入和返回参数类型。
- 该模块加入后并不会影响程序的运行,不会报正式的错误,只有提醒pycharm目前支持typing检查,参数类型错误会黄色提示
def test(a:int, b:str) -> str:
print(a, b)
return 1000
if __name__ == '__main__':
test('test', 'abc')
函数test,
a:int 指定了输入参数a为int类型,
b:str b为str类型,
-> str 返回值为srt类型。
可以看到,
在方法中,我们最终返回了一个int,此时pycharm就会有警告;
当我们在调用这个方法时,参数a我们输入的是字符串,此时也会有警告;
但非常重要的一点是,pycharm只是提出了警告,但实际上运行是不会报错,毕竟python的本质还是动态语言
问题三十七:解决pyinstaller打包生成的exe运行完直接退出的问题
- input语句
input('Press <Enter>')
在最后加上这个就好了,巧妙运用了input语句
这个写到方法里面就好了,不然程序没法执行完毕就关闭了。
猜数字小游戏:
# -*- coding: <utf8> -*-
# this is a Guess the Number game
import random
def GuessGame():
guessTaken = 1
myName = input("Hello! What's your name?")
number = random.randint(1, 100)
print(f"Well,{myName},I am thinking of a number between 1 and 20.")
for i in range(6):
guess = int(input('Take a guess.'))
if guess < number:
print('Your guess is too low.')
guessTaken += 1
elif guess > number:
print("Your guess is too high.")
guessTaken += 1
elif guess == number:
break
if guess == number:
print(f'Good job, {myName}! You guessed my number in {str(guessTaken)} guess!')
if guess != number:
print(f"Nope. The number I was thinking of was {str(number)}.")
input('Press <Enter> to EXIT')
GuessGame()
- 安装pyinstaller
pip install pyinstaller
1.打开cmd进入到需要打包的文件夹下
2.D:\python_project\python_game_practice\Guess>pyinstaller -i KG.ico -F guess.py
| -h,--help | 查看该模块的帮助信息 |
|---|---|
| -F,-onefile | 产生单个的可执行文件 |
| -D,--onedir | 产生一个目录(包含多个文件)作为可执行程序 |
| -a,--ascii | 不包含 Unicode 字符集支持 |
| -d,--debug | 产生 debug 版本的可执行文件 |
| -w,--windowed,--noconsolc | 指定程序运行时不显示命令行窗口(仅对 Windows 有效) |
| -c,--nowindowed,--console | 指定使用命令行窗口运行程序(仅对 Windows 有效) |
| -o DIR,--out=DIR | 指定 spec 文件的生成目录。如果没有指定,则默认使用当前目录来生成 spec 文件 |
| -p DIR,--path=DIR | 设置 Python 导入模块的路径(和设置 PYTHONPATH 环境变量的作用相似)。也可使用路径分隔符(Windows 使用分号,Linux 使用冒号)来分隔多个路径 |
| -n NAME,--name=NAME | 指定项目(产生的 spec)名字。如果省略该选项,那么第一个脚本的主文件名将作为 spec 的名字 |
import os
#......
os.system('pause')
- 三、运用time库(不推荐)
import time #...... time.sleep(number)#number为停顿时间,自己随便填一个,这样运行完代码以后会停顿number秒后再退出
问题三十七:class, class()和class(object)的区别
1 为什么要继承 object 类
-
Python2中, 遇到 class A 和 class A(object) 是有概念上和功能上的区别的,分别称为经典类(旧式类,old-style)与新式类(new-style)的区别。python2中为什么在进行类定义时最好要加object,加 & 不加如下实例。
-
历史进程:2.2以前的时候type和object还不统一. 在2.2统一到3之间, 要用class
Foo(object)来申明新式类, 因为它的type是 < type ‘type’ > 。
不然的话, 生成的类的type就是 <type ‘classobj’ >。 -
继承object类的原因:主要目的是便于统一操作。
在python 3.X中已经默认继承object类。
# -.- coding:utf-8 -.-
# __author__ = 'zhengtong'
class Person:
“”"
不带object
“”"
name = “zhengtong”
class Animal(object):
“”"
带有object
“”"
name = “chonghong”
if name == “main”:
x = Person()
print “Person”, dir(x)
y <span class="token operator">=</span> Animal<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">print</span> <span class="token string">"Animal"</span><span class="token punctuation">,</span> <span class="token builtin">dir</span><span class="token punctuation">(</span>y<span class="token punctuation">)</span>
Person ['__doc__', '__module__', 'name'] Animal ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name']Person类很明显能够看出区别,不继承object对象,只拥有了doc , module 和 自己定义的name变量, 也就是说这个类的命名空间只有三个对象可以操作。
Animal类继承了object对象,拥有了好多可操作对象,这些都是类中的高级特性。
2 class, class()和class(object)的区别
python2中写为如下两种形式都是不能继承object类的,也就是说是等价的。
def class: def class():继承object类是为了让自己定义的类拥有更多的属性,以便使用。当然如果用不到,不继承object类也可以。
python2中继承object类是为了和python3保持一致,python3中自动继承了object类。
python2中需要写为如下形式才可以继承object类。
def class(object):Reference:https://blog.csdn.net/yinboxu/article/details/79852772?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









