







逻辑回归,是名为“回归”的线性分类器 ,本质是由线性回归变化而来,一种广泛用于分类问题的广义回归算法。

通过函数z,线性回归使用输入的特征矩阵X输出一组连续型的标签枝y_pred,完成预测连续型变量的任务。若是离散型变量,则引入联系函数,让值无限接近0或1,二分类任务,逻辑回归的联系函数为Sigmoid函数
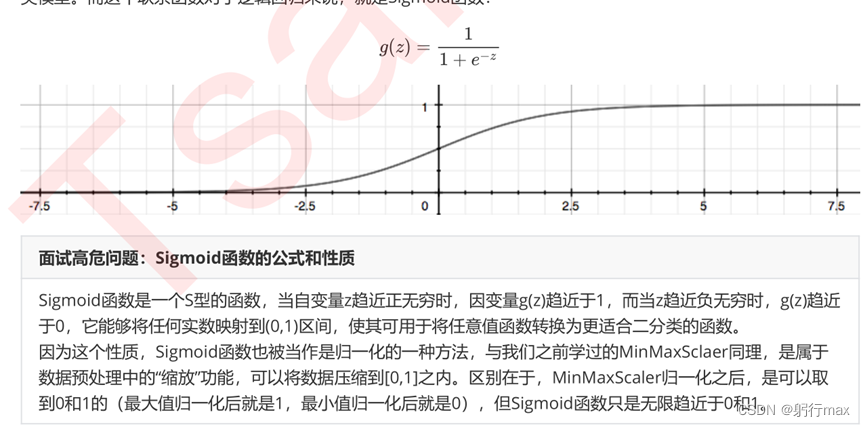

为什么选择逻辑回归:
逻辑回归对线性关系的拟合效果好到丧心病狂;逻辑回归计算快;逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字。并不是真正的概率,只是最大似然估计。
逻辑回归的本质:返回对数几率,在线性数据表现优异的分类器。数学目的是求解能够让模型对数据拟合程度最高的参数值,以此构建预测函数,然后将特征矩阵输入预测函数计算逻辑回归的结果y,可以作多分类。
逻辑回归的评估指标
1.损失函数:决策树和随机森林有两种模型表现:训练集的表现和测试集的表现,建模是追求在测试集表现最优,因此评估指标是衡量模型在测试集的表现的:交叉熵损失和MSE。但逻辑回归需要基于训练参数求解参数,故引入损失函数的评估指标,衡量选定参数的模型拟合训练集产生的信息损失的大小,以此衡量参数的优劣。
需要注意:没有求解参数需求的模型没有损失函数,比如KNN,决策树,因为特征固定,参数手动选择,评估在测试集的表现,不用基于训练集更新参数。

基于逻辑回归的返回值 的概率性质得出的损失函数。在这个函数上,我们只要追求最小值,就
能让模型在训练数据上的拟合效果最好,损失最低。这个推导过程,其实就是“极大似然法”的推导过程。
2.正则化:正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量 的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为"惩罚项"。

L1正则化会将参数压缩为0,某些特征在公式就为0了,本质是一个特征选择的过程,掌管了参数的“稀疏性”;L2正则化会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0.
2.逻辑回归的特征工程
我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关,因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
逻辑回归对数据的要求低于线性回归,由于我们不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。
可以用L1或L2正则化与高效的嵌入法embedded和简单快速的包装法结合,结合参数选择特征,减少输入。
3.梯度下降求逻辑回归
所以梯度下降,其实就是在众多 可能的值中遍历,一次次求解坐标点的梯度向量,不断让损失函数的取值逐渐逼近最小值,再返回这个最小值对应的参数取值 的过程。


上图是重点,注意理解,不要混淆。

3.1步长不说任何物理距离,甚至不是梯度下降过程中任何距离的直接变化,是梯度向量的大小的一个比例,影响着参数向量每次迭代后改变的部分。
4.样本不平衡与参数class_weight
逻辑回归中用的最多是上采样方法平衡样本(增加少数类的样本)
5.涉及到案例代码部分,有空再更。















 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









