







文章链接:https://arxiv.org/abs/1907.10371
code:https://github.com/Walleclipse/AGPC
本文作者提出一种基于用户个性化信息来生成评论的方法;个性化信息如下:

方法如模型结构图:

- 首先是基于seq2seq模型+attention机制,encoder和decoder都采用lstm;
- 应用了一种基于门记忆的特征embedding; 将用户的个性化特征属性F={f1,…,fk}、经过一个全连接层,得到向量表示u。u可以看作是user feature embedding,表明用户的个人特征。如果user feature embedding是静态的,在decode过程中会影响生成回复的语法性。为了解决这个问题,设计了一个gated memory来动态地表达用户的个人特征。这个embedding随着decoder进行不断衰减;
- 基于博客和用户个人描述的联合attention;
- 通过将第3点的信息和第2点的用户个性化信息一起作为decoder隐藏状态更新的输入,来结合persona信息,进而影响decode过程。这种影响是隐性的,为了更明确地利用用户信息来指导word的生成,将用户信息直接作为输出层的输入;
User Feature Embedding with Gated Memory:
将用户的数值化特征属性F={f1,…,fk}F={f1,…,fk}经过一个全连接层,得到向量表示v。v可以看作是user feature embedding,表明用户的个人特征。如果user feature embedding是静态的,在decode过程中会影响生成回复的语法性。为了解决这个问题,设计了一个gated memory来动态地表达用户的个人特征。
在decode过程中,保持一个Internal personal stateMt,在decode过程中Mt逐渐衰减,decode结束,Mt衰减为0,表示用户的个人特征完全表达了。M0的初始值设为v。(Mt理解成t时刻包含的多少用户信息,是由gt擦去Mt-1时刻的内容后得到的,gt是由t时刻decoder hidden st决定;总的来说由st决定,t时刻输出多少个性化信息)
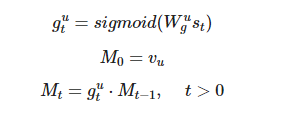
引入输出门机制g’o,表示对 t 时候个性化信息Mt,model需要花多少注意力在上面(用多大概率数进行学习),这个是由 t-1 时刻的decoder hidden :S(t-1), 前一个target word :e(yt-1), 当前语境向量:ct 共同决定的;
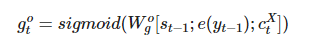
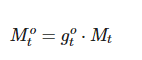
1. 门机制的加入,动态的输入给decoder;值得学习;
2. 需要把用户各种个性化信息,属性知识进行不同的编码处理,并用co-attention联合在一起的处理值得学习借鉴;















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









