










Problem

Hint
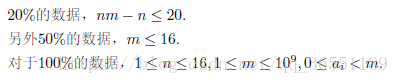
Solution
看到这道题时我也想了一会容斥,只不过当时比较傻逼,想到的是
2n
2
n
暴枚一个S,再
2n
2
n
暴枚一个S1⊆S,然后就误以为会gg。。。竟然没有想到直接
O(3n)
O
(
3
n
)
枚举。。。
下面是TJ:

这个容斥应该很好理解。当S1为空集时,S-S1=S,则S中所有点都可以任意匹配;这样可能会使某个点x与跟自己不连边的点匹配,于是又要减去;然而,若有两点x、y,一次x在S1、y在S-S1中,一次y在S1、x在S-S1中,它们都与跟自己不连边的点匹配的情况会被减两次,于是又要加回来……
然而,这题最猥琐的是防止它重复匹配。你可以dfs出一个S、S1以后,
O(n)
O
(
n
)
扫一遍S1里面的东西,看看它们有木有重复匹配。
然后,你或许还会这样打来统计F(S):
int h=(l1&1?M-1:1),res=m-l1; // l1表示|S1|,res表示右边剩下多少个点
fo(i,1,l2) h=1ll*h*res--%M;// l2表示|S-S1|,h表示H(S,S1);该条语句计算S-S1中的点任意匹配的方案数
F[S]+=(ll)h; 这样你就会得到一个这个东西:

计算器算一下,
316=43046721≈4∗107≈0.4sec
3
16
=
43046721
≈
4
∗
10
7
≈
0.4
s
e
c
,如果在乘个16,显然吃不消。
于是,必须要优化这两个操作:1)防止重复匹配;2)统计F(S)。
对于1),有两种方法:a)预先dfs出合法的S1的集合;b)我的方法,将a数组(记录左边每个点不与右边哪个点相连)离散化,dfsS和S1时统计一下出现的ai的状态,不使某个ai重复出现即可。
对于2),我们研究一下上面的代码,发现它仅与l1、l2有关。于是预处理出一个数组s[i][j],表示当l1=i、l2=j时,H(S,S1)的值。这样便可以
O(1)
O
(
1
)
搞出。
时间复杂度:
O(n2(预处理)+3n(计算F(S))+2n(统计答案))
O
(
n
2
(
预
处
理
)
+
3
n
(
计
算
F
(
S
)
)
+
2
n
(
统
计
答
案
)
)
。
Code
#include <cstdio>
#include <algorithm>
#define fo(i,a,b) for(i=a;i<=b;i++)
using namespace std;
typedef long long ll;
const int N=17,M=1e9+7;
int i,j,n,m,a[N],l1,s1[N],l2,b[N],nb,a1[N],s[N][N],res,ans;
ll F[1<<16];
void dfs(int x,int S,int S1)
{
if(x==n)
{
int h=(l1&1?M-1:1);
F[S]=(F[S]+1ll*h*s[l1][l2])%M;
return;
}
dfs(x+1,S,S1);
int ax=1<<a1[x];
if(!(S1&ax))
{
s1[++l1]=x;
dfs(x+1,S+(1<<x),S1+ax);
l1--;
}
l2++;
dfs(x+1,S+(1<<x),S1);
l2--;
}
int main()
{
freopen("bipartite.in","r",stdin);
freopen("bipartite.out","w",stdout);
scanf("%d%d",&n,&m);
fo(i,0,n-1) scanf("%d",&a[i]), b[i]=a[i];
sort(b,b+n); nb=unique(b,b+n)-b-1;
fo(i,0,n-1)
fo(j,0,nb)
if(a[i]==b[j]){a1[i]=j; break;}
fo(i,0,n)
{
s[i][0]=1; res=m-i;
fo(j,1,n) s[i][j]=1ll*s[i][j-1]*res--%M;
}
dfs(0,0,0);
fo(i,1,(1<<n)-1) ans=(ll)(ans+1ll*i*F[i])%M;
printf("%d",ans);
}














 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









