







文章目录
有什么用?
批归一化(Batch Normalization,BatchNorm)是由Ioffe和Szegedy于2015年提出的,目前已被广泛应用在深度学习中,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定。
-
什么意思呢?
就是这些专家认为啊,模型的收敛需要稳定的数据分布。 -
什么叫稳定的数据分布呢?
以图像处理为例,我们一般会对图像进行预处理,做归一化操作,把[0, 255]之间的数值限制在[-1, 1]之间(均值为0,方差为1),这样数据分布波动就不算大。不然你时而输入为[0.1]时而输入为[255.]对算法来说很难去适应这种数据分布,也就很难收敛。 -
那再输入模型之前做一遍归一化就行了,为什么还要在神经网络中间层的数据进行归一化处理呢?
其实对于浅层网络对输入数据做一遍归一化处理确实就可以了,模型的效果不错。但是对于深层网络,即使你的输入数据已经做过标准化的处理,但是对于那些比较靠后的层,随着参数的不断更新,其接受到的输入仍然是剧烈变化的,导致数值不稳定,难以收敛
所以,Batch Normalization 就是为提升深层网络中的数值稳定性所提出来的方法,能够使神经网络中间层的输出变得更加稳定,有以下三个优点:
- 使学习快速进行(能够使用较大的学习率)
- 降低模型对初始值的敏感性
- 从一定程度上抑制过拟合
原理是什么,怎么计算?
BatchNorm主要思路是在训练时按mini-batch为单位,对神经元的数值进行归一化,使数据的分布满足均值为0,方差为1。分为以下四步:
Step 1: 计算mini-batch内样本均值:
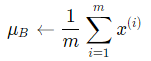
Step 2: 计算mini-batch内样本方差:
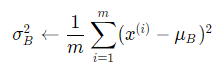
Step 3: 计算标准化输出:
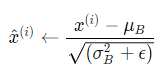
其中分母还要加一个‘ε’,它是一个很小的值,比如1e-7,主要是为了避免分母为0的情况。
Step 4: 平移和缩放:
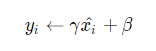
因为,研究者认为如果强行地限制每一层的输出都是标准化的,可能会导致某些特征模式的丢失。所以,在标准化之后,BatchNorm就还会做一个缩放和平移。
其中γ和β这两个参数都是可学习的,可以赋初值,一般是(γ=1,β=0)
怎么用?
上面的参数更新都是只在训练过程中才会用到,在预测时,我们不会再计算输入样本的均值和方差,以及更新γ,β两个参数。
其实要这么做的原因很简单,比如现在有两个Batch数据传入到模型中,batch_size=4:
- 其中Batch1=[A, B, C, D],经过BatchNorm得到[a1, b, c, d];
- Batch2=[A, X, Y, Z],经过BatchNorm得到[a2, x, y, z];
- 这样算出来,a1 ≠ a2。
而我们需要的效果是,同样的数据在预测时,它每一次传入模型,所得到的数据分布都应该是一样的。不然样本的预测结果就会变得不确定,这对预测过程来说是不合理的的,所以我们需要在训练过程中将大量样本的均值和方差存储下来,预测时不计算样本内的均值和方差,而是使用训练时保存值。
训练:滚动平均的方式,计算整个数据集上的均值和方差,并保存
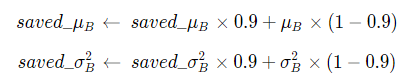
测试:直接加载训练时保存的均值和方差

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









