







 本文详细介绍了一个猫狗分类的深度学习项目,使用VGG19网络并结合预训练模型,在猫狗数据集上进行训练和测试,实现了高精度的分类效果。
本文详细介绍了一个猫狗分类的深度学习项目,使用VGG19网络并结合预训练模型,在猫狗数据集上进行训练和测试,实现了高精度的分类效果。
准备数据集
我是用的torchvision.datasets.ImageFolder加载的数据,就把数据集分成如下形式:
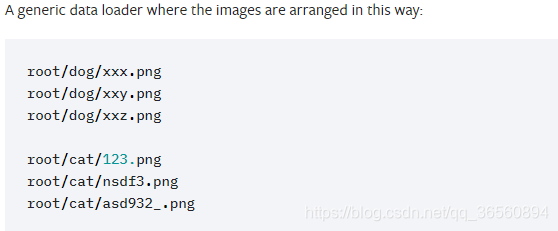
猫狗数据集里有25000张train数据,12500张test数据;我从train数据中随机抽取4000张图像作为val数据集。

import torchvision
import torch
import numpy as np
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
trainset = torchvision.datasets.ImageFolder('../data/val/', transform=transform)
trainloader = torch.utils.data.DataLoader(dataset=trainset, batch_size=4, shuffle=True)
import matplotlib.pyplot as plt
%matplotlib inline
def imshow(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(labels)

模型文件 VGG_hc.py
VGG网络可以看我另一篇博文:VGG论文分析
这里也可以更换为ResNet,为了结构不混乱就不加了,ResNet贴在最后的github链接上,这里也贴上ResNet的论文分析:ResNet论文分析
import torch
import torch.nn as nn
class VGG19(nn.Module):
def __init__(self, num_classes, init_weights=True):
super().__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2),
# Block 2
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2),
# Block 3
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2),
# Block 4
nn.Conv2d(256, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2),
# Block 5
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
)
# 因为前面可以用预训练模型参数,所以单独把最后一层提取出来
self.classifier2 = nn.Linear(4096, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
# torch.flatten 推平操作
x = torch.flatten(x, 1)
x = self.classifier(x)
x = self.classifier2(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 查看模型结构
# model = VGG19(num_classes=2, init_weights=True)
# print(model)
训练 train.ipynb
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from VGG_hc import VGG19
import time
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
%matplotlib inline
# 利用torchvision对图像数据预处理
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomAffine(degrees=15,scale=(0.8,1.5)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
trainset = torchvision.datasets.ImageFolder(root='../data/train/', transform=train_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=4)
valset = torchvision.datasets.ImageFolder(root='../data/val/', transform=val_transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=128, shuffle=False, num_workers=4)
用了在ImgNet上的VGG19预训练模型
在我另一篇博文说了如何下载:Pytorch使用部分预训练模型
# 展示训练样本和测试样本数
print(len(trainloader))
print(len(valloader))
# CPU 或者 GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 初始化网络,加载预训练模型
model = VGG19(num_classes=2, init_weights=False)
model_dict = model.state_dict()
state_dict = torch.load('pretrained/vgg19-dcbb9e9d.pth')
new_state_dict = {k: v for k, v in state_dict.items() if k in model_dict}
model_dict.update(new_state_dict)
model.load_state_dict(model_dict)

# 查看GPU可用情况
if torch.cuda.device_count()>1:
print('We are using',torch.cuda.device_count(),'GPUs!')
model = nn.DataParallel(model)
model.to(device)
# 定义loss function和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
# 保存每个epoch后的Accuracy Loss Val_Accuracy
Accuracy = []
Loss = []
Val_Accuracy = []
BEST_VAL_ACC = 0.
# 训练
since = time.time()
for epoch in range(10):
train_loss = 0.
train_accuracy = 0.
run_accuracy = 0.
run_loss =0.
total = 0.
model.train()
for i,data in enumerate(trainloader,0):
images, labels = data
images = images.to(device)
labels = labels.to(device)
# 经典四步
optimizer.zero_grad()
outs = model(images)
loss = criterion(outs, labels)
loss.backward()
optimizer.step()
# 输出状态
total += labels.size(0)
run_loss += loss.item()
_,prediction = torch.max(outs,1)
run_accuracy += (prediction == labels).sum().item()
if i % 20 == 19:
print('epoch {},iter {},train accuracy: {:.4f}% loss: {:.4f}'.format(epoch, i+1, 100*run_accuracy/(labels.size(0)*20), run_loss/20))
train_accuracy += run_accuracy
train_loss += run_loss
run_accuracy, run_loss = 0., 0.
Loss.append(train_loss/total)
Accuracy.append(100*train_accuracy/total)
# 可视化训练过程
fig1, ax1 = plt.subplots(figsize=(11, 8))
ax1.plot(range(0, epoch+1, 1), Accuracy)
ax1.set_title("Average trainset accuracy vs epochs")
ax1.set_xlabel("Epoch")
ax1.set_ylabel("Avg. train. accuracy")
plt.savefig('Train_accuracy_vs_epochs.png')
plt.clf()
plt.close()
fig2, ax2 = plt.subplots(figsize=(11, 8))
ax2.plot(range(epoch+1), Loss)
ax2.set_title("Average trainset loss vs epochs")
ax2.set_xlabel("Epoch")
ax2.set_ylabel("Current loss")
plt.savefig('loss_vs_epochs.png')
plt.clf()
plt.close()
# 验证
acc = 0.
model.eval()
print('waitting for Val...')
with torch.no_grad():
accuracy = 0.
total =0
for data in valloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
out = model(images)
_, prediction = torch.max(out, 1)
total += labels.size(0)
accuracy += (prediction == labels).sum().item()
acc = 100.*accuracy/total
print('epoch {} The ValSet accuracy is {:.4f}% \n'.format(epoch, acc))
Val_Accuracy.append(acc)
if acc > BEST_VAL_ACC:
print('Find Better Model and Saving it...')
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(model.state_dict(), './checkpoint/VGG19_Cats_Dogs_hc.pth')
BEST_VAL_ACC = acc
print('Saved!')
fig3, ax3 = plt.subplots(figsize=(11, 8))
ax3.plot(range(epoch+1),Val_Accuracy )
ax3.set_title("Average Val accuracy vs epochs")
ax3.set_xlabel("Epoch")
ax3.set_ylabel("Current Val accuracy")
plt.savefig('val_accuracy_vs_epoch.png')
plt.close()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed%60))
print('Now the best val Acc is {:.4f}%'.format(BEST_VAL_ACC))
训练结果:
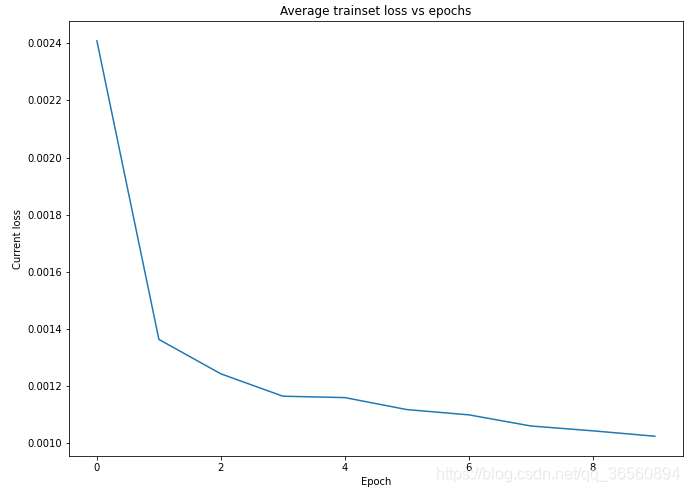
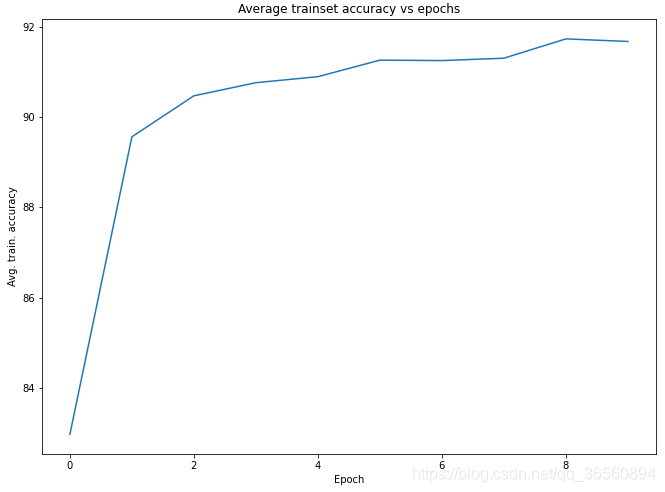
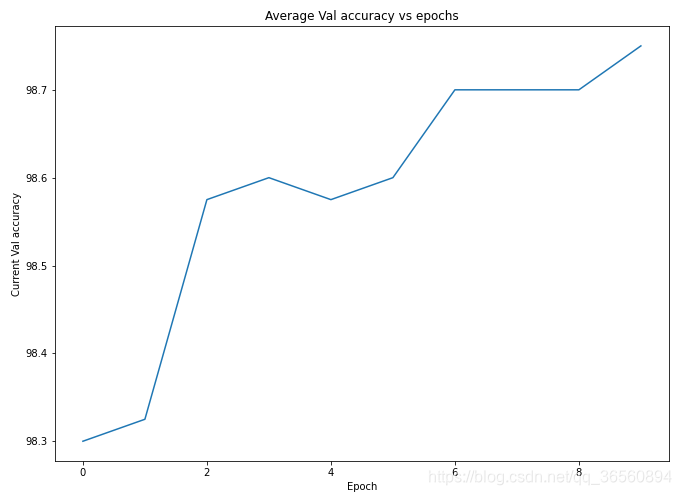
我只训练了十个epoch,准确率就已经达到98.7%以上了,预训练真的很顶!
测试文件 Test.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from VGG_hc import VGG19
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm_notebook as tqdm
from PIL import Image
import os
import pandas as pd
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载模型
model = VGG19(num_classes=2, init_weights=False)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model.to(device)
model.load_state_dict(torch.load('./checkpoint/VGG19_Cats_Dogs_hc.pth'))
# 测试
id_list = []
pred_list = []
test_path = '../data/test/'
test_files = os.listdir(test_path)
model.eval()
with torch.no_grad():
for file in tqdm(test_files):
img = Image.open(test_path+file)
_id = int(file.split('.')[0])
img = transform(img)
img = img.unsqueeze(0)
img = img.to(device)
out = model(img)
# print(out)
prediction = F.softmax(out, dim=1)[:,1].tolist()
_predict = np.array(prediction)
_predict = np.where(_predict>0.5, 1, 0)
print(_id, _predict[0])
id_list.append(_id)
pred_list.append(_predict)
res = pd.DataFrame({
'id':id_list,
'label':pred_list
})
res.sort_values(by='id', inplace=True)
res.reset_index(drop=True, inplace=True)
res.to_csv('submission.csv', index=False)
res.head(10)

import random
class_dict = {0:'cat', 1:'dog'}
fig, axes = plt.subplots(2, 5, figsize=(20,12), facecolor='w')
for ax in axes.ravel():
i = random.choice(res['id'].values)
label = res.loc[res['id']==i, 'label'].values[0]
img = Image.open('../data/test/'+str(i)+'.jpg')
ax.set_title(class_dict[label[0]])
ax.imshow(img)

GitHub
VGG:
https://github.com/Classmate-Huang/CV_ImageClassification/tree/master/VGG
ResNet:
https://github.com/Classmate-Huang/CV_ImageClassification/tree/master/ResNet

















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









