






 该博客通过决策树C4.5算法分析交通拥堵的原因,利用数据集中的路段特征如车流量、天气、时间等因素,计算特征贡献度,识别出影响交通的主要因素,并将结果保存到MySQL数据库以供展示。
该博客通过决策树C4.5算法分析交通拥堵的原因,利用数据集中的路段特征如车流量、天气、时间等因素,计算特征贡献度,识别出影响交通的主要因素,并将结果保存到MySQL数据库以供展示。
基于大量的不同环境因素下所对应的交通拥堵状态数据,运用决策树C4.5 算法归纳总结交通拥挤原因并排序。


一、数据获取:
1,分别获取拥堵数据集A和畅通数据。
2,从B中根据路段筛选出与A数量相等的畅通数据与A合并作为训练数据集C。3,对C中每条数据计算出30分钟内路段有无拥堵,30分钟内上一路段有无拥堵,30分钟内下一路段有无拥堵,30天内拥堵次数是否超过7次(常拥堵)。
具体特征如下:
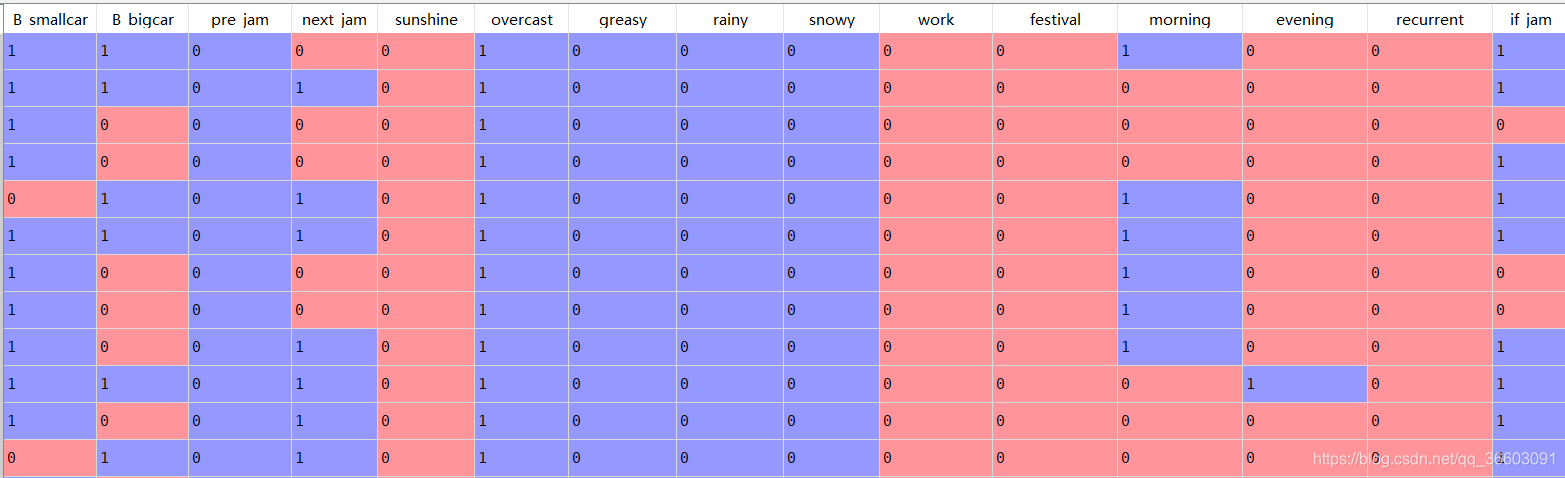
{
'B_smallcar':'小车流量大余40','B_bigcar':'大车流量大于30',
'pre_jam':'后方流量挤压', 'next_jam':'前方路段堵',
'sunshine':'晴天', 'overcast':'阴天',
'greasy':'雾天', 'rainy':'雨天', 'snowy':'雪天',
'work':'工作日','festival':'节假日',
'morning':'早高峰','evening':'晚高峰', #'Hiramine':'平峰',
'recurrent':'30d内常堵',
'if_jam':'本路段流量挤压'
}数据格式为:
二、决策树模型构建
根据link_code分别构建决策树C4.5算法模型,并输出特征贡献度:
假设父节点有样本量N0,criterion为C0;
子节点1有样本量N1,criterion为C1;
子节点2有样本量N2,criterion为C2;
总样本个数为T。
特征贡献度:
gain=(N0∗C0−N1∗C1−N2∗C2)/T
三、输出拥堵因素
1,依照模型各特征贡献度获取每日每条拥堵信息实际特征(特征值为1的)的权重;
2,实际权重值标准化(特征权重和等于1);
3,周期汇总:
根据周期汇总各路段拥堵特征和权重,计算各特征均值作为该周期被本路段拥堵特征贡献度排名,根据特征贡献度排名,选择排名top特征,输出并保存到mysql表
后续可根据需要进行前端展示


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











