







CD是Hinton为了训练他的Product of Expert模型提出的,后来用于训练RBM。
CD是最大似然法的近似算法,Contrastive Divergence (CD) is an approximate Maximum-Likelihood.
(ML) learning algorithm proposed by Geoffrey Hinton
最大似然法是训练权重的最理想的方法。CD provides an approximation to the maximum likelihood method that would ideally be applied for learning the weights
本文参考了这篇笔记
为什么需要CD
训练单个RBM时,权重的更新用梯度下降:
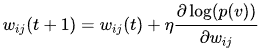
其中p(v)是显层向量的联合概率,由这个向量的的能量决定:分子表示各种可能的隐层向量h下v的能量总和,分母是配分函数,是所有可能的v,h搭配情况的能量总和,是为了归一化used for normalizing。
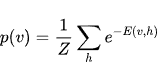
E(v,h)是整个RBM网络的能量。由显层隐层单元具体取值确定。能量越低的(v,h)/网络越是我们想要的。A lower energy indicates the network is in a more “desirable” configuration.
∂ l o g ( P ( v ) ) ∂ w i j = < v i h j > d a t a − < v i h j > m o d e l \frac{\partial log(P(v))}{\partial w_{ij}}=<v_ih_j>_{data}-<v_ih_j>_{model} ∂wij∂log(P(v))=<vihj>data−<vihj>model
其中 < > p <>_p <>p表示分布p的平均。 represent averages with respect to distribution p。 如:
< ∂ l o g f ( x k ; Θ ) ∂ Θ > X = 1 K ∑ k = 1 K ∂ l o g f ( x k ; Θ ) ∂ Θ <\frac{\partial logf(x_k;\Theta)}{\partial \Theta}>_{\boldsymbol X}=\frac1K\sum_{k=1}^K\frac{\partial logf(x_k;\Theta)}{\partial \Theta} <∂Θ∂logf(xk;Θ)>X=K1k=1∑K∂Θ∂logf(xk;Θ)
< ∂ l o g f ( x ; Θ ) ∂ Θ > p ( x ; Θ ) = ∫ p ( x ; Θ ) ∂ l o g f ( x ; Θ ) ∂ Θ d x <\frac{\partial log f(x;\Theta)}{\partial \Theta}>_{p(x;\Theta)}=\int p(x;\Theta)\frac{\partial log f(x;\Theta)}{\partial \Theta}dx <∂Θ∂logf(x;Θ)>p(x;Θ)=∫p(x;Θ)∂Θ∂logf(x;Θ)dx
这个运算很难算,computationally intractable, 所以我们换个办法——数值近似:通过CD算法经过n次(n常常取1可以取得好的效果)采样得到 < > p <>_p <>p。
The issue arises in sampling < v i h j > m o d e l <v_ih_j>_{model} <vihj>mod
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









