







本文的主要作者来自腾讯与北大。
本文主要是通过提出一种新的递归图形神经网络模型(ReGNN)模型解决GCN随着深度而面临的过平滑的问题。过平滑over-smoothing主要是指在进行多个图卷积之后,同一个连通分量内部的结点会收敛到相同的值。本文使用LSTM动态地决定将聚合的邻居信息的哪一部分传输到上层,从而缓解了过度平滑的问题。此外,为了促进局部和全局信息的交换,设计了全局图级节点。我们分别对单标签和多标签文本分类任务进行了实验。实验结果表明,我们的正则神经网络模型在绝大多数数据集上都显著地超越了强基线,大大缓解了过度平滑问题。
Model

论文里给出的模型图还是挺糙的。反正按照图的结构,ReGCN主要分为Aggregation和Update两部分。
聚合部分决定如何聚合来自节点邻居的信息,本文中主要采用了门控图神经网络的思想。更新部分根据新聚合的邻近信息决定如何更新l-th层的隐藏状态。整个算法的流程也简单明了:

Text Graph Construction
主要使用PMI(逐点互信息)构建文档图,这个公式已经很多次见了。

保留PMI为正的前n-2个结点作为邻居,同时,在一句话中,单词i的前一个单词i-1与后一个单词i+1也被包含进来,所以最终一个结点n个邻居。
Recursive Graphical Neural Networks
Update
更新的时候使用了LSTM,并且为了捕获全局的信息对整个graph进行分类,全局节点g也需要考虑。在第l层,文本图的hidden表示为如下:
对于最开始的第0层,直接用单词的特征向量表示: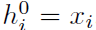 。
。
然后,从l-1层到l层的更新操作可以用如下的形式化公式描述:

其中,Ni表示结点i的邻居结点,[ ; ; ]表示向量的拼接操作。每一层都有一个xi表示单词本身的含义,这个类似于残差网络的操作在一定程度上防止过平滑。i,f,o分别表示输入门、遗忘门和输出门。
Aggregation
聚合的时候采用了注意力的方式,假设单词结点wi有Ci个邻居,wi的隐藏层表示Ni如下:

hi是上一步Update操作之后的输出,首先把wi的position embedding pi加到hi上(8)。位置嵌入是可选的,如果图不是按照文本序列构造的,就不需要位置嵌入。(9,10,11)对应着Attention的常规操作,在(9)中同样包含了原始特征xi,以及全局结点g。
Graph-level Node
接下来介绍全局节点,全局节点的介入使得没有短距离关系的结点之间也能够交换信息。当前层l的全局节点的信息基于l-1层的所有H来计算,也是一个attention操作:

然后又是一个LSTM的计算,决定在l层的全局节点的特征:

Text Classifier
分类任务分为单标签和多标签分类两种。
对于单标签分类,直接使用图级别结点g预测最终的结果:

对于多标签任务,采用具有注意机制的递归神经网络(RNN)解码器,可以生成不同长度的标签。与两个特殊标识被添加到结点序列中,遇到END标记就表示解码任务结束。具体公式为:

其中,在每个decode步,上下文向量ci通过注意力机制被计算,最终生成的标签是yi。
Experiment
在单标签与多标签任务上分别测试了模型。Table1和Table2分别描述了所使用的数据集的各种统计量。


Table3和Table4对应了基线算法的准确率:

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











