







 本文综述了基于图神经网络的文本分类技术,提出了一种新的图池化方法和混合卷积层,以解决现有方法在图数据上的池化问题和未能充分考虑节点顺序信息的局限。实验表明,该方法在多个数据集上取得了优异效果。
本文综述了基于图神经网络的文本分类技术,提出了一种新的图池化方法和混合卷积层,以解决现有方法在图数据上的池化问题和未能充分考虑节点顺序信息的局限。实验表明,该方法在多个数据集上取得了优异效果。
文本分类简单综述
文本分类是NLP里面最基本的任务,LSTM或者CNN的使用是基操。我也曾用过改进的textCNN进行文本分类,确实取得了不错的效果。随着技术的继续发展,Char-level CNN在文本分类上一度取得了state of the art的效果。但是知识库的引入又让文本分类继续得到了提升。
基于知识库的文本分类针对短文本中包含特征较少的缺陷,通过引入本文在外部知识库中对应的概念以及上下位词等扩充其特征。但是经过个人在实际任务(不是开放数据集)中的尝试,发现通过外部知识库扩充知识的过程,也是一个引入噪声的过程(我用的是cn-DBpedia)。因为领域文本的特殊性,其包含的文本词汇在外部知识库中往往找不到对应的实体,虽然在实际应用的过程中,文本分类的准确率确实有少量的提升。
近年来,随着GCN的发展,机智的研究者们将GCN引入到了文本分类的任务中。通过将文本建模成graph,在其上应用GCN,捕获到了传统CNN无法捕捉的长距离的依赖信息。我读过的第一篇此类文章于2018年发表在AAAI上[1],神似咱们要读的这篇。因此我只详细介绍这篇论文,只在对比的时候捎带一下AAAI那篇。
最后再啰嗦一句,这只是一个最简单的综述,有空的时候再写一个长一点的。
简介
本文的三位作者有两位来自Texas A&M University,一位来自Washington State University。
研究问题:目前还没有针对图数据开发出有效的池方法,因此提出了图形池(gPool)层,它使用一个可训练的投影向量来测量图中节点的重要性;此外,GCN用于基于图的文本表示任务时,GCNs没考虑图中节点的顺序信息。为了解决这个限制,提出了混合卷积(hConv)层,它结合了GCN和常规卷积操作,把文本的图结构与常规的上下文特征融合在一起。
Text to Graph Conversion
选择文本中的名词、形容词和动词,其他作为停用词去掉。使用一个滑动窗口来决定两个术语之间是否有一条边(无向边)。如果两项之间的距离小于窗口大小,则添加这两项之间的无向边。比如图中所示,选择Japi、person、who、play、wow作为图中的节点,滑动窗口大小为4:
Model
Graph Pooling Layer
提出了gPool来应对graph,它自适应地选择重要节点的子集来形成更小的新图。假设一个图有N个节点,每个节点包含C个特征。可以用两个矩阵来表示这个图: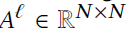 表示邻接矩阵,
表示邻接矩阵,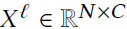 表示结点的特征。
表示结点的特征。
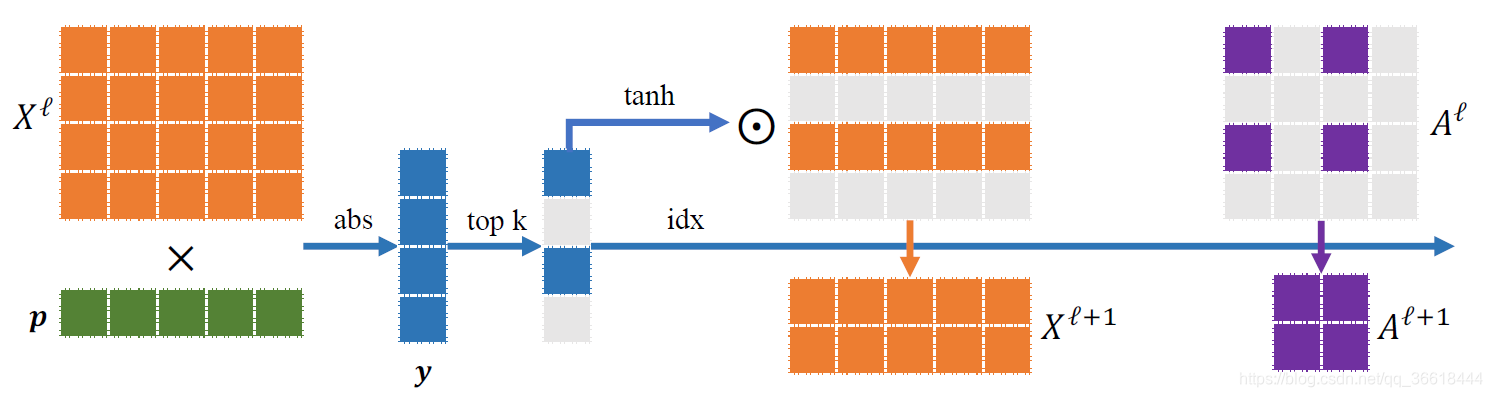
向量p是一个可训练的投影向量,将特征矩阵的每一行依次与向量p进行乘积,得到每个结点特征到p的相对距离: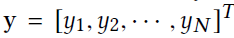 ,并使用tanh(y)得到
,并使用tanh(y)得到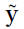 。通过在
。通过在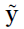 中选取最大的k个值,选出它们的所在的行,并在原特征矩阵与邻接矩阵中进行采样,最终得到池化之后的特征矩阵与邻接矩阵。这种池化操作应该是由文本转化过来的图独有的,因为特征矩阵X按照句子中单词的顺序进行排列,顺序是固定的,各个单词的相对顺序在池化之后依旧得以保留。
中选取最大的k个值,选出它们的所在的行,并在原特征矩阵与邻接矩阵中进行采样,最终得到池化之后的特征矩阵与邻接矩阵。这种池化操作应该是由文本转化过来的图独有的,因为特征矩阵X按照句子中单词的顺序进行排列,顺序是固定的,各个单词的相对顺序在池化之后依旧得以保留。
Hybrid Convolutional Layer
上文也说过,文本本质上是具有节点间顺序信息的网格状数据,因此可以应用常规的卷积操作。鉴于此,作者把传统的1-D卷积与GCN结合起来,同时捕获上下文信息与长距离的依赖关系,然后将两种不同的卷积输出的进行拼接。为了保证两个张量可以拼接,采用列维数作为通道数,所以被卷积的数据可以看做是row1col,也就是在row*1上进行卷积。这与文献【2】中提及的操作类似。


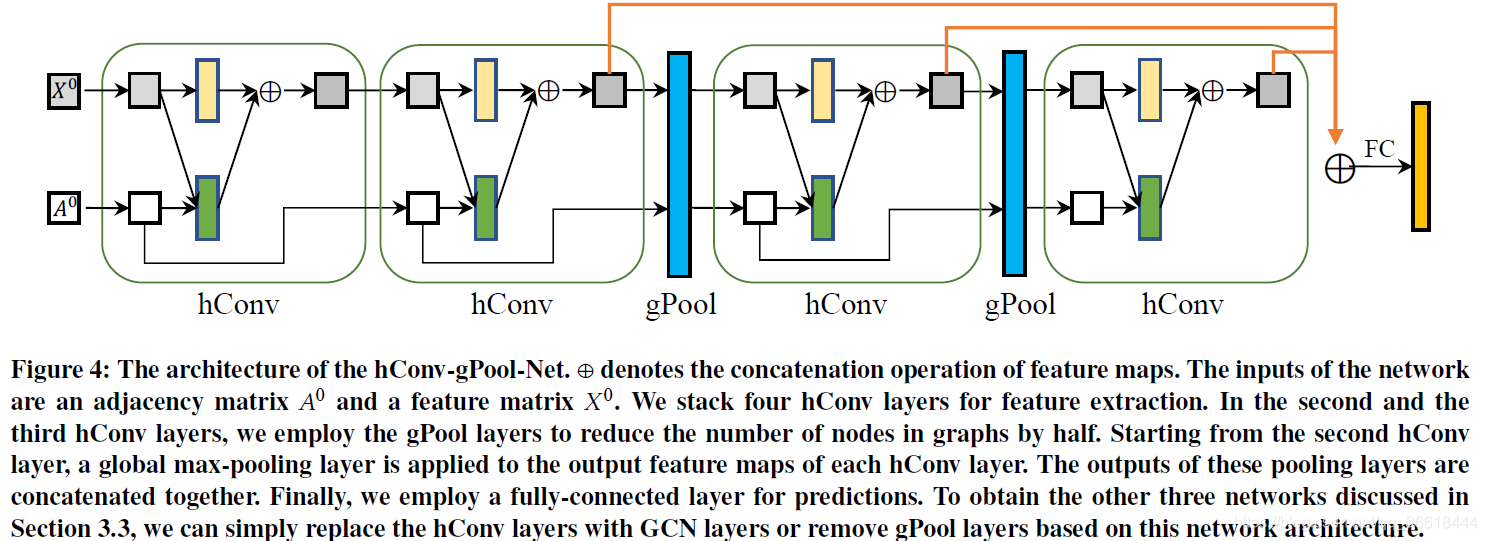
Network Architectures
基于gPool和hConv设计了4种网络架构,并在后续的实验中进行了分别讨论。
- GCN-Net:堆叠了4个标准GCN的卷积,每次卷积之后都要进行一个全局最大池化,池化之后的向量拼接在一起,最后全连接预测。
- GCN-gPool-Net:将提出的gPool层添加到GCN-Net中。从第二层开始,除了最后一层之外,在每个GCN层之后添加一个gPool层。在每个gPool层中,我们选择超参数k来将图中的节点数减少2倍。网络的所有其他部分与GCN-Net的部分保持相同。
- hConv-Net:将GCN-Net中的所有GCN层替换为本文提出的hConv层。
- hConv-gPool-Net:除了第一层和最后一层外,在每个hConv层之后添加gPool层。超参数k的选取原则与GCN-gPool-Net相同。此网络的结构如下图:
EXPERIMENTAL STUDY
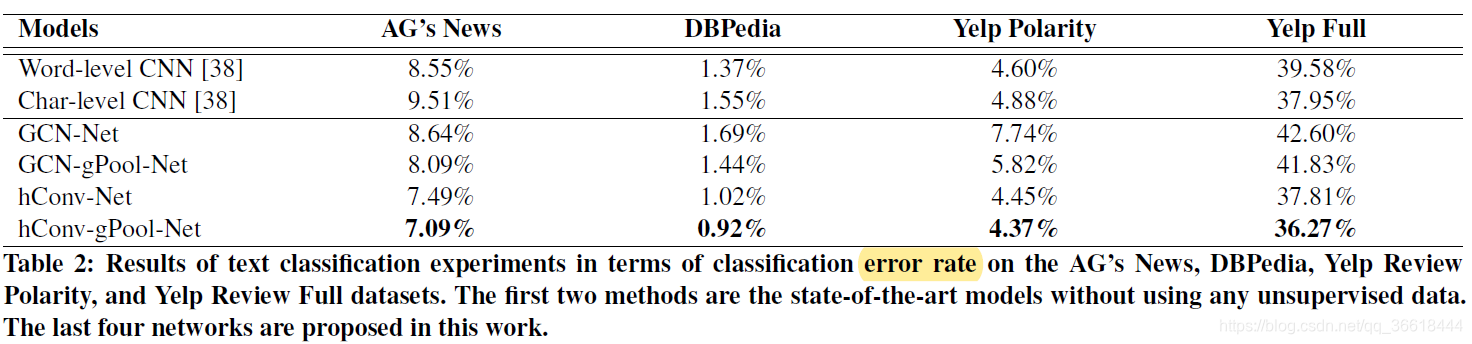
选取了四个数据集:AG’s News;Dbpedia【3】;Yelp Polarity和Yelp Full【4】,并在每个数据集上都进行了试验,并都取得了最优的效果。
参数选择
| 滑动窗口 | 对于以上四个数据集,根据最大结点数(100,100,300,256)选取不同的滑动窗口:4;4;10;10 |
| hidden layer | 4个GCN或hConv层分别输出1024、1024、512和256个feature map |
| 卷积核大小 | 因为把column当成了channel,因此卷积核的第二个维度是1 |
| 激活函数 | Relu |
| 梯度下降优化器 | the Adam optimizer |
| epoch | 60 |
| learning rate | 0.001,and decays by 0.1 at the 30th and the 50th epoch |
| dropout rate | 0.55 |
| batch size | 256 |
模型深度以及参数数量探讨
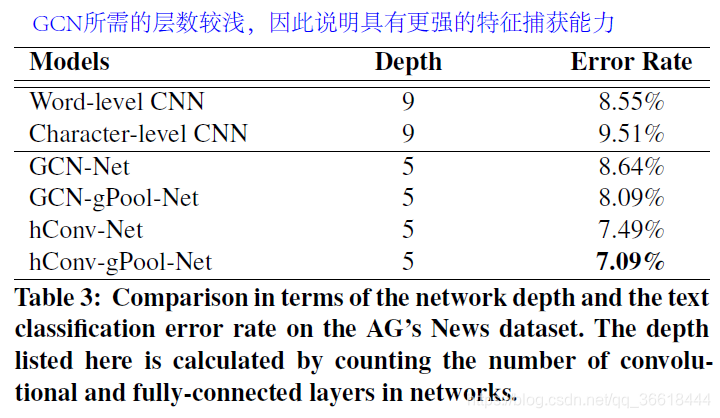
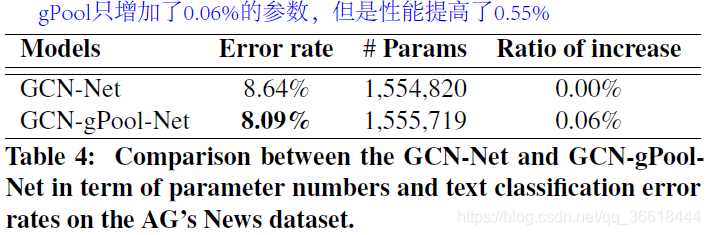
与文献[1]比较
文献1使用所有语料构建了一个大图,图中包含所有的需要分类的文本以及单词,因此图的大小为:单词数+文档数。结点之间的权重分为不同的表示形式,最终保留了权重值为正的边。其中,PMI(逐点互信息)是一种常用的词关联度量方法。

最终,使用Kipf的图卷积方式在整个大图上进行操作,同时学习单词与文档的潜在表示。同时,由于Kipf卷积可以应用于半监督的数据,此方法随着训练数据的减少,表现出强大的鲁棒性。最后是一个结构图:
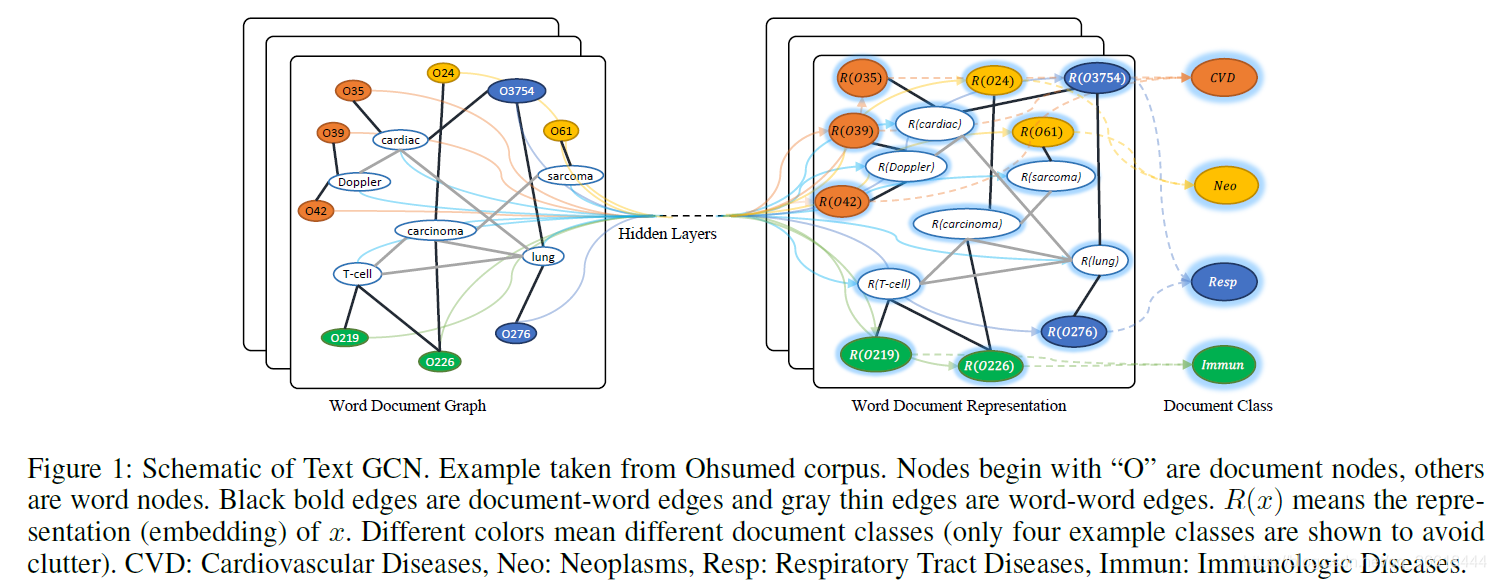
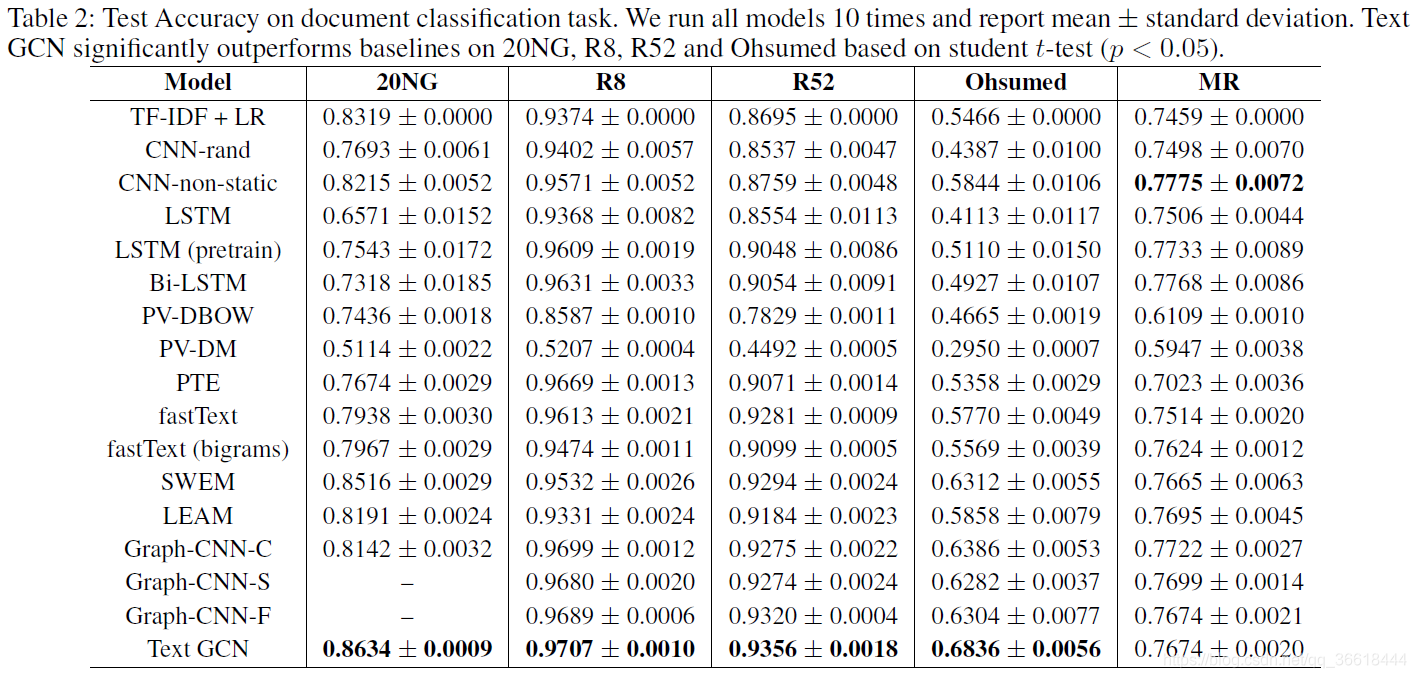
参考文献
【1】Yao L, Mao C, Luo Y. Graph convolutional networks for text classification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 7370-7377.
【2】Large-Scale Learnable Graph Convolutional Networks, KDD2018
【3】Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas,Pablo N Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick Van Kleef,Sören Auer, et al. 2015. DBpedia–a large-scale, multilingual knowledge base extracted from Wikipedia. Semantic Web 6, 2 (2015), 167–195.
【4】Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In Advances in neural information processing systems. 649–657.


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











