




 本文介绍了图神经网络(GNN)的背景和类型,特别是图卷积网络(GCN),并详细阐述了如何利用GCN进行文本分类。通过构建章节-单词和单词-单词的关系图,利用图的卷积过程提取节点特征,最终用于文本的分类任务。文章还提及了GCN的PyTorch实现和最新研究进展。
本文介绍了图神经网络(GNN)的背景和类型,特别是图卷积网络(GCN),并详细阐述了如何利用GCN进行文本分类。通过构建章节-单词和单词-单词的关系图,利用图的卷积过程提取节点特征,最终用于文本的分类任务。文章还提及了GCN的PyTorch实现和最新研究进展。
01
—
“图神经网络”是什么
过去几年,神经网络在机器学习领域大行其道。比如说卷积神经网络(CNN)在图像识别领域的成功以及循环神经网络(LSTM)在文本识别领域的成功。对于图像来说,计算机将其量化为多维矩阵;对于文本来说,通过词嵌入(word embedding)的方法也可以将文档句子量化为规则的矩阵表示。以神经网络为代表的深度学习技术在这些规范化的数据上应用的比较成功。但是现实生活中还存在很多不规则的以图的形式存在的数据。比如说社交关系图谱中人与人之间的连接关系,又比如说电子商务系统中的人与货物的关系等等,这些数据结构像下面这样:
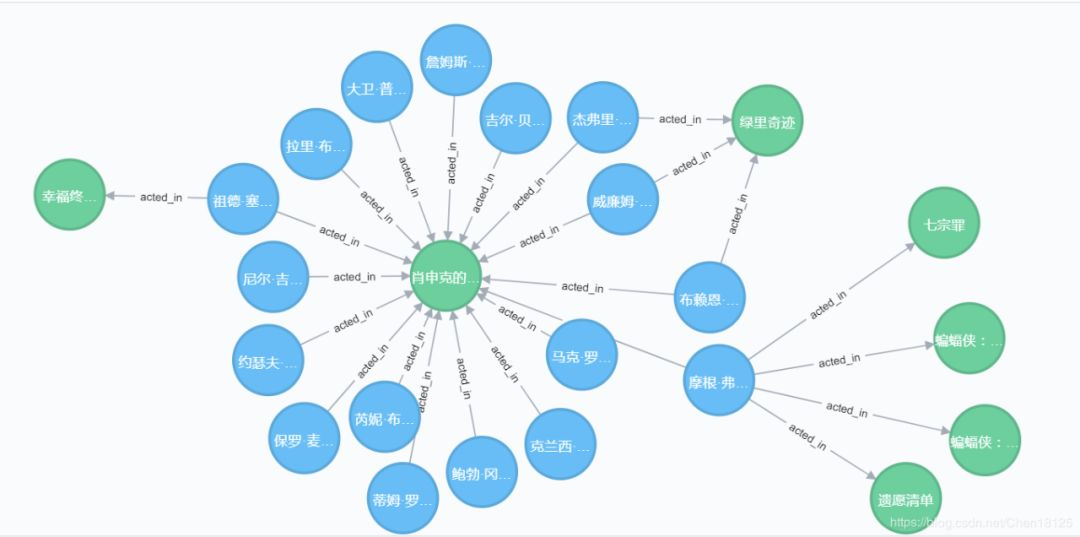
演员-电影 关系位于neo4j的图数据
图神经网络(Graph Neural Network, GNN)是指神经网络在图上应用的模型的统称,图神经网络有五大类别:分别是:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)。本文只重点介绍最经典和最有意义的基础模型GCN。
清华大学孙茂松教授组在 arXiv 发布了论文Graph Neural Networks: A Review of Methods and Applications,作者对现有的 GNN 模型做了详尽且全面的综述。
02
—
文本如何构建图
我们要构建一个具有定义好n个节点,m条边的图。
以经典的分类任务为例。我抽屉里有5本不同的机器学习书,里面一共有a个章节,同时所有书里面一共有b种不同的单词(不是单词个数,是所有的单词种类)。然后我们就可以给a个章节和b个单词标记唯一的id,一共n=a+b个节点,这是我们图的节点。
边的创建
我们有两种节点,章节和单词。然后边的构建则来源于章节-单词 关系和 单词-单词关系。对于边章节-单词 来说,边的权重用的是单词在这个章节的TF-IDF算法,可以较好地表示这个单词和这个章节的关系。这个算法比直接用单词频率效果要好[1]。单词-单词 关系的边的权重则依赖于单词的共现关系。我们可以用固定宽度的滑窗对5本书的内容进行平滑,类似于word2vector的训练取样本过程,以此计算两个单词的关系。具体的算法则有PMI算法实现。
point-wise mutual information(PMI)是一个很流行的计算两个单词关系的算法。我们可以用它来计算两个单词节点的权重。节点 i 和节点 j 的权重计算公式如下:

PMI(i, j)的计算方式如下:
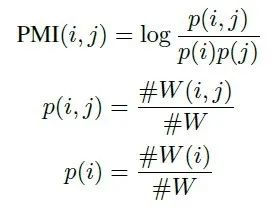
#W(i) 表示所有的滑窗中包含单词节点 i 的个数。
#W(i; j) 表示所有的滑窗中同时包含单词节点 i 和单词节点 j 的个数。
#W 是总的滑窗次数
PMI值为正则说明两个单词语义高度相关,为负则说明相关性不高。因此最后的图构造过程中只保留了具有正值的单词节点对组成的边。
图的节点和边确定了,接下来介绍如何应用图卷积神经网络进行一些学习应用。
2019年AAAI有一篇论文使用了此方法进行章节分类。题目“Graph Convolutional Networks for Text Classification”
03
—
图卷积神经网络
图卷积神经网络(Graph Convolutional Network, GCN)是一类采用图卷积的神经网络,发展到现在已经有基于最简
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









