







1. 模型概述
这篇论文做的是视觉问答。模型的主要创新点在于将来自不同区域的视觉特征 [ v 1 , v 2 , . . . , v K ] [v_1,v_2,...,v_K] [v1,v2,...,vK]和文本查询q映射到一个共享空间中,然后在该空间中通过计算内积来衡量两种模态之间的相关性,然后加权求和等。
模型结构为:
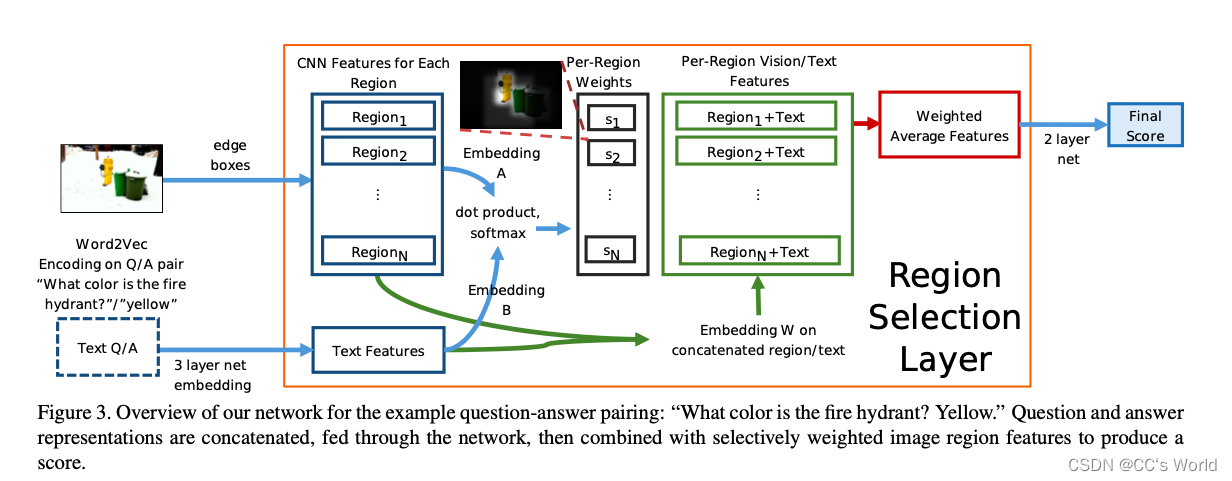
2. 视觉问答的目标:
我们的模型针对 VQA 数据集的多项选择任务进行了训练。 对于给定的问题及其相应的选择,我们网络的目标旨在以结构化学习的方式最大化正确和错误选择之间的差距。 我们通过在预测置信度 y 上使用hinge loss来实现这一点。
在我们的设置中,多个答案在不同程度上是可以接受的,因为正确性是由 10 个注释者的共识决定的。 例如,大多数人可能会说围巾的颜色是“蓝色”,而其他一些人会说“紫色”。 考虑到这一点,我们通过返回特定答案的注释者数量的差距来缩放边距:
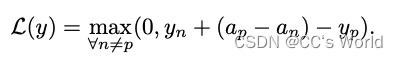
上述目标要求正确答案的分数 (yp) 至少比从一组错误选择 (n̸= p) 中选出的最高分数错误答案 (yn) 的分数高出一些差距。 例如,如果 10 个注释者中有 6 个回答 p (ap = 0.6),而 2 个注释者回答 n (an = 0.2),那么 yp 的得分应该至少比 yn 高 0.4。
3. Region Selection Layer
我们的区域选择层选择性地将输入文本特征与来自图像相关区域的图像特征相结合。 为了确定相关性,该层首先将图像特征和文本特征投影到共享的 N 维空间中,然后在每个问答对和所有可用区域之间计算内积。
令 V = (⃗v1 , ⃗v2 , …⃗vK ) 是从 K 个图像区域中提取的视觉特征的集合,⃗q 是问题和候选答案对的特征表示。计算第 j 个区域和查询之间的相关权重的前向传递计算如下:
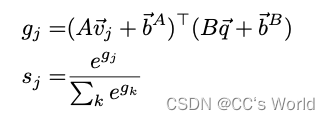
然后使用向量 ⃗s 计算所有区域特征的加权平均值。 我们首先通过将 d⃗j 定义为⃗vj 与⃗q 的concat,为每个区域构建语言视觉特征表示。 然后在计算加权平均特征向量 ⃗z 之前,用 W 和 ⃗bW 投影每个特征向量。
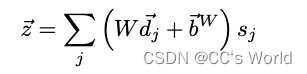















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









