







1.3.1 损失函数
有时候,我们会把一些神经网络的输出值设计为连续范围的值。例如,一个预测温度的网络会输出0~100℃的任何值。
也有时候,我们会把网络设计成输出true/false或1/0。例如,我们要判断一幅图像是不是猫,输出值应该尽量接近0.0或1.0,而不是介于两者之间。
手写数字的图像进行分类是一个分类(classification)任务,更适合使用其他损失函数。一种常用的损失函数是二元交叉熵损失(binary cross entropy loss),它同时惩罚置信度(confidence)高的错误输出和置信值低的正确输出。PyTorch将其定义为nn.BCELoss()。
我们的网络对MNIST图像进行分类,属于第二种类型。在理想情况下,输出节点中应该只有一个接近1.0,其他全部接近0.0。
复制之前的笔记本,将损失函数从MSELoss()更改为BCELoss()。
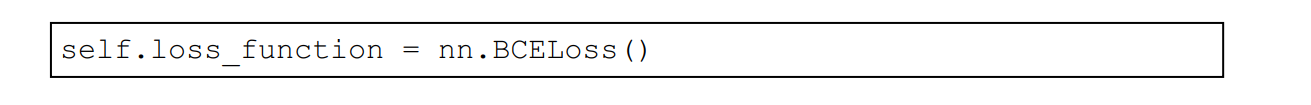
让我们像以前一样训练网络3个周期。测试数据集的性能得分(准确率)从87%提高到了91%。
1.3.2 激活函数
S型逻辑函数在神经网络发展的早期被广泛使用,因为它的形状看起来比较符合自然界中的实际情况。科学家们普遍认为,动物的神经元之间在传递信号时,也存在一个类似的阈值。此外,也因为在数学上它的梯度较容易计算。
然而,它具有一些缺点。最主要的一个缺点是,在输入值变大时,梯度会变得非常小甚至消失。这意味着,在训练神经网络时,如果发生这种饱和(saturation),我们无法通过梯度来更新链接权重。

其他可选的激活函数有许多。一个简单的解决方案是使用直线作为激活函数,而直线的固定梯度是永远不会消失的。

这个激活函数被称为线性整流函数(rectified linear unit), 在PyTorch中被定义为ReLU()函数。
实际上,如果所有负值的斜率都是0,小于0的输入部分同样存在梯度消失的问题。一个简单的改良是在函数的左半边增加一个小梯度,这被称为带泄漏线性整流函数(Leaky ReLU)。

让我们将损失函数重置为MSELoss(),并将激活函数改为LeakyReLU(0.02),其中0.02是函数左半边的梯度。

重新训练网络3个周期。以我的模型来说,在测试数据集的准确率现在达到了97%。从之前的87%到现在的97%是一个巨大的飞跃,已经非常接近使用更复杂网络的工业级纪录。
1.3.3 改良方法
我们还可以改良反向传播梯度更新网络权重的方法。在此之前,我们使用的是一种相对简单的随机梯度下降法,这也是我们在《Python神经网络编程》中所使用的方法。这种方法很流行,因为它很简单,对于计算性能的要求也较低。
随机梯度下降法的缺点之一是,它会陷入损失函数的局部最小值 (local minima)。另一个缺点是,它对所有可学习的参数都使用单一的学习率。
可替代的方案有许多,其中最常见的是Adam。它直接解决了以上两个缺点。首先,它利用动量 (momentum)的概念,减少陷入局部最小值的可能性。我们可以想象一下,一个沉重的球如何利用
动量滚过一个小坑。同时,它对每个可学习参数使用单独的学习率,这些学习率随着每个参数在训练期间的变化而改变。
让我们重新设置代码,保留MSELoss()和S型激活函数,只将优化器从SGD改为Adam。
再以3个周期来训练网络。对我的模型来说,在测试集的准确率再次达到了97%左右。与87%相比,这同样是一个巨大的进步,与使用Leaky ReLU激活函数的效果一样。
1.3.4 标准化
神经网络中的权重和信号(向网络输入的数据)的取值范围都很大。之前,我们看到较大的输入值会导致饱和,使学习变得困难。
大量研究表明,减少神经网络中参数和信号的取值范围,以及将均值转换为0,是有好处的。我们称这种方法为标准化(normalization)。
一种常见的做法是,在信号进入一个神经网络层之前将它标准化。
让我们把代码重置回使用MSELoss、S型激活函数以及SGD优化器。现在,在网络信号输入最终层之前使用LayerNorm(200),将它们标准化。

在训练3个周期之后,模型在测试数据集的准确率是91%,相比原始网络的87%有所进步。
1.3.5 整合改良方法
让我们把以上的改良方法整合到一起,包括BCE损失、Leaky ReLU激活函数、Adam优化器以及分层标准化。
由于BCE只能处理0~1的值,而Leaky ReLU则有可能输出范围之外的值,我们在最终层之后保留一个S型函数,但是在隐藏层之后使用LeakyReLU。

训练3个周期之后的准确率是97%。看来整合我们的优化方案无法使准确。
1.3.6 学习要点
- 在使用新的数据或者构建新的流程前,应尽量先通过预览了解数据。这样做可以确保数据被正常载入和变换。
- PyTorch可以替我们完成机器学习中的许多工作。为了充分利用PyTorch,我们需要重复使用它的一些功能。比如,神经网络类需要从PyTorch的nn.Module父类继承。
- 通过可视化观察损失值, 了解训练进程是很推荐的。
- 均方误差损失适用于输出是连续值的回归任务;二元交叉熵损失更适合输出是1或0(true或false)的分类任务。
- 传统的S型激活函数在处理较大值时,具有梯度消失的缺点。这在网络训练时会造成反馈信号减弱。ReLU激活函数部分解决了这一问题,保持正值部分良好的梯度值。LeakyReLU进一步改良,在负值部分增加一个很小却不会消失的梯度值。
- Adam优化器使用动量来避免进入局部最小值,并保持每个可学习参数独立的学习率。在许多任务上,使用它的效果优于SGD优化器。
- 标准化可以稳定神经网络的训练。一个网络的初始权重通常需要标准化。在信号通过一个神经网络时,使用LayerNorm标准化信号值可以提升网络性能。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









