





A Data-Driven Self-Supervised LSTM-DeepFM Model for Industrial Soft Sensor
论文代码链接: https://github.com/iamownt/LSTM-DeepFM
数据集: https://www.kaggle.com/datasets/podsyp/production-quality
摘要
软传感器作为工业智能的重要范例,广泛应用于工业生产中,以实现对包括产品质量在内的生产状态的有效监测和预测。数据驱动的软测量方法已经引起了人们的关注,但由于具有不同特征的复杂工业数据、非线性关系和大量未标记样本,这些方法仍然具有挑战性。本文提出了一种用于工业软测量的数据驱动自监督长短期记忆深度因子分解机(LSTM DeepFM)模型,其中提出了一个主要包括预处理和微调阶段的框架,以探索不同的工业数据特征。在预处理阶段,首先对LSTM自动编码器进行无监督预处理。然后,基于两种自监督掩码策略,LSTM-dep可以探索特征之间的相互依赖性以及时间序列中的动态波动。在微调阶段,依靠预处理表示,可以分别从LSTM、deep和FM分量中提取时间、高维和低维特征。最后,在实际挖掘数据集上的实验表明,与基于堆叠自动编码器的模型、基于可变自动编码器的模式、半监督并行DeepFM等相比,该方法达到了最先进的水平。
挑战
- 许多模型仅对行业数据的特定特征进行分析和建模,无法实现各种行业数据特征的融合学习。特别是,由于工业结构日益复杂,仍然缺乏一个系统的软传感器框架,用于具有不同数据特征的复杂工业过程预测。
- 大多数现有模型通常是从时间序列或单个时间步长建模的。重要的是要考虑所有时间步骤的动态时间相关性以及每个时间步骤的关键指标和过程变量的内在非线性关系。然而,很少有模型同时考虑这两种关系。
- 一些半监督学习方法(co-training and graph-based methods)不适用于噪声数据或少量标记样本场景。而一些方法,如传统的自动编码器,只能重建输入,但缺乏对特征和时间序列相互依赖关系的有效挖掘。
创新
- 针对复杂工业过程预测,提出了一种新的系统软测量框架,其中包括一种处理数据序列的方法。该方法基于大规模过程数据的表示学习来处理工业数据噪声。同时,它利用自监督学习有效地提取隐藏在大量未标记数据中的有用信息。因此,可以很好地实现各种工业数据特征的融合学习。
- 提出了一种LSTM-DeepFM结构,用于复杂环境下的多特征提取。LSTM自动编码器可以提取工业数据中的时间信息。通过融合这些信息,DeepFM可以更好地揭示过程变量和关键指标之间的隐含相关性。
- 提出了一种新的自监督学习方法,用于潜在多维信息的多域特征挖掘。基于两种掩码策略,该方法可以探索特征之间的相互依赖关系以及时间序列中的动态波动,可以充分挖掘未标记样本的信息。
模型
一、LSTM
二、DeepFM
- FM(Factorization Machines,因子分解机)早在2010年提出,作为逻辑回归模型的改进版,拟解决在稀疏数据的场景下模型参数难以训练的问题。并且考虑了特征的二阶交叉,弥补了逻辑回归表达能力差的缺陷。
知乎上的一个讲解链接: https://zhuanlan.zhihu.com/p/342803984 - DeepFM
讲解链接: https://zhuanlan.zhihu.com/p/361451464
三、整体框架
整体流程
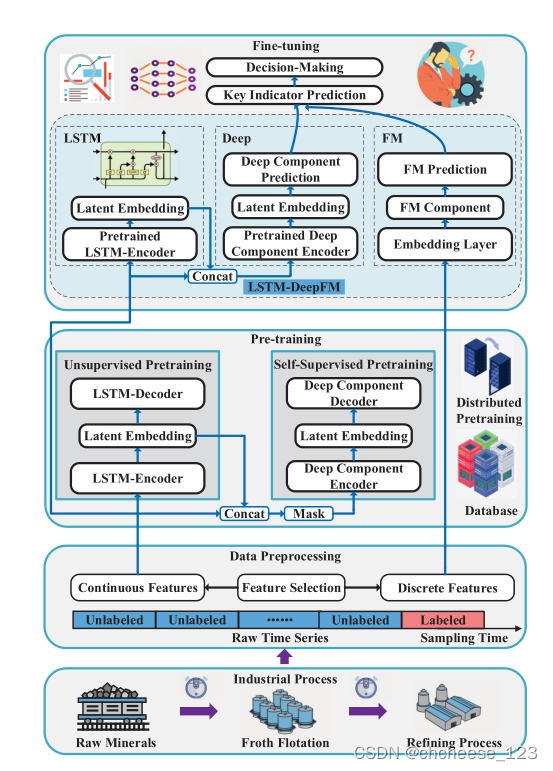
具体方法
1.数据预处理
(1)数据装箱:
采用基于k-means的binning方法来有效地抑制数据噪声。它确保每个箱子中的所有值都具有1-D k均值聚类的相同最近中心。
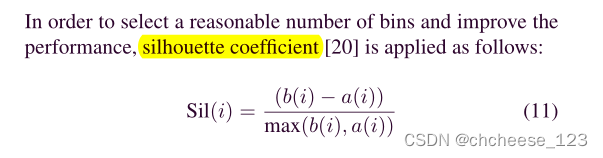
(2)特征选择
PIMP方法:“Permutation impottance: A corrected feature importance measure,”

2.预训练
预训练阶段
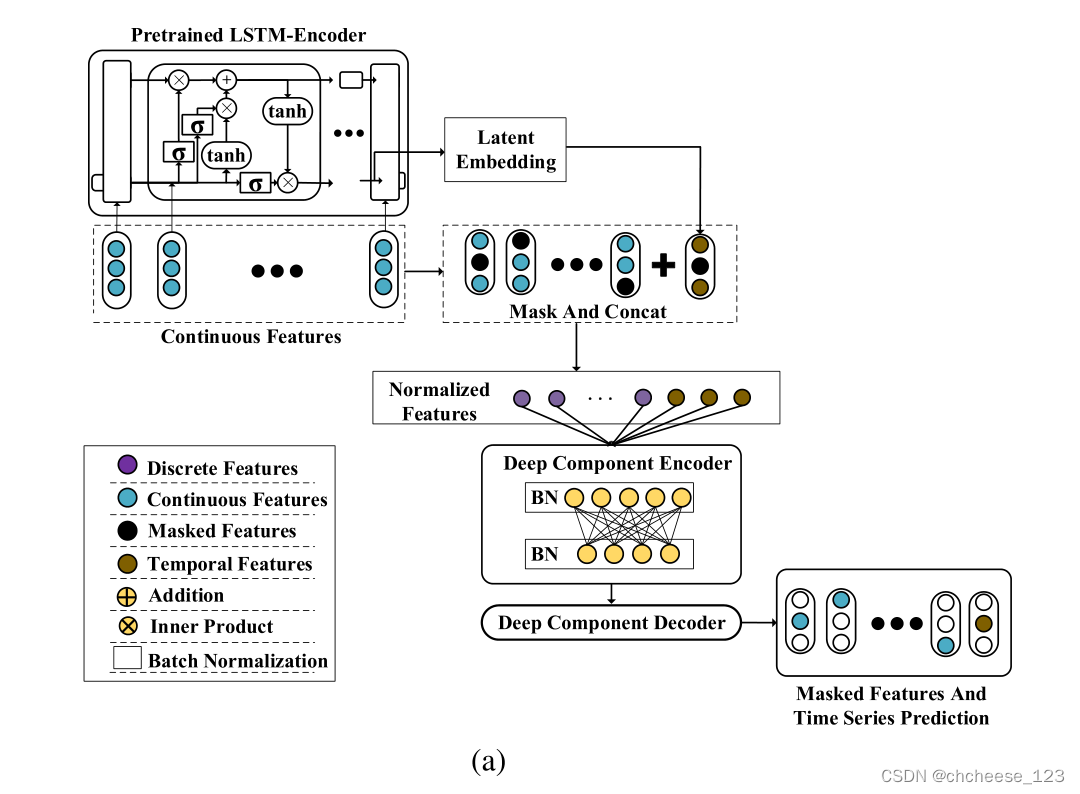
Self-Supervised Learning:

贴一个半监督学习的概述链接: https://blog.csdn.net/ice110956/article/details/13775071
3.微调
微调阶段
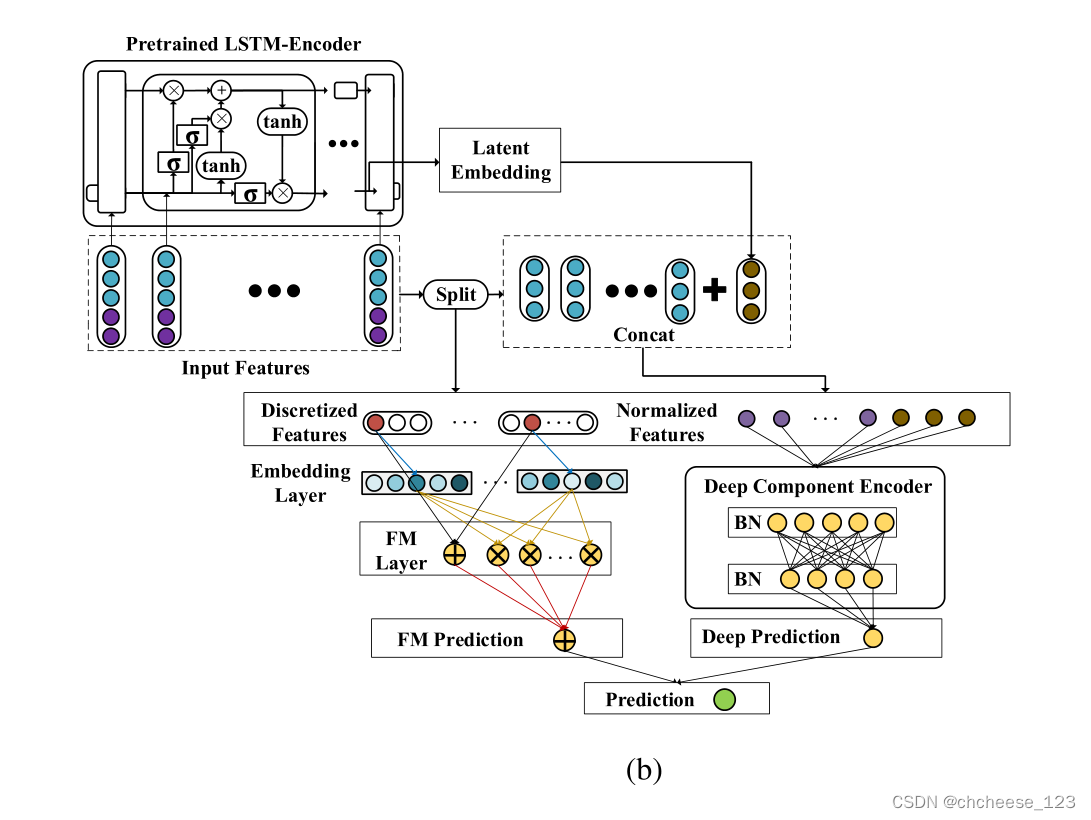
在预训练阶段,使用大量标记样本和未标记样本计算自监督训练目标函数。然而,在微调阶段,只使用标记的样本。通过掩蔽自监督学习任务的无监督表示学习,该模型能够更快地收敛,在微调阶段具有更好的泛化性能。这样,可以充分利用标记和未标记的样品,从而获得更多与质量相关的信息
实验
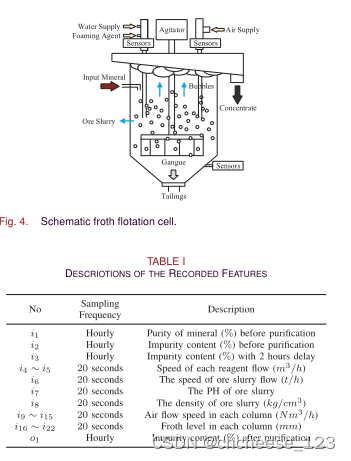
本文提出了一种用于工业软测量预测的数据驱动自监督LSTM-DepFM模型。一方面,LSTM DeepFM模型结构可以提取时间序列中的低维、高维和时间特征。另一方面,自监督学习方法可以探索特征之间的相互依赖关系以及时间序列中的动态波动。因此,可以很好地实现各种工业数据特征的融合学习。通过与SVR、LGB、VAEWGAN、VAE-NN、GSTAE、SS PdeepFM和SSFAN进行比较,在真实泡沫浮选数据集上的实验证明了该方法的有效性和优越性能。
未来的工作应侧重于如何保持过程可靠性和支持持续改进,以及进一步探索在线模型预测控制技术。

















 3721
3721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









