







一、内存知识
内存(memory),又叫主存,是cpu与其他设备沟通的桥梁,主要用来临时存放数据,配合cpu工作,协调cpu的处理速度
-
1、理解
- 硬盘数据、外设数据、网络传输数据,要进入cpu前,都要先进入内存
- 临时存放,在断电后,内存内容就会丢失
- 当打开一个软件,就会分配虚拟内存、物理内存空间,cpu读取虚拟内存
- 程序在启动时,并不会把所有的数据都加到内存
- 32位的系统,最大支持的内存条,只有4g,64位系统,最大可以支持128T
- 程序在启动时,会有一个内存配置信息,就会告诉系统,我要在整个内存条中,申请多少m内存空间
-
2、内存的组成:内存地址、存储单元
- 内存地址:一个编号,用于指示数据位置(绝对地址、相对地址)
- 存储单元:存放实际数据的地方
- 内存地址与存储单元的关系:门牌号和房屋
- 门牌号找到你的家庭地址(内存地址),房屋能装人和各种家居用品(存储单元)

- 数据大小
- 写过代码的都知道,定义一个数据,要声明数据类型:
- 为什么要声明这样一个类型?
- 为了分配存储空间大小,存储大小一定要比实际数据大,才能装下实际数据(东西多,袋子小就装不下)
- 1、单个数据:int、float、char…
- 2、连续数据:列表,数组…
- 分配一个连续的存储单元
- python:列表 [8,‘nmb’,[‘vip8’,‘vip12’],]
- 连续的存储单元–> 内存卡
- 数据存储是不是可以更复杂?
- 所以,就有了数据结构
- 列表中,插入一个数据,要把插入位置之后的所有数据都移动位置,所以,这种速度是比较慢,这个时候,我们可以用链表
- 分配一个连续的存储单元
-
3、内存—树形结构
- 为什么要声明这样一个类型?
- 写过代码的都知道,定义一个数据,要声明数据类型:
- 门牌号找到你的家庭地址(内存地址),房屋能装人和各种家居用品(存储单元)
-
4、数据结构
- 堆栈
- 不是一个,而是两种不同的数据结构
- 栈(stack)
- LIFO== Last In First Out 后进先出
- 就像收纳箱装东西,先进去的在最下面;取出来时,最上面的最先出来
- 装入叫压入(push),取出叫弹出(pop)
- 存放程序的变量
- LIFO== Last In First Out 后进先出
- 队列(queue)
- FIFO == First In First Out 先进先出
- 就像排队打饭(顺序排列)/循环转圈(循环队列)
- 堆(heap)
- 类似图书馆书架上的图书
- 一种经过排序的树形结构
- 存放程序的对象
- FIFO == First In First Out 先进先出
- 堆栈
-
二、内存使用
- 一个程序运行起来,需要分配一块内存空间,无异常时,就在分配的这块内存空间弹性伸缩存储
- 这个空间,至少会包括一块栈区和一块堆区,还会包括其他

- 栈区:存放程序中的局部变量,变量有一定的作用域,离开作用域,空间就会被释放,所以更新速度快,生命周期短
- 堆区:存放程序中的数组和对象。凡是new出来的都存在堆里,如果数据消失,实体不会马上释放的
- 就像男女朋友确认关系后,所有人都知道了。某天掰了,他们俩没有明确关系了,但是双方可能都不能马上找到新朋友,要被另外的单身份子收割,需要一定的时间
- 一个程序: 如: 这个程序启动要 256m
- 先有一个虚拟内存地址 + 物理内存地址
- 虚拟内存地址: 记录物理内存中存储了哪些数据,在什么地方
-
1、典型案例:JVM(java虚拟机)
-
包含程序计数器,java虚拟机栈,本地方法栈,方法区,堆内存
- 1)程序计数器:记录程序执行字节码的行号指示器
- 2) java虚拟机栈:java方法执行时的内存模型
- 3)方法区:共享内存区域,存储已被虚拟机加载的数据
- 4)堆区:
-
堆内存:

- 划分为新生代,老年代,永久代(元空间)
- 1)新生代New:昙花一现,朝生夕死的对象( 比如你写的代码的方法里面的变量)
- 新生代又分为:Eden,Surivivor1,Surivivor2
- Eden:存放jvm刚分配的对象
- Surivivor:两个空间一样大,Eden中未被GC的对象,经过copy算法,会在这两个区间来回copy,默认拷贝超过15次,就被移入Tenured年老代
- 新生代又分为:Eden,Surivivor1,Surivivor2
- 2)老年代Teunred:大对象or多次被GC后还在的对象(顽固分子)
- 3)永久代Perm(元空间):类信息,常量,静态变量等
- 1)新生代New:昙花一现,朝生夕死的对象( 比如你写的代码的方法里面的变量)
-
堆内存的空间要经过不断分配和回收,才能得到高效的利用,那哪些会被回收,什么时候回收,怎么回收呢?
- 划分为新生代,老年代,永久代(元空间)
-
-
-
2、回收(GC)
- YGC(minor GC),针对新生代(young generation)得den区进行资源回收
- FGC(major GC),处理的区域同时包括新生代和年老代
- 不管是YGC还是FGC,都会造成一定程度的卡顿,及时采用新的垃圾回收算法,也只能减少卡顿时间,不能完全消除卡顿(比如删大文件,就会卡一下)
- FGC通常比较慢,少则几百毫秒,多则几秒,如果频繁了,会导致性能变差
- YGC一般几十到上百毫秒,如果耗时达到秒级,频繁,还会导致性能变差
-
性能测试中,对gc是要多关注
- 如果新生代资源分配过多,那么老年代这变就要少,老年代的空间,我可能就要经常的进行FGC, FGC频率高了,那么累计的gc的时间就长,导致性能比较差
- 如果新生代分配的资源少了,那么老年代就分配多些,我的新生代的资源回收频率YGC就要高, 那么累计的ygc的时间也可能长,我的性能也可能较差
- 那么两者之间有完美的比率吗?
- 是没有的,比如写个查找,有人用递归,有人用循环,这样分配的内存是不一样的。只能边调试边测试(改堆栈的配置)
-
哪些会被回收?
- 1、是否已死:引用计数法(被引用的计数等于0,回收),可达性算法(没有引用链,回收)
- 2、垃圾回收法
-
什么时候回收?
- 分配空间不足(注意:不是内存空间不足),才会执行回收
- 定时回收
-
怎么回收?
- 垃圾回收算法:新生代-复制算法(清理eden,将存活的复制到survivor)
- 老年代-标记整理算法(先标记,再整理,就像电脑删数据,先点击删除丢到回收站,然后在回收站那边再整理下进行删除)
- 内存资源回收
- 刚刚我们讲到了资源回收,只是在讲堆的时候才讲,其他时候没有,因为 本地方法栈,程序计数器,虚拟机栈 ,这些是不需要进行垃圾回收的
- java的内存回收机制,内存空间中垃圾回收的工作由垃圾回收器(garbage collector)完成的,它的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别,如果对象正在被引用,name称其为存活对象,反之,如果对象不再被引用,则为垃圾对象,可用回收其占据的空间,用于再分配
-
3、常见问题
4、内存相关参数
| 参数 | 含义 |
|---|---|
| -Xms | 初始堆大小 |
| -Xmx | 最大堆空间 |
| -Xmn | 设置新生代大小 |
| -XX:SurivivorRatio | 新生代eden空间,from空间,to空间的比例关系(8:1:1) |
| -XX:PermSize | 方法区初始大小 |
| -XX:MaxPermSize | 方法区最大值 |
| -XX:metaspaceSize | 元空间GC阈值 |
| -XX:MaxMetaspaceSize | 最大元空间大小 |
| -Xss | 栈大小 |
| -XX:MaxDirectMemorySize | 直接内存大小,默认为最大堆空间 |
三、内存分析
1、查看内存

-
Mem:物理内存
- total(合计)、used(已被使用)、free(未被使用)、shared(共享)、buff/cache(缓冲区/缓存)、available(新进程可分配)
- buff:对原始磁盘块(操作系统与磁盘交流的最小单位)的临时存储
- cache:从磁盘读取文件的页缓存
- availabe=free(未被使用)+可回收的
- total(合计)、used(已被使用)、free(未被使用)、shared(共享)、buff/cache(缓冲区/缓存)、available(新进程可分配)
-
swap:交换分区
- 一种虚拟内存,由磁盘虚拟化而来,存在于内存和磁盘之间,因为磁盘和内存之间存在差异
-
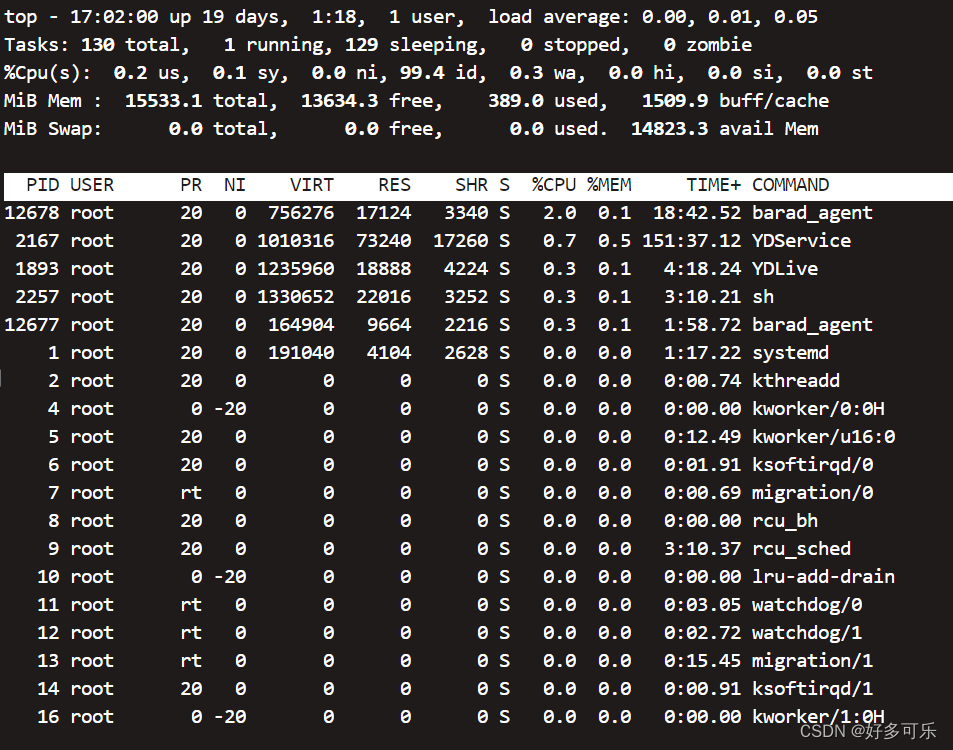
2)top:Ee
-
VIRT:虚拟内存使用量 VIRT=SWAP+RES
-
RES:物理内存使用量+未换出的虚拟内存大小 RES=CODE+DATA
-
SHR:共享内存的使用量
-
SWAP:虚拟内存中被换出的大小
-
CODE:代码占用的物理内存大小
-
DATA:代码之外的部分占用的物理内存大小
-
%MEM:使用的物理内存占总内存的比率
-
2、内存分析工具
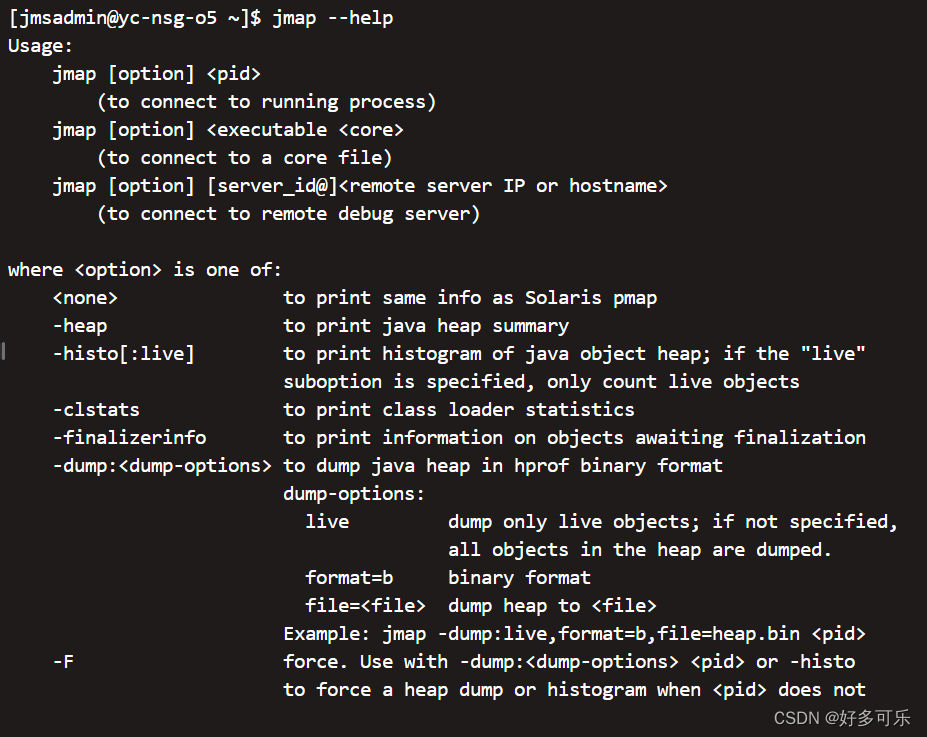
- 命令:
jmap [options] pid - options
-dump:生成java堆栈的快照信息-heap:显示java堆详细信息,使用哪种回收机制,参数配置,分代情况-histo:显示堆中对象统计信息,包括类,实例数量- jmap -F -dump:format=b,file=文件名.bin 进程id ===执行时间较长,需要等待结束
jmap -F -dump:live,format=b,file=xxx .bin pid
- 命令:
-
3、确定oom问题
-
方法1、使用jmap进行定位
-
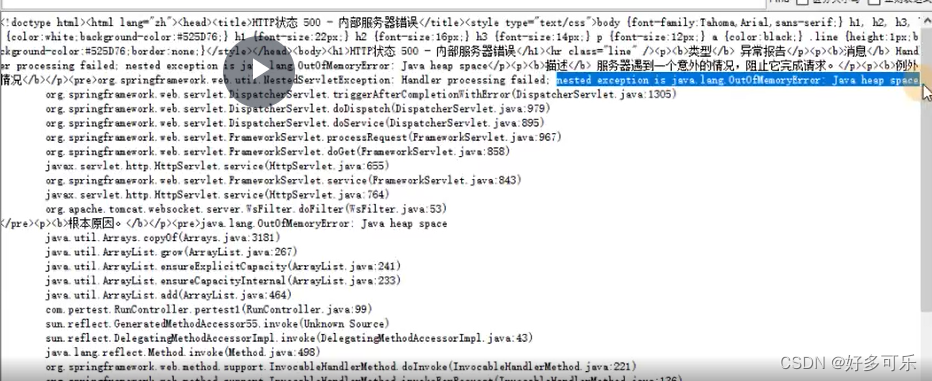
看请求的响应信息, 一般的情况下,出现内存溢出问题,在响应信息中都会有所体现
nested exception is java.lang.OutOfMemoryError: Java heap space
-
有些项目,在log日志中,会有体现(不一定有)
-
我们看系统的内存
- 内存并没有被完全消耗掉
- 定位这个问题:
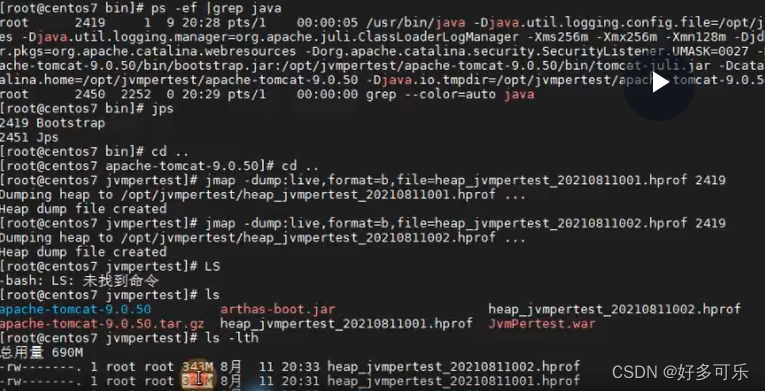
- 生成内存溢出堆栈文件
- 获得进程id
ps -ef |grep javajps jmap -dump:live,format=b,file=heap_xxxtest_20210811002.hprof 2419
- 运行完毕后它会生成hprof结尾的二进制文件(但是这个文件我们 tail -f 看是会乱码的)
- 获得进程id
- 生成内存溢出堆栈文件
-
-
方法2、使用arthas进行定位
- 介绍
- arthas是阿里开源的java诊断工具,实现了jvm自带的几乎所有诊断功能,深受jvm分析人员喜爱
- 安装
curl -O https://arthas.aliyun.com/arthas-boot.jar
- 工具上手:
java -jar arthas-boot.jar - 如果需要获取帮助:
java -jar arthas-boot.jar --help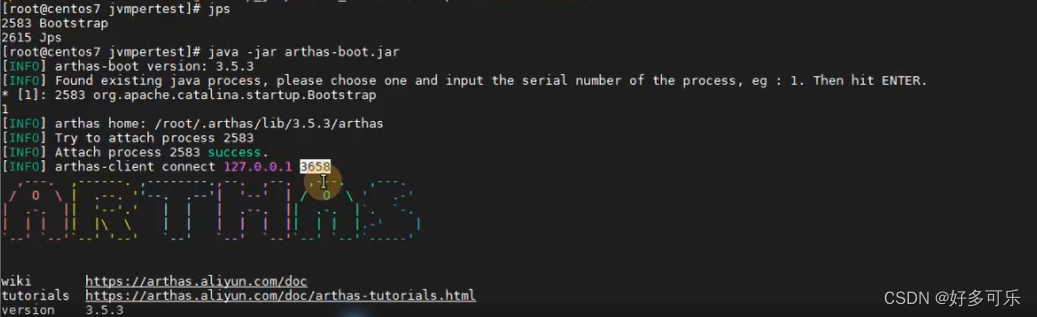
- 内存泄露抓包
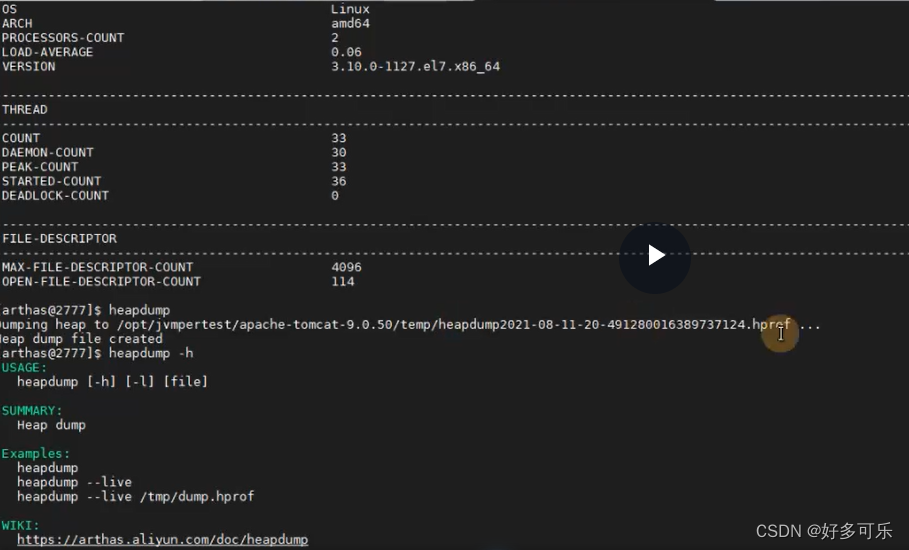
- dashboard:显示当前系统实时数据的面板
- heapdump:生成hprof文件(不建议把这个文件放桌面,建议新建个文件夹把它丢进去,因为mat打开后会生成非常多分析文件,看着很乱)
- 介绍
-
-
4、使用MAT进行分析
- 解压MemoryAnalyer工具
- 打开工具,open heap dump
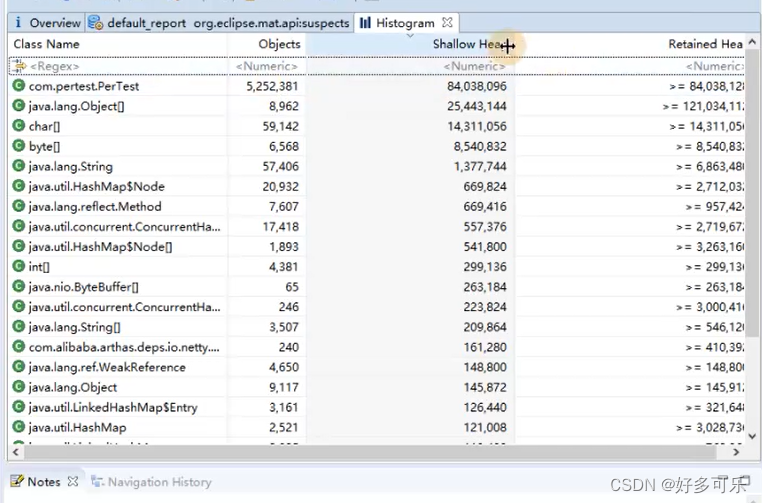
- 点击 histogram
- histogram:列出内存中的对象,对象的个数及大小
- class name 类名,出问题的类:com.xxx.xxx
- objects(类的对象数量,对象被创建的次数)
- shallow(浅)heap对象内存消耗大小,不包括其他对象的引用
- retailed(保留)heap,被GC能回收的内存的总和
- histogram:列出内存中的对象,对象的个数及大小
- 没有java基础的同学, hprof文件给开发去定位, 有基础的同学,mat工具自己来分析
-
5、JVM分析
-
输出GC日志
- jvm的启动参数中加入
-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCtimestamps -XX:+PrintGCApplicationStopedTime(包含IO操作,所以生产环境一般不添加,测试环境也只有定位问题才开启,否则损耗性能)
启动后输出:GC概要信息、详细信息、gc时间、gc造成的应用暂停时间
- jvm的启动参数中加入
-
常用分析工具
-
1、 jcosole
- jdk自带的内存分析工具,有图形界面(windows才有,linux没有),可以查看jvm内存信息,线程信息,类加载信息,MBean信息
jconsole.sh pid
-
2、 jstat
- jdk自带的分析GC工具,参数很多
jstat -gcutil pid 10000间隔1w毫秒显示一次gc信息

- 参数说明:
- S0:新生代survivor0区
- S1:新生代survivor1区
- E:新生代eden区
- O:年老代
- M:方法区回收比例
- CSS:类空间回收比例
- YGC:minor gc次数
- YGCT:minor gc耗费的时间
- FGC:full gc的次数
- FGCT:full gc的耗时
- GCT:gc总耗时
- 参数说明:
-
-
总结一下:
-
cpu相关问题,应用服务器中高频率出现
-
内存: 工作中经常遇到,比较难
-
网络:见的多,但是不是最难,只是因为大家网络知识跟不上
-
磁盘问题: 相对来说问题是最少, 一般集中在文件服务器\数据服务器
-
-















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









