







目录
一、数据操作
1. 创建 tensor
-
创建张量需要三个信息:
- 形状
- 元素类型(用
dtpye指定和a.dtype查看,默认创建的张量dtype=torch.float32) - 每个元素的值
z = torch.Tensor(3,4,2) #创建一个 3×4×2 的张量,元素值随机 s = torch.Tensor(2,3).fill_(1) #创建指定大小的张量,元素值都为1 x = torch.Tensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]) #用指定的列表创建张量,这个张量大小为 2×5 """ >>> x.dtype torch.float32 """ x = torch.tensor([1,2,3,4]) #将其他类型转换为张量表示,张量的 dtype 会根据里面的最高级的元素类型选择 """ >>> x = torch.tensor([1,2,3,4,5]) >>> x.dtype torch.int64 >>> x = torch.tensor([1,2,3,4.0,5]) >>> x.dtype torch.float32 """ t = torch.rand(3,3) #创建大小为 3×3 的张量,张量的值满足 [0,1] 之间的均匀分布 t = torch.randn(3,3) #创建大小为 3×3 的张量,张量的值满足均值为 0,方差为 1 的正态分布 m = torch.zeros(3,3) #创建全 0 的张量 n = torch.ones(3,3) #创建全 1 的张量 #创建从 0 开始,到 12 之前结束的整数数组 x = torch.arange(12) """ >>> x tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) >>> x.dtype torch.int64 """ #创建元素的均值为 0,标准差为 1,大小为(3*2)的张量 torch.normal(0, 1, size=(2,3)) """ tensor([[-1.2650, -1.4140, 0.9937], [-0.9774, -2.7983, -0.4092]]) """ #创建一个 n 阶单位阵 I = torch.eye(n) -
访问张量的形状
访问张量形状有两种,得到的结果不一样
>>> x.shape torch.Size([12]) #用张量表示的元素的形状 >>> x.numel() #直接得到一个标量(元素的个数) 12 -
直接对张量进行标准算术运算(
+、-、*、/和**)会使他们按照元素对应运算>>> x = torch.tensor([1,2,3,4.0,5]) >>> y = torch.tensor([2,2,2,2,2]) >>> x+y,x-y,x*y,x/y,x**y (tensor([3., 4., 5., 6., 7.]), tensor([-1., 0., 1., 2., 3.]), tensor([ 2., 4., 6., 8., 10.]), tensor([0.5000, 1.0000, 1.5000, 2.0000, 2.5000]), tensor([ 1., 4., 9., 16., 25.])) #指数运算 >>> torch.exp(x) tensor([ 2.7183, 7.3891, 20.0855, 54.5981, 148.4132]) -
torch 的广播机制
即使要操作的两个张量形状不同,维度相同,torch 可以使用广播机制(broadcasting mechanism),将两个张量进行扩展,执行按元素操作。>>> a = torch.arange(3).reshape(3,1) >>> a tensor([[0], [1], [2]]) >>> b = torch.arange(2).reshape(1,2) >>> b tensor([[0, 1]]) >>> a+b #运算之前会通过广播机制,先将 a 横向拓展为 3*2 的矩阵,再将 b 纵向拓展为 3*2 的矩阵 tensor([[0, 1], [1, 2], [2, 3]]) -
numpy 张量与 torch 张量的转换
将 numpy 数据类型与 tensor 数据类型转换
>>> X = torch.rand(3,2) >>> X tensor([[0.1695, 0.4360], [0.1282, 0.7799], [0.4844, 0.5546]]) >>> A = X.numpy() >>> type(A) <class 'numpy.ndarray'> >>> type(X) <class 'torch.Tensor'> -
元素个数为 1 的张量转换为 python 标量(必须是元素个数为一的张量才能转换)
>>> a = torch.tensor([3.5]) >>> a tensor([3.5000]) >>> a.item() #获取其中的标量元素 3.5 >>> float(a) #将张量中的元素转换为 python 的浮点数 3.5 >>> int(a) #将张量中的元素转换为 python 的整数 3
2. 张量操作
2.1 转置
-
data.t()只能对二维矩阵转置 -
data.T对更高维的张量转置,直接将指标的排列顺序反转z = torch.Tensor(3,4) z_T = z.t() #只能用于二维矩阵 z_T = z.T #可以用于更高维度 >>> A =torch.arange(6).reshape(1,2,3) >>> A tensor([[[0, 1, 2], [3, 4, 5]]]) >>> A.T tensor([[[0], [3]], [[1], [4]], [[2], [5]]]) >>> A.T.shape torch.Size([3, 2, 1]) >>> A.t() Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: t() expects a tensor with <= 2 dimensions, but self is 3D
2.2 sum 求和
-
可以使用
sum函数对张量中的元素求和,默认情况是将张量中的所有元素相加>>> x = torch.arange(24).reshape(2,3,4) >>> x tensor([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) >>> x.sum() tensor(276) -
可以添加
axis=n来指定对某个维度或多个维度求和>>> x.shape torch.Size([2, 3, 4]) >>> x.sum(axis=0).shape torch.Size([3, 4]) >>> x.sum(axis=1).shape torch.Size([2, 4]) >>> x.sum(axis=2).shape torch.Size([2, 3]) >>> x.sum(axis=[0,1]).shape torch.Size([4]) -
可以使用
keepdims=True来保证求和后的维度个数不变>>> x.shape torch.Size([2, 3, 4]) >>> x.sum(axis=0,keepdims=True) tensor([[[12., 14., 16., 18.], [20., 22., 24., 26.], [28., 30., 32., 34.]]]) >>> x.sum(axis=0,keepdims=True).shape torch.Size([1, 3, 4])
2.3 mean 求平均值
-
tensor.mean()用于求所有元素的平均值,也可以使用axis=n指定求哪个维度的均值 -
mean()函数只能对float类型的数据求均值,如果数据类型是Int会报错>>> x = torch.arange(24,dtype=torch.float32).reshape(2,3,4) >>> x.mean() tensor(11.5000) >>> x.sum() / x.numel() tensor(11.5000) >>> x.mean(axis=0) tensor([[ 6., 7., 8., 9.], [10., 11., 12., 13.], [14., 15., 16., 17.]]) >>> x.sum(axis=0) / x.shape[0] tensor([[ 6., 7., 8., 9.], [10., 11., 12., 13.], [14., 15., 16., 17.]])
2.4 范数
-
L 2 L_2 L2 范数是所有元素平方和的平方根,对于矩阵又称为 F 范数(Frobenius norm)。
∥ x ∥ 2 = ∑ i = 1 m ∑ j = 1 n x i j 2 \|x\|_2=\sqrt{\sum_{i=1}^{m}\sum_{j=1}^n x_{ij}^2} ∥x∥2=i=1∑mj=1∑nxij2
>>> x = torch.ones(3,4) >>> x.norm() tensor(3.4641) -
L 1 L_1 L1 范数,元素的绝对值之和
∥ x ∥ 1 = ∑ i = 1 n ∣ x i ∣ \|x\|_1=\sum_{i=1}^n|x_i| ∥x∥1=i=1∑n∣xi∣>>> v = torch.tensor([3.0,-4.0]) >>> v.abs().sum() tensor(7.)
2.5 最大最小值
-
语法:
data.max()与data.min() -
直接对一个张量使用
max()或min()是直接返回一个最大或最小值>>> a = torch.tensor([[1,2], [3,5], [6,4]]) >>> a tensor([[1, 2], [3, 5], [6, 4]]) >>> a.max() tensor(6) -
如果使用
axis=n指定对某个维度求最大最小值,会返回两个张量,分别表示 值 和 索引>>> a.max(axis=1) torch.return_types.max( values=tensor([2, 5, 6]), indices=tensor([1, 1, 0])) >>> values,index = a.max(axis=0) >>> values tensor([6, 5]) >>> index tensor([2, 1])
2.6 张量展开
torch.flatten() 可以将张量展开为一个一维向量,
语法:
torch.flatten(input, start_dim=0, end_dim=- 1) →Tensor
参数:
-
input:表示一个输入张量 -
start_dim:表示从那个指标开始展开,默认为 0 0 0 -
end_dim:表示从哪个指标结束(包含该指标),默认为 − 1 -1 −1 -
示例:
>>> a = torch.randn(2,3,4,5) >>> a.flatten(1,2).shape torch.Size([2, 12, 5]) >>> a.flatten().shape torch.Size([120])
2.7 求张量中元素的累加和
-
data.cumsum(axis=n)将某个维度的数据依次累加到该维度的下一个元素>>> x tensor([[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]], [[12., 13., 14., 15.], [16., 17., 18., 19.], [20., 21., 22., 23.]]]) >>> x.cumsum(axis=0) tensor([[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]], [[12., 14., 16., 18.], [20., 22., 24., 26.], [28., 30., 32., 34.]]]) >>> x.cumsum(axis=1) tensor([[[ 0., 1., 2., 3.], [ 4., 6., 8., 10.], [12., 15., 18., 21.]], [[12., 13., 14., 15.], [28., 30., 32., 34.], [48., 51., 54., 57.]]])
2.8 零碎知识
-
一些零碎知识
x=torch.rand(3,3) print(x) print(x.trace()) #求矩阵的迹(对角线元素之和); print(x.diag()) #对角线元素之和; print(x.inverse()) #求矩阵的逆; print(x.triu()) #求矩阵的上三角 print(x.tril()) #求矩阵的下三角 x.normal_(0,1) #用均值为 0 ,方差为 1 的正态分布填充 x x.fill_(0) #用 0 填充 x
3. 张量乘法
3.1 点积(Hadamard product)
-
矩阵对应位置元素相乘
x.mul(y) -
a*a等价于a.mul(a)>>> a = torch.Tensor([[1,2], [3,4], [5, 6]]) >>> a tensor([[1., 2.], [3., 4.], [5., 6.]]) >>> a.mul(a) tensor([[ 1., 4.], [ 9., 16.], [25., 36.]])
3.2 内积
-
张量内积计算:
torch.dot(input, tensor) → Tensor- 示例代码
#计算两个张量的点积(内积) #官方提示:不能进行广播(broadcast). #example >>> torch.dot(torch.tensor([2, 3]), torch.tensor([2, 1])) #即对应位置相乘再相加 tensor(7) >>> torch.dot(torch.rand(2, 3), torch.rand(2, 2)) #报错,只允许一维的tensor RuntimeError: 1D tensors expected, got 2D, 2D tensors at /Users/distiller/project/conda/conda-bld/pytorch_1570710797334/work/aten/src/TH/generic/THTensorEvenMoreMath.cpp:774
- 示例代码
3.3 矩阵乘法
-
对矩阵imput和mat2执行矩阵乘法,该函数只能用于二维矩阵,三维的用下面的
matmul方法 -
语法:
torch.mm(input, mat2, out=None) → Tensor-
示例代码:
#如果input为(n x m)张量,则mat2为(m x p)张量,out将为(n x p)张量。 #官方提示此功能不广播。有关广播的矩阵乘法,请参见torch.matmul()。 >>> mat1 = torch.randn(2, 3) >>> mat2 = torch.randn(3, 3) >>> torch.mm(mat1, mat2) tensor([[ 0.4851, 0.5037, -0.3633], [-0.0760, -3.6705, 2.4784]])
-
3.4 张量乘法
-
语法:
torch.matmul(input, other, out=None) → Tensor
matmul等价于@ -
作用:两个张量的矩阵乘积。行为取决于张量的维数
-
如果两个张量都是一维的,则返回点积(标量)。
>>> # vector x vector >>> tensor1 = torch.randn(3) >>> tensor2 = torch.randn(3) >>> torch.matmul(tensor1, tensor2).size() torch.Size([]) -
如果两个参数都是二维的,则返回矩阵矩阵乘积。
# matrix x matrix >>> tensor1 = torch.randn(3, 4) >>> tensor2 = torch.randn(4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([3, 5]) -
如果第一个参数是一维的,而第二个参数是二维的,则为了矩阵乘法,会将1附加到其维数上。矩阵相乘后,将删除前置尺寸。
# 也就是让tensor2变成矩阵表示,1x3的矩阵和 3x4的矩阵,得到1x4的矩阵,然后删除1 >>> tensor1 = torch.randn(3, 4) >>> tensor2 = torch.randn(3) >>> torch.matmul(tensor2, tensor1).size() torch.Size([4]) -
如果第一个参数为二维,第二个参数为一维,则返回矩阵向量乘积。
# matrix x vector >>> tensor1 = torch.randn(3, 4) >>> tensor2 = torch.randn(4) >>> torch.matmul(tensor1, tensor2).size() torch.Size([3]) -
如果两个自变量至少为一维且至少一个自变量为N维(其中N> 2),则返回批处理矩阵乘法。
如果第一个参数是一维的,则在其维数之前添加一个1,以实现批量矩阵乘法并在其后删除。
如果第二个参数为一维,则将1附加到其维上,以实现成批矩阵倍数的目的,然后将其删除。
非矩阵(即批量)维度可以被广播(因此必须是可广播的)。例如,如果input为(jx1xnxm)张量,而other为(k×m×p)张量,out将是(j×k×n×p)张量。
>>> # batched matrix x broadcasted vector >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(4) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3]) >>> # batched matrix x batched matrix >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(10, 4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3, 5]) >>> # batched matrix x broadcasted matrix >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3, 5]) >>> tensor1 = torch.randn(10, 1, 3, 4) >>> tensor2 = torch.randn(2, 4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 2, 3, 5])
-
3.5 张量batch乘
张量 batch 乘就是对两个有相同大小 batch 的张量进行对应 batch 数据做乘积。
例如,张量 A 的形状为 [batch, height, width],张量 B 的形状为 [batch, height, width],我们想让它们对应的每个 batch 的 [height, width] 的矩阵做乘积,最后得到的是 batch 个 [height, width] 大小的矩阵两两相乘的结果。
- 示例代码如下:
>>> a=torch.rand(5,3,2) >>> b=torch.rand(5,2,3) >>> torch.einsum('bij,bji->b',a,b) tensor([2.0327, 0.6258, 1.4623, 0.6551, 1.6816]) >>> a tensor([[[0.2463, 0.4737], [0.6248, 0.3841], [0.9809, 0.6284]], [[0.4308, 0.2188], [0.1121, 0.0209], [0.3629, 0.0893]], [[0.3693, 0.7287], [0.4086, 0.1789], [0.1679, 0.3063]], [[0.8614, 0.2264], [0.1131, 0.4535], [0.7545, 0.0574]], [[0.9756, 0.5463], [0.4079, 0.1271], [0.4914, 0.0575]]]) >>> b tensor([[[0.9616, 0.2745, 0.8268], [0.5759, 0.3459, 0.6489]], [[0.6994, 0.3909, 0.5034], [0.2597, 0.5873, 0.3227]], [[0.5666, 0.9847, 0.8853], [0.5757, 0.6087, 0.5670]], [[0.2269, 0.0435, 0.2065], [0.4790, 0.3584, 0.4860]], [[0.9175, 0.3628, 0.3164], [0.8249, 0.0955, 0.3504]]])
3.6 外积
计算两个向量的外积。可以使用 torch.einsum 实现相同的效果。官方文档。
语法:
torch.outer(input, vec2, *, out=None) → Tensor
-
输入的两个参数必须都是一维的向量
-
示例:
>>> a = torch.arange(5) >>> a tensor([0, 1, 2, 3, 4]) >>> b = torch.arange(4) >>> b tensor([0, 1, 2, 3]) >>> a.outer(b) tensor([[ 0, 0, 0, 0], [ 0, 1, 2, 3], [ 0, 2, 4, 6], [ 0, 3, 6, 9], [ 0, 4, 8, 12]]) >>> torch.einsum('a,b->ab',a,b) tensor([[ 0, 0, 0, 0], [ 0, 1, 2, 3], [ 0, 2, 4, 6], [ 0, 3, 6, 9], [ 0, 4, 8, 12]])
4. torch.diag() 构建对角矩阵
语法:
torch.diag(input, diagonal=0, out=None) → Tensor
参数:
-
input(Tensor):输入张量如果输入是一个向量(1D 张量),则返回一个以
input为对角线元素的 2D 方阵如果输入是一个矩阵(2D 张量),则返回一个包含
input对角线元素的 1D 张量 -
diagonal (int, optional):指定对角线:- diagonal = 0, 主对角线
- diagonal > 0, 主对角线之上
- diagonal < 0, 主对角线之下
-
out (Tensor, optional):输出张量 -
参考代码:
-
构建对角矩阵
>>> a = torch.randn(3) >>> a 1.0480 -2.3405 -1.1138 [torch.FloatTensor of size 3] >>> torch.diag(a) 1.0480 0.0000 0.0000 0.0000 -2.3405 0.0000 0.0000 0.0000 -1.1138 [torch.FloatTensor of size 3x3] >>> torch.diag(a, 1) 0.0000 1.0480 0.0000 0.0000 0.0000 0.0000 -2.3405 0.0000 0.0000 0.0000 0.0000 -1.1138 0.0000 0.0000 0.0000 0.0000 [torch.FloatTensor of size 4x4] -
取得给定矩阵第k个对角线:
>>> a = torch.randn(3, 3) >>> a -1.5328 -1.3210 -1.5204 0.8596 0.0471 -0.2239 -0.6617 0.0146 -1.0817 [torch.FloatTensor of size 3x3] >>> torch.diag(a, 0) -1.5328 0.0471 -1.0817 [torch.FloatTensor of size 3] >>> torch.diag(a, 1) -1.3210 -0.2239 [torch.FloatTensor of size 2]
-
5. torch.unfold() 操作
语法:
Tensor.unfold(dim, size, step)->Tensor
参数:
-
dim:指定的维度和创建张量时指定的位置对应,为torch.rand((dim1, dim2, dim3,...))将张量按照
dim的维度,每size大小个元素,步长为step(每次沿dim维度跳step
步,跳过的元素被省略)提取出来元素,组成一个新的张量,三阶张量的每个维度的dim为:
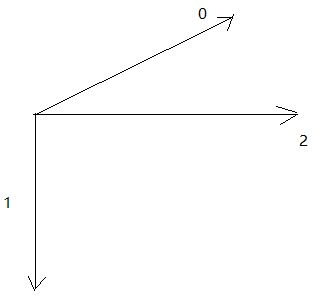
-
示例代码:
>>> b=torch.rand((3,3,3)) >>> b tensor([[[0.8566, 0.7805, 0.8685], [0.0748, 0.8633, 0.2942], [0.0910, 0.1034, 0.7245]], [[0.2095, 0.3515, 0.7939], [0.8285, 0.8342, 0.1363], [0.5275, 0.4655, 0.6437]], [[0.7672, 0.6340, 0.3335], [0.2305, 0.4823, 0.0460], [0.8322, 0.6568, 0.9940]]]) >>> b.unfold(0,3,1) tensor([[[[0.8566, 0.2095, 0.7672], [0.7805, 0.3515, 0.6340], [0.8685, 0.7939, 0.3335]], [[0.0748, 0.8285, 0.2305], [0.8633, 0.8342, 0.4823], [0.2942, 0.1363, 0.0460]], [[0.0910, 0.5275, 0.8322], [0.1034, 0.4655, 0.6568], [0.7245, 0.6437, 0.9940]]]]) >>> b.unfold(1,3,1) tensor([[[[0.8566, 0.0748, 0.0910], [0.7805, 0.8633, 0.1034], [0.8685, 0.2942, 0.7245]]], [[[0.2095, 0.8285, 0.5275], [0.3515, 0.8342, 0.4655], [0.7939, 0.1363, 0.6437]]], [[[0.7672, 0.2305, 0.8322], [0.6340, 0.4823, 0.6568], [0.3335, 0.0460, 0.9940]]]]) >>> b.unfold(2,3,1) tensor([[[[0.8566, 0.7805, 0.8685]], [[0.0748, 0.8633, 0.2942]], [[0.0910, 0.1034, 0.7245]]], [[[0.2095, 0.3515, 0.7939]], [[0.8285, 0.8342, 0.1363]], [[0.5275, 0.4655, 0.6437]]], [[[0.7672, 0.6340, 0.3335]], [[0.2305, 0.4823, 0.0460]], [[0.8322, 0.6568, 0.9940]]]])
6. 拼接函数 stack() 与 cat()
两者主要不同是是否需要两个张量的形状完全相同
1. stack()
官方解释:沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为 相同形状。
浅显说法:把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在 新增加的维度进行堆叠。实现了对张量的扩维。
语法:
outputs = torch.stack(inputs, dim=0) → Tensor
参数:
-
inputs:待连接的 张量序列,即一个保存有张量的列表或元组,且其中每个张量元素大小要相同
注:python的序列数据只有list和tuple。 -
dim:新的维度, 必须在0到len(outputs)之间。
注:len(outputs)是生成数据(新张量)的维度大小,也就是outputs的维度值。 -
示例代码:
# 假设是时间步T1 T1 = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 假设是时间步T2 T2 = torch.tensor([[10, 20, 30], [40, 50, 60], [70, 80, 90]]) print(torch.stack((T1,T2),dim=0).shape) print(torch.stack((T1,T2),dim=1).shape) print(torch.stack((T1,T2),dim=2).shape) print(torch.stack((T1,T2),dim=3).shape) # outputs: torch.Size([2, 3, 3]) torch.Size([3, 2, 3]) torch.Size([3, 3, 2]) '选择的dim>len(outputs),所以报错' IndexError: Dimension out of range (expected to be in range of [-3, 2], but got 3)dim shape 0 [ 2, 3, 3] 1 [3, 2, 3] 2 [3, 3, 2]
可以通过 torch.stack() 将由 tensor 组成的数组转换为张量表示:
>>> b = []
>>> b.append(torch.randn(2,2,2))
>>> b.append(torch.randn(2,2,2))
>>> b.append(torch.randn(2,2,2))
>>> b.append(torch.randn(2,2,2))
>>> torch.stack(b,0).shape
torch.Size([4, 2, 2, 2])
>>> torch.stack(b,0)[0]
tensor([[[ 0.4826, 1.5565],
[-0.1126, 1.2936]],
[[ 0.0233, -0.4019],
[ 1.2311, -0.3746]]])
>>> b[0]
tensor([[[ 0.4826, 1.5565],
[-0.1126, 1.2936]],
[[ 0.0233, -0.4019],
[ 1.2311, -0.3746]]])
2. cat()
cat() 函数用于将某两个相同大小的张量沿某个维度拼接起来,并不增加张量的阶数,两个张量要连接的维度大小可以不相同,如
(
2
,
3
,
3
)
(2,3,3)
(2,3,3) 和
(
4
,
3
,
3
,
)
(4,3,3,)
(4,3,3,) 可以 cat() 得到
(
6
,
3
,
3
)
(6,3,3)
(6,3,3)。官方文档。
语法:
torch.cat(tensors, dim=0, *, out=None) → Tensor
-
示例:
>>> a= torch.arange(6).reshape(2,3) >>> b= torch.arange(6).reshape(2,3) >>> a tensor([[0, 1, 2], [3, 4, 5]]) >>> b tensor([[0, 1, 2], [3, 4, 5]]) >>> torch.cat([a,b],dim = 0) tensor([[0, 1, 2], [3, 4, 5], [0, 1, 2], [3, 4, 5]]) >>> torch.cat([a,b],dim = 0).shape torch.Size([4, 3])
7. view() 与 reshape()
1. view() 函数
view() 将一个张量重新排列为指定大小的张量,操作方式为将原张量中的数据按照行优先的顺序排列为一个一维数据,再依次构成需要大小的张量。
如下所示的两个张量 a 和 b,他们都包含六个元素,如果对他们进行 view() 操作,都会首先变成 [1,2,3,4,5,6] 再从中依次抽取元素,即如果执行相同的 view() 操作,将得到相同的结果。
-
示例代码
>>> a = torch.Tensor([[1,2,3],[4,5,6]]) >>> b = torch.Tensor([1,2,3,4,5,6]) >>> a.view(3,2) tensor([[1., 2.], [3., 4.], [5., 6.]]) >>> b.view(3,2) tensor([[1., 2.], [3., 4.], [5., 6.]])
注意:view() 要求操作张量的地址是连续存储的,如果对张量进行了某些操作导致地址不连续,需要使用 contiguous() 函数将张量转变为内存连续的张量块,可以使用 a.is_contiguous() 来判断张量 a 是否为连续存储的形式。
view() 只改变张量的 shape ,数据还是原来的数据。
2. reshape() 函数
reshape() 在工作时候,如果张量是连续内存,则返回的数据是原数据,只是呈现的形状改变了,这时的方式和 view() 相同;如果张量内存不是连续的,则会将原数据进行一个拷贝,将复制后的数据进行变形。
所以 reshape() 和 view() 最大的区别就是可能会进行数据的拷贝,并且不要求数据的保存是连续的。
8. permute() 与 transpose()
两个函数的主要区别为,permute() 可以同时变换多个维度,但是 transpose() 只能同时交换两个维度。
1. permute() 函数
对张量的各个维度重新排列,官方文档。
-
示例:
>>> x = torch.rand(2,3,4) >>> x.permute(2,1,0).shape torch.Size([4, 3, 2])
2. transpose() 函数
该函数可以作用于一个张量,并指定张量的两个维度互换,官方文档。只能将指定的两个维度互换。
-
示例:
>>> x = torch.rand(2,3,4) >>> x.transpose(1,2).shape torch.Size([2, 4, 3])
9. squeeze() 和 unsqueeze()
-
squeeze()函数 主要是将一个高阶张量中维度为 1 的阶删除,默认删除所有为 1 的阶,可以指定删除某个阶,如下所示:>>> a = torch.randn(1,2,1,2) >>> a.squeeze().shape torch.Size([2, 2]) >>> a.squeeze(0).shape torch.Size([2, 1, 2]) -
unsqueeze()函数 为张量的某个阶增加一个为 1 的维数。>>> a = torch.randn(1,2,1,2) >>> a.unsqueeze(0).shape torch.Size([1, 1, 2, 1, 2])
二、数据集相关
torch.utils.data:包含一些批量处理数据的模块,主要包含 torch.utils.data.Dataset 和 torch.utils.data.DataLoader。
trochvision :torch 对计算机视觉中一些模型实现的库,包含对图片转换的模块 transforms 、加载数据集的模块 datasets 等。
2.1 torch.utils.data.Dataset
torch.utils.data.Dataset 主要用于将数据集包装起来,从而可以使用该类的对象直接访问数据集中的每个数据及其标签,方便后面的处理。可以将 Dataset 类的对象传入 DataLoader 中,从而使用 DataLoader 提供更加方便的访问方式。
该类主的功能是用来 获取每个样本、 获取数据集的大小 等。
若当前存在一些数据集以如下的方式组织:
____data
|____train
| |____ants
| |____bees
|
|____test
|____ants
|____bees
这里构建一个 Dataset 类来加载以上数据集, Dataset 本身是一个抽象类,实现时所有的子类可以重写一下方法:
__getitem__(self, index):该方法用于对象使用a[index]返回index索引的样本(必须重写)__len__(self):用于使用len(a)返回数据集的长度
-
示例代码
from torch.utils.data import Dataset from PIL import Image #利用 Image 读取指定路径的图片 import os class MyData(Dataset): def __init__(self, image_dir): self.image_dir = image_dir self.image_list = os.listdir(self.image_dir) def __getitem__(self, index): image_name = self.image_list[index] image_item_path = os.path.join(self.image_dir, image_name) image = Image.open(image_item_path) label = os.path.split(self.image_dir)[-1] return image, label def __len__(self): return len(self.image_list) ants_train = MyData('data\\train\\ants') #四张图片 bees_train = MyData('data\\train\\bees') #三张图片 train_dataset = ants_train + bees_train #将两个数据集进行拼接 for i in range(len(train_dataset)): print(train_dataset[i]) """ (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x27479F13070>, 'ants') (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=440x409 at 0x27479F134C0>, 'ants') (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=646x585 at 0x27479F134C0>, 'ants') (<PIL.WebPImagePlugin.WebPImageFile image mode=RGB size=500x500 at 0x27479F134C0>, 'ants') (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=675x690 at 0x27479F134C0>, 'bees') (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x606 at 0x27479F134C0>, 'bees') (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=690x606 at 0x27479F134C0>, 'bees') """
2.2 torch.utils.data.DataLoader
torch.utils.data.DataLoader 主要用来对包装好的 Dataset 数据集进行分块打包和处理,为模型提供不同的数据形式,如:分批访问数据,每批的大小等。
DataLoader 要求 Dataset 中的 图片格式为 Tensor 等类型,而且 图片大小要一样(要组成更高阶的张量)。
语法:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler, num_workers=0, drop_last=False)
参数:
-
dataset:一个Dataset类型的数据集 -
batch_size:指定获取数据集时每批的大小 -
shuffle:每次使用完一轮数据,是否将数据重新打乱,默认False -
sampler:使用某种策略在每一轮数据开始前打乱数据,不能和shuffle同时存在 -
num_workers:是否使用多进程加载数据集(不为 0 时在 Windows 下可能有问题) -
drop_last:如果数据集的总个数不能整除batch_size,是否选择丢弃最后一组数量不够batch_size的数据,默认False -
示例:
from torch.utils.data import Dataset from torch.utils.data import DataLoader from torchvision import transforms from PIL import Image #利用 Image 读取指定路径的图片 import os class MyData(Dataset): trans = transforms.Compose([ transforms.ToTensor(), transforms.Resize([100,100]) #dataloader 要求所有图片大小应该一样,所以对图片进行 resize ]) def __init__(self, image_dir): self.image_dir = image_dir self.image_list = os.listdir(self.image_dir) def __getitem__(self, index): image_name = self.image_list[index] image_item_path = os.path.join(self.image_dir, image_name) image = Image.open(image_item_path) trans_image = self.trans(image) #使用类变量对 PIL 图片进行转换 label = os.path.split(self.image_dir)[-1] return trans_image, label def __len__(self): return len(self.image_list) print("dataset:") ants_train_dataset = MyData('data\\train\\ants') for i in range(len(ants_train_dataset)): print(i, ants_train_dataset[i][0].shape,ants_train_dataset[i][1]) print("dataloader:") ants_train_dataloader = DataLoader(ants_train_dataset, batch_size = 3, shuffle = True) #使用 dataset 创建 dataloader for data in ants_train_dataloader: print(data[0].shape, data[1]) """ dataset: 0 torch.Size([3, 100, 100]) ants 1 torch.Size([3, 100, 100]) ants 2 torch.Size([3, 100, 100]) ants 3 torch.Size([3, 100, 100]) ants dataloader: torch.Size([3, 3, 100, 100]) ('ants', 'ants', 'ants') torch.Size([1, 3, 100, 100]) ('ants',) """
2.3 torchvision.transforms
使用 from torchvision import transforms 导入 transforms 工具,该工具实际对应于一个 transforms.py 文件,文件中包含很多对数据处理的类。
基本使用方式是:
- 构建一个对应的工具类对象
- 然后将该工具作用到图片上
例子:
-
ToTensor类将数据转换为
Tensor类型Tensor类型的数据可以通过指定requires_grad等参数实现反向传播、计算梯度等操作。
ToTensor只能作用于PIL Image或numpy.ndarray类型的数据from torchvision import transforms from PIL import Image img_path = "data\\train\\ants\\u=2045429628,2465157101&fm=26&fmt=auto&gp=0.jpg" img = Image.open(img_path) #读取图片 tensor_trans = transforms.ToTensor() #创建具体的工具 tensor_img = tensor_trans(img) #将工具作用到具体数据上 print(type(img)) print(type(tensor_img)) """ <class 'PIL.WebPImagePlugin.WebPImageFile'> <class 'torch.Tensor'> """ -
Normalize类对
Tensor类型的数据进行 均值归一化。语法:
transfroms.Normalize(mean, std)参数:
-
mean:一个列表,保存每个 channel 的 均值 -
std:一个列表,保存每个 channel 的 标准差 -
计算方法:
o u t p u t [ c h a n n e l ] = i n p u t [ c h a n n e l ] − m e a n [ c h a n n e l ] s t d [ c h a n n e l ] \mathrm{output}[channel] = \frac{\mathrm{input}[channel] - \mathrm{mean}[channel]}{\mathrm{std}[channel]} output[channel]=std[channel]input[channel]−mean[channel] -
示例:
print("before norm: ", tensor_img.max(),tensor_img.min()) norm_trans = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #通过全部为 0.5 将 [0,1] 之间的数归一化到 [-1,1] 之间 tensor_img = norm_trans(tensor_img) print("after norm: ",tensor_img.max(),tensor_img.min()) """ before norm: tensor(1.) tensor(0.) after norm: tensor(1.) tensor(-1.) """
-
-
Resize类对
PIL或Tensor类型的图片进行缩放。转变过程不改变数据类型。语法:
transforms.Resize(size)参数:
-
size:可以是一个序列(列表或元组等)或整数。如果是一个序列,需要有两个值,两个值的大小分别对应于要转换的张量的后两个维度,如
(height, width),会将图片对应的最后两个维度缩放到(height, width),其他维度不变。如果是一个整数,会将最小的边缩放到该整数,其他的边按比例缩放。
-
示例:
print(tensor_img.shape) resize_trans = transforms.Resize([20,30]) tensor_img = resize_trans(tensor_img) print(tensor_img.shape) """ torch.Size([3, 500, 500]) torch.Size([3, 20, 30]) """
-
-
Compose类将多种不同类型的操作组合,接受一个由多种
transforms组成的列表,对图片的转换会按照列表中的transforms的前后顺序依次执行。语法:
transforms.Compose(transforms)参数:
-
transforms:由多个transform组成的列表 -
示例:
print(type(img),img.size) trans = transforms.Compose([transforms.ToTensor(), transforms.Resize([20,30])]) trans_img = trans(img) print(type(trans_img),trans_img.shape) """ <class 'PIL.WebPImagePlugin.WebPImageFile'> (500, 500) <class 'torch.Tensor'> torch.Size([3, 20, 30]) """
-
2.4 torchvision.datasets
该模块中包含很多已有的数据集类,通过使用这些类就可以直接得到 这些数据集。
所有的数据集都是 torch.utils.data.Dataset 的子类,可以使用 torch.utils.data.Dataset 中的方法。
语法:
torchvision.datasets.XXXX(root, train, transform, download)
参数:
-
root:字符串,指定数据集所在的位置或要保存的位置 -
train:布尔值,如果为True加载训练集;如果为False加载测试集 -
transform:为数据集中的图片指定某种torchvision.transforms处理方式 -
download:布尔值,如果为True当指定的目录中没有数据集时,自动下载 -
示例:
加载
CIFAR10数据集:import torchvision dataset_transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ]) train_set = torchvision.datasets.CIFAR10(root = './dataset', train=True, transform = dataset_transform, download = True) test_set = torchvision.datasets.CIFAR10(root = './dataset', train=False, transform = dataset_transform, download = True) print(len(train_set)) print(train_set[0]) #包含图片和对应的标签 (data,target)
三、常用方法
3.1 特征值分解
torch 推荐使用新的 torch.linalg.eig() 进行特征值分解,对于一个矩阵
A
∈
K
n
×
n
A\in \mathbb{K}^{n\times n}
A∈Kn×n ,通过特征值分解,得到如下三个矩阵:
A
=
V
diag
(
Λ
)
V
−
1
,
V
∈
K
n
×
n
,
Λ
∈
K
n
A = V\text{diag}(\Lambda)V^{-1}, \quad{} V\in \mathbb{K}^{n\times n},\Lambda \in \mathbb{K}^n
A=Vdiag(Λ)V−1,V∈Kn×n,Λ∈Kn
语法:
torch.linalg.eig(A, *, out=None) -> (Tensor, Tensor)
参数:
-
A:要分解的张量,其维度可以为 ( ∗ , n , n ) (*,n,n) (∗,n,n), ∗ * ∗ 表示可以是多个维度,即任意 batch 个矩阵同时计算,只将最后两个维度作为矩阵的大小 -
返回值: S , V S,V S,V
S S S 是特征值组成的向量
V V V 是特征向量组成矩阵
-
示例:
>>> a = torch.rand(3,3) >>> s,v = torch.linalg.eig(a) >>> s tensor([ 1.2507+0.j, -0.2781+0.j, 0.3008+0.j]) >>> v tensor([[ 0.7796+0.j, 0.8615+0.j, -0.5196+0.j], [ 0.5494+0.j, -0.4707+0.j, -0.3552+0.j], [ 0.3006+0.j, -0.1903+0.j, 0.7770+0.j]]) >>> a - v.matmul(torch.diag(s)).matmul(v.inverse()) tensor([[4.4703e-07+0.j, 4.1723e-07+0.j, 3.2783e-07+0.j], [2.3842e-07+0.j, 5.9605e-08+0.j, 8.9407e-08+0.j], [1.1921e-07+0.j, 6.7055e-08+0.j, 1.1921e-07+0.j]])
3.2 SVD 分解
torch 有两个 SVD 分解的函数,旧版本的使用 torch.svd(),在 PyTorch 1.9 推荐使用 torch.linalg.svd()。
对矩阵
A
∈
R
m
×
n
A\in \mathbb{R}^{m\times n}
A∈Rm×n 进行 SVD 分解得到如下的结果:
A
=
U
d
i
a
g
(
S
)
V
H
,
U
∈
R
m
×
m
,
S
∈
R
k
,
V
∈
R
n
×
n
,
k
=
min
(
m
,
n
)
A = U diag(S)V^H,\quad U\in\mathbb{R}^{m\times m},S\in\mathbb{R}^k,V\in\mathbb{R}^{n\times n},k=\min(m,n)
A=Udiag(S)VH,U∈Rm×m,S∈Rk,V∈Rn×n,k=min(m,n)
其中 U U U 和 V V V 的列是正交的。
语法:
torch.linalg.svd(A, full_matrices=True, *, out=None) -> (Tensor, Tensor, Tensor)
参数:
-
A:要分解的张量,其维度可以为 ( ∗ , m , n ) (*,m,n) (∗,m,n), ∗ * ∗ 表示可以是多个维度,即任意 batch 个矩阵同时计算,只将最后两个维度作为矩阵的大小 -
out:可以指定输出的三个矩阵 U , S , V H U,S,V^H U,S,VH,未指定时候直接返回。 -
full_matrices:bool 值,默认为True。当为
True时,得到的 U ∈ R m × m , S ∈ R k , V ∈ R n × n , k = min ( m , n ) U\in\mathbb{R}^{m\times m},S\in\mathbb{R}^k,V\in\mathbb{R}^{n\times n},k=\min(m,n) U∈Rm×m,S∈Rk,V∈Rn×n,k=min(m,n)。当为
False时,得到的 U ∈ R m × k , S ∈ R k , V ∈ R k × n , k = min ( m , n ) U\in\mathbb{R}^{m\times k},S\in\mathbb{R}^k,V\in\mathbb{R}^{k\times n},k=\min(m,n) U∈Rm×k,S∈Rk,V∈Rk×n,k=min(m,n)。 -
示例代码:
>>> a = torch.randn(5,3) >>> a tensor([[-0.7547, -0.3140, -1.1802], [ 0.8683, 0.9751, 0.4206], [ 0.8068, -0.1887, 0.2596], [ 0.5064, 0.7987, 1.0570], [ 1.0838, -2.1291, 0.9031]]) >>> u, s, vh = torch.linalg.svd(a, full_matrices=False) >>> u.shape torch.Size([5, 3]) >>> s.shape torch.Size([3]) >>> vh.shape torch.Size([3, 3]) >>> a = torch.rand(2,2,5,5) >>> u,s,v = torch.linalg.svd(a) >>> u.shape torch.Size([2, 2, 5, 5])
3.3 QR 分解
qr() 函数将一个矩阵
A
∈
K
m
×
n
A\in\mathbb{K}^{m\times n}
A∈Km×n 分解为一个正交矩阵
Q
∈
K
m
×
m
Q\in \mathbb{K}^{m\times m}
Q∈Km×m 和一个上三角矩阵
R
∈
K
m
×
n
R\in \mathbb{K}^{m\times n}
R∈Km×n 的乘积:
A
=
Q
R
,
Q
∈
K
m
×
m
,
R
∈
K
m
×
n
A = QR,\quad Q\in \mathbb{K}^{m\times m},R\in \mathbb{K}^{m\times n}
A=QR,Q∈Km×m,R∈Km×n
但是当
m
>
n
m>n
m>n 时候,矩阵
R
R
R 的最后
m
−
n
m-n
m−n 行都是
0
0
0,所以可以对
Q
Q
Q 的列和
R
R
R 的行进行截断,得到截断的 QR 分解:
A
=
Q
R
,
A
∈
K
m
×
n
,
Q
∈
K
m
×
n
,
R
∈
K
n
×
n
A = QR,\quad A\in\mathbb{K}^{m\times n},Q\in \mathbb{K}^{m\times n},R\in \mathbb{K}^{n\times n}
A=QR,A∈Km×n,Q∈Km×n,R∈Kn×n
语法:
torch.linalg.qr(A, mode='reduced', *, out=None) -> (Tensor, Tensor)
参数:
-
A:要分解的张量,其维度可以为 ( ∗ , m , n ) (*,m,n) (∗,m,n), ∗ * ∗ 表示可以是多个维度,即任意 batch 个矩阵同时计算,只将最后两个维度作为矩阵的大小 -
mode:标识是否进行截断的 QR 分解,可选参数为:reduced(默认值),进行 截断 QR 分解,即 Q ∈ K m × k , R ∈ K k × n , k = min ( m , n ) Q\in \mathbb{K}^{m\times k},R\in \mathbb{K}^{k\times n},k=\min(m,n) Q∈Km×k,R∈Kk×n,k=min(m,n)complete,进行完整的 QR 分解,即 Q ∈ K m × m Q\in \mathbb{K}^{m\times m} Q∈Km×m , R ∈ K m × n R\in \mathbb{K}^{m\times n} R∈Km×nr,返回空的 Q ,和截断的 R , R ∈ K k × n R\in \mathbb{K}^{k\times n} R∈Kk×n -
返回值: ( Q , R ) (Q,R) (Q,R)
-
示例:
>>> a = torch.rand(3,2) >>> q,r = torch.linalg.qr(a) >>> q tensor([[-0.4868, 0.4528], [-0.8506, -0.4404], [-0.1989, 0.7753]]) >>> r tensor([[-0.9137, -1.1533], [ 0.0000, 0.6640]]) >>> q.shape,r.shape (torch.Size([3, 2]), torch.Size([2, 2])) >>> q,r = torch.linalg.qr(a,mode='complete') >>> q.shape,r.shape (torch.Size([3, 3]), torch.Size([3, 2])) >>> q,r = torch.linalg.qr(a,mode='r') >>> q.shape,r.shape (torch.Size([0]), torch.Size([2, 2]))
四、深度学习
4.1 深度学习的组件
torch.nn 包含很多构建神经网络的工具,nn 是神经网络 neural network 的缩写。这个包含很多不同的模块,这些模块分为不同的类别:
Containers:其中包含一些神经网络的基本结构(骨架),可以向这些结构中加入一些内容构成具体的网络
除了骨架,torch.nn 还有一些具体的 组件,我们可以将这些组件添加到 Containers 中构成更加丰富的神经网络,这些组件也分为不同的类别:
torch.nn 和 torch.functional 两个模块中包含很多相似的函数,但是它们的使用方法不同,一般使用 torch.nn 构建网络,这里可以查看torch.nn 和 torch.functional 的区别。
下面展示说明了一些常见的模块。
-
神经网络的结构类
Containers类别中包含的torch.nn的子模块一般都是与网络的构建相关,主要包含以下一些常用的模块。-
Containers类别中包含很多torch.nn的子模块,其中最重要的就是Module模块Module类是所有神经网络的基类(包含神经网络的基本结构),所有的神经网络都要继承这个类继承该类的模型需要重写函数
forward,该函数可以使用神经网络中的组件依次处理输入的数据。Module的实例可以通过model.add_module('module name', nn.xxx)为已有模型新加组件(若模型中已有module name组件,会将原组件替换为新组件),还可以通过model.module_name = nn.xxx修改已有组件。import torch import torch.nn as nn class Model(nn.Module): def __init__(self): super().__init__() self.conv = nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3) self.seq_layer = nn.Sequential( nn.Conv2d(in_channels = 6, out_channels = 6, kernel_size = 3), nn.MaxPool2d(kernel_size = 3) ) self.linear = nn.Linear(100, 10) def forward(self,x): x = x+1 return x model = Model() x = 2 print(model(x)) """ 3 """ #添加某个组件 print("添加组件:") print("原模型:\n",model) model.add_module('linear2', nn.Linear(200, 20)) #添加组件 model.seq_layer.add_module('seq_linear', nn.Linear(100, 10)) #为 seq_layer 添加组件 print("新模型:\n",model) """ 添加组件: 原模型: Model( (conv): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)) (seq_layer): Sequential( (0): Conv2d(6, 6, kernel_size=(3, 3), stride=(1, 1)) (1): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False) ) (linear): Linear(in_features=100, out_features=10, bias=True) ) 新模型: Model( (conv): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)) (seq_layer): Sequential( (0): Conv2d(6, 6, kernel_size=(3, 3), stride=(1, 1)) (1): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False) (seq_linear): Linear(in_features=100, out_features=10, bias=True) ) (linear): Linear(in_features=100, out_features=10, bias=True) (linear2): Linear(in_features=200, out_features=20, bias=True) ) """ #修改某个组件 print("修改组件:") print("原组件:\n",model) model.conv = nn.Conv2d(in_channels = 3, out_channels = 8, kernel_size = 4) #修改指定组件 model.seq_layer[1] = nn.MaxPool2d(kernel_size = 5) print("新组件:\n",model) """ 修改组件: 原组件: Model( (conv): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)) (seq_layer): Sequential( (0): Conv2d(6, 6, kernel_size=(3, 3), stride=(1, 1)) (1): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False) (seq_linear): Linear(in_features=100, out_features=10, bias=True) ) (linear): Linear(in_features=100, out_features=10, bias=True) (linear2): Linear(in_features=200, out_features=20, bias=True) ) 新组件: Model( (conv): Conv2d(3, 8, kernel_size=(4, 4), stride=(1, 1)) (seq_layer): Sequential( (0): Conv2d(6, 6, kernel_size=(3, 3), stride=(1, 1)) (1): MaxPool2d(kernel_size=5, stride=5, padding=0, dilation=1, ceil_mode=False) (seq_linear): Linear(in_features=100, out_features=10, bias=True) ) (linear): Linear(in_features=100, out_features=10, bias=True) (linear2): Linear(in_features=200, out_features=20, bias=True) ) """ -
顺序存储一组神经网络的组件,当将输入数据传入时,会按照存储的顺序依次对数据处理。
语法:
torch.nn.Sequential(*args)参数:
-
*args:若干个神经网络组件 -
示例:
import torch from torch import nn class sequential_test(nn.Module): def __init__(self): super().__init__() self.seq_layer = nn.Sequential( nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3), nn.MaxPool2d(kernel_size = 3) ) def forward(self, input): output = self.seq_layer(input) return output data = torch.randn(1,3,15,15) model = sequential_test() output = model(data) print(output.shape) """ torch.Size([1, 6, 4, 4]) """
-
-
将多个神经网络组件构成一个列表,可以在
forward中根据需要选择列表中的某一个组件使用。import torch from torch import nn class MyModule(nn.Module): def __init__(self): super(MyModule, self).__init__() self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)]) def forward(self, x): # ModuleList can act as an iterable, or be indexed using ints for i, l in enumerate(self.linears): x = self.linears[i // 2](x) + l(x) return x data = torch.randn(1,10) model = MyModule() output = model(data) print(output.shape) """ torch.Size([1, 10]) """
-
-
卷积是神经网络中的基本操作,其具体过程如下:

在
torch.nn中可以使用Conv2d创建二维的卷积核对图片进行卷积操作。语法:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)参数:
-
in_channels:输入图片的通道个数,创建的每个 卷积核的通道数 等于 输入图片的通道数,每个卷积核的每个通道和输入图片的对应通道做卷积,得到一个输出通道 -
out_channels:输出结果的通道个数,卷积核的个数 等于 输出结果的通道数 -
kernel_size:卷积核的大小,可以是整数(核的高和宽相等)或元组(每个元素分别表示高和宽) -
stride:卷积核每次移动的步长,整数(高和宽的步长相同)或元组(分别指定高和宽的步长) -
padding:图片周围补充的像素个数,默认补充的值是 0 0 0 -
卷积操作 输入数据的形式 应该为 ( N , C i n , H i n , W i n ) (N,C_{in},H_{in},W_{in}) (N,Cin,Hin,Win),其中 N N N 表示输入图片的个数
-
卷积操作 输出数据的形式 为 ( N , C o u t , H o u t , W o u t ) (N,C_{out},H_{out},W_{out}) (N,Cout,Hout,Wout)
-
卷积输出尺寸的计算方式可以看:(反)卷积输出尺寸计算
-
示例:
import torch from torch import nn class Test(nn.Module): def __init__(self): super().__init__() self.conv2d = nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3, stride = 1) def forward(self, input): output = self.conv2d(input) return output test_nn = Test() data = torch.randn(64, 3, 28, 28) conv_data = test_nn(data) print(data.shape) print(conv_data.shape) """ torch.Size([64, 3, 28, 28]) torch.Size([64, 6, 26, 26]) """
-
-
保留特征的同时减少数据量,加速训练过程。其主要方法是从指定大小的卷积核所在的数据区域中得到某种特征值,如 最大池化 就是从卷积核对应的区域中取出最大值。
二维的最大池化是作用于二维图片的操作,其使用的函数为
torch.nn.MaxPool2d。语法:
torch.nn.MaxPool2d(kernel_size, stride, padding = 0, ceil_mode=False)参数:
-
kernel_size:池化时卷积核的大小,整数或元组 -
stride:卷积核每次移动的步长,默认步长等于卷积核的大小 -
padding:对图片周围补充的像素个数 -
ceil_mode:如果做池化操作时,最后剩余的像素个数小于卷积核的大小,是否继续做池化。默认为False,不继续做池化。 -
输入数据的形式 应该为 ( N , C , H i n , W i n ) (N,C,H_{in},W_{in}) (N,C,Hin,Win),其中 N N N 表示输入图片的个数
-
输出数据的形式 应该为 ( N , C , H o u t , W o u t ) (N,C,H_{out},W_{out}) (N,C,Hout,Wout),池化操作不改变通道数
-
示例:
import torch from torch import nn class MaxPool(nn.Module): def __init__(self): super().__init__() self.maxpool2d = nn.MaxPool2d(kernel_size = 3) #self.maxpool2d = nn.MaxPool2d(kernel_size = 3, ceil_mode = True) #如果加入 ceil_mode 参数 def forward(self, input): output = self.maxpool2d(input) return output data = torch.tensor([[1.,2,3,4], [2,3,5,3], [2,4,5,0], [1,0,3,2]]) data_tensor = data.reshape(1,1,4,4) model = MaxPool() output = model(data_tensor) print(output) """没有 ceil_mode 参数时候的输出 tensor([[[[5.]]]]) """ """ 有 ceil_mode 参数时候的输出 tensor([[[[5., 4.], [3., 2.]]]]) """
-
-
非线性激活为神经网络中引入非线性,ReLU 函数对输入输入进行如下操作。

对数据使用 ReLU 激活函数可以使用torch.nn.ReLU。语法:
torch.nn.ReLU(inplace = False)参数:
-
inplace:是否在原数据上进行操作,默认为False时,使用时是对数据操作后返回值;如果为True时,不返回值,直接修改原数据。 -
输入数据形式: ( N , ∗ ) (N,*) (N,∗)
-
输出数据形式: ( N , ∗ ) (N,*) (N,∗)
-
示例:
>>> import torch >>> from torch import nn >>> relu = nn.ReLU() >>> relu_inplace = nn.ReLU(inplace=True) >>> a=torch.randn(2,2) >>> b = torch.randn(2,2) >>> a tensor([[-0.2238, -0.2196], [-1.3359, -0.9723]]) >>> b tensor([[ 1.0123, 0.2991], [-0.5847, 1.5517]]) >>> relu(a) tensor([[0., 0.], [0., 0.]]) >>> a tensor([[-0.2238, -0.2196], [-1.3359, -0.9723]]) >>> relu_inplace(b) tensor([[1.0123, 0.2991], [0.0000, 1.5517]]) >>> b tensor([[1.0123, 0.2991], [0.0000, 1.5517]])
-
-
对输入采用正则化,加快训练速度。
torch.nn.BatchNorm2d用在二维图片中,对图片的 每个通道 进行正则化:
y = x − μ σ , μ 是 均 值 , σ 是 标 准 差 y = \frac{x - \mu}{\sigma}, \quad \mu 是均值, \sigma 是标准差 y=σx−μ,μ是均值,σ是标准差语法:
torch.nn.BatchNorm2d(num_features)参数:
-
num_features:该参数等于输入数据 ( N , C , H , W ) (N,C,H,W) (N,C,H,W) 的通道数 C C C -
输入数据形式: ( N , C , H , W ) (N,C,H,W) (N,C,H,W)
-
输出数据形式: ( N , C , H , W ) (N,C,H,W) (N,C,H,W),不改变数据大小
-
示例:
>>> m =nn.BatchNorm2d(2) >>> a = torch.arange(4,dtype = torch.float32).reshape(2,2) >>> b = torch.stack([a,a], dim = 0).reshape(1,2,2,2) >>> b tensor([[[0., 1.], [2., 3.]], [[0., 1.], [2., 3.]]]) >>> m(b) tensor([[[[-1.3416, -0.4472], [ 0.4472, 1.3416]], [[-1.3416, -0.4472], [ 0.4472, 1.3416]]]], grad_fn=<NativeBatchNormBackward>) >>> sigma = (a-a.mean()).norm()/math.sqrt(4) #求标准差 >>> y = (a - a.mean())/sigma #归一化 >>> y tensor([[-1.3416, -0.4472], [ 0.4472, 1.3416]])
-
-
线性层就是创建一个权重矩阵 W W W,使用
torch.nn.Linear(),对输入数据 x x x 进行如下操作:
y = x W + b y =xW+b y=xW+b语法:
torch.nn.Linear(in_featrues, out_features, bias = True)参数:
in_features:输入 x x x 的维度大小,输入数据的形式可以为 ( N , ∗ , H i n ) (N,*, H_{in}) (N,∗,Hin),in_features的大小等于 H i n H_{in} Hinout_features:输出 y y y 的维度大小,输出数据的形式为 ( N , ∗ , H o u t ) (N,*,H_{out}) (N,∗,Hout),out_features的大小等于 H o u t H_{out} Houtbias:是否加入偏置项,默认True为加入偏置,False为不加入偏置- 示例:
>>> m = nn.Linear(20,5) >>> data = torch.randn(100,20) >>> m(data).shape torch.Size([100, 5]) -
以概率 p p p 将输入数据中的元素置 0 0 0,从而减少过拟合的概率。
使用
torch.nn.Dropout2d()对二维图片的每个通道置 0 0 0。语法:
torch.nn.Dropout2d(p = 0.5, inplace = False)参数:
p:指定将某个值置 0 0 0 的概率,默认为 0.5 0.5 0.5inplace:是否在原数据中操作- 输入数据类型:对于二维数据,输入数据应该为 ( N , C , H , W ) (N,C,H,W) (N,C,H,W)
- 输出数据类型:输出数据为 ( N , C , H , W ) (N,C,H,W) (N,C,H,W),不改变大小
- 示例:
>>> m = nn.Dropout2d() >>> b.shape torch.Size([1, 2, 2, 2]) >>> b tensor([[[[0., 1.], [2., 3.]], [[0., 1.], [2., 3.]]]]) >>> m(b) tensor([[[[0., 2.], [4., 6.]], [[0., 2.], [4., 6.]]]]) -
将输入的数据展开为一维的向量,使用
nn.Flatten()模块。语法:
torch.nn.Flatten(start_dim=1, end_dim=-1)参数:
-
start_dim:表示从那个指标开始展开,默认为 1 1 1 -
end_dim:表示从哪个指标结束(包含该指标),默认为 − 1 -1 −1 -
输入格式: ( N , ∗ ) (N,*) (N,∗), N N N 表示图片的个数, ∗ * ∗ 表示若干个维度
-
输出格式: ( N , ∏ ∗ ) (N,\prod *) (N,∏∗),默认情况下会将后面所有指标累乘,得到一个新的维度
-
示例:
>>> model = nn.Flatten() >>> input = torch.rand(10,1,12,12) >>> model(input).shape torch.Size([10, 144])
-
4.2 损失函数
损失函数是用于衡量预测结果与真实值之间的差距的函数,该函数由输入数据、参数和真实结果组成,为了找到使预测结果与真实值最接近的参数,可以将损失函数作为凸函数,通过对其中的参数求导,并利用导数更新参数,找到使整体损失函数最小的参数。
torch.nn 模块中有一个 Loss Function 分类 中包含多种损失函数。
-
该损失函数衡量两个输入 x x x 与 y y y 之间的 平均绝对值误差(MAE),计算公式为:
l ( x , y ) = { 1 n ∑ i = 1 n ∣ x n − y n ∣ , reduction = ’mean’ ∑ i = 1 n ∣ x n − y n ∣ , reduction = ’sum’ l(x,y) = \begin{cases} \frac{1}{n}\sum\limits_{i=1}^{n} |x_n - y_n|,&\quad \text{reduction = 'mean'} \\ \sum\limits_{i=1}^{n} |x_n - y_n|,&\quad \text{reduction = 'sum'} \end{cases} l(x,y)=⎩⎪⎨⎪⎧n1i=1∑n∣xn−yn∣,i=1∑n∣xn−yn∣,reduction = ’mean’reduction = ’sum’语法:
torch.nn.L1Loss(reduction = 'mean')参数:
-
reduction:对所有元素进行绝对值误差计算后,怎样将其结合。可以取三个值:none表示什么都不做,得到的是和原 x x x 相同大小的张量;mean(默认值)表示计算完每个元素的绝对值误差后求所有结果的均值;sum表示将所有元素计算的结果累加。 -
输入形式:
( N , ∗ ) (N,*) (N,∗), N N N 表示样本个数, ∗ * ∗ 表示后面的任意维度,计算时会将 ∗ * ∗ 中所有位置对应的元素求绝对值误差。计算时需要两个相同大小的输入。
-
输出形式:
若
reduction = 'mean'或reduction = 'sum',输出一个标量。若
reduction = none输出大小和输入大小相同。 -
示例:
>>> loss = nn.L1Loss() >>> a = torch.tensor([1.,2,3,4]) >>> b = torch.tensor([2,3,4.,5]) >>> loss(a,b) tensor(1.)
-
-
计算均方差损失函数,计算公式为:
l ( x , y ) = { 1 n ∑ i = 1 n ( x n − y n ) 2 , reduction = ’mean’ ∑ i = 1 n ( x n − y n ) 2 , reduction = ’sum’ l(x,y) = \begin{cases} \frac{1}{n}\sum\limits_{i=1}^{n} (x_n - y_n)^2,&\quad \text{reduction = 'mean'} \\ \sum\limits_{i=1}^{n} (x_n - y_n)^2,&\quad \text{reduction = 'sum'} \end{cases} l(x,y)=⎩⎪⎨⎪⎧n1i=1∑n(xn−yn)2,i=1∑n(xn−yn)2,reduction = ’mean’reduction = ’sum’语法:
torch.nn.MSELoss(reduction = 'mean')参数:
-
reduction:对应元素相减再平方后,怎样将其结合。可以取三个值:none表示什么都不做,得到的是和原 x x x 相同大小的张量;mean(默认值)表示计算完每个元素的平方误差后求所有结果的均值;sum表示将所有元素计算的结果累加。 -
输入形式:
( N , ∗ ) (N,*) (N,∗), N N N 表示样本个数, ∗ * ∗ 表示后面的任意维度,计算时会将 ∗ * ∗ 中所有位置对应的元素求平方误差。计算时需要两个相同大小的输入。
-
输出形式:
若
reduction = 'mean'或reduction = 'sum',输出一个标量。若
reduction = none输出大小和输入大小相同。 -
示例:
>>> a = torch.tensor([1.,2,3,4]) >>> b = torch.tensor([2,3,4.,5]) >>> loss = nn.MSELoss() >>> loss(a,b) tensor(1.)
-
-
对于多分类问题,预测的结果向量为 x x x ,可以通过 Softmax 函数将 x x x 中的每个元素转换为对应预测类别的概率,如 x [ 1 ] x[1] x[1] 表示预测为第一类的概率, x [ 2 ] x[2] x[2] 表示预测为第二类的概率。根据交叉熵的定义,可以将做完 Softmax 的 x x x 再通过交叉熵计算和真实标签之间的差距,详细计算过程移步这里,因此我们可以将包含了 Softmax 函数 和 交叉熵 的损失函数表示如下:
loss = − log ( e x [ class ] ∑ j e x [ j ] ) , class 表示数据的真实类别 \text{loss} = -\log\left(\frac{e^{x[\text{class}]}}{\sum\limits_je^{x[j]}}\right),\quad \text{class 表示数据的真实类别} loss=−log⎝⎜⎛j∑ex[j]ex[class]⎠⎟⎞,class 表示数据的真实类别torch.nn.CrossEntropyLoss实现了上述过程。语法:
torch.nn.CrossEntropyLoss()参数:
-
输入格式:
预测结果的格式: ( N , C ) (N,C) (N,C),其中 N N N 表示样本个数, C C C 表示对 C C C 个分类的每个类别的预测结果。
真实标签的格式: ( N ) (N) (N),存储每个样本的真实标签。如 [ 0 , 1 , 0 , / c d o t s ] [0,1,0,/cdots] [0,1,0,/cdots] ,分别表示第一个样本为 0 0 0 类,第二个为 1 1 1 类 ⋯ \cdots ⋯。
-
输出格式: ( N ) (N) (N),表示 N N N 个样本的每个损失
-
示例:
>>> cross_entropy = nn.CrossEntropyLoss() #创建交叉熵 loss >>> output = torch.rand(1,3) #创建了只有一个样本的三分类预测结果 >>> output tensor([[0.5887, 0.3617, 0.5978]]) >>> target = torch.tensor([2]) #第一个样本的真实标签设置为 2 >>> cross_entropy(output,target) tensor(1.0227)
-
4.3 优化器
1. parameters() 获取模型的参数
在一般的深度学习模型中,定义模型时加入的组件就是其中要优化的参数,通过损失函数可以计算当前的参数组成模型的效果,我们可以根据损失反向调整模型中的参数,一个模型中的参数可以通过 model.parameters() 函数获得,如下所示,模型的参数是一个生成器,可以通过遍历获取每个元素。
import torch
from torch import nn
class sequential_test(nn.Module):
def __init__(self):
super().__init__()
self.seq_layer = nn.Sequential(
nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3),
nn.MaxPool2d(kernel_size = 3)
)
def forward(self, input):
output = self.seq_layer(input)
return output
data = torch.randn(1,3,15,15)
model = sequential_test()
parameters = model.parameters() #获取模型中的参数
print(parameters)
"""
<generator object Module.parameters at 0x000001CC1BA6D580>
"""
注意,获取参数使用的是函数 parameters(),这样可以获取每个组件中的参数的具体值。模型还有一个属性 parameters ,使用该属性可以获取整个网络的结果,对于如上的模型,获取网络的属性如下所示:
parameters = model.parameters
print(parameters)
"""
<bound method Module.parameters of sequential_test(
(seq_layer): Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
)
)>
"""
2. backward() 函数对参数求导
在计算损失函数时,是将数据和参数进行运算,得到预测结果 y ^ \hat{y} y^,所以预测结果可以表示为 y ^ = W x \hat{y} = Wx y^=Wx, W W W 表示参数。
为了让模型和输入数据计算的结果和真实标签更接近,我们需要通过损失函数相对于参数的导数对参数进行更新,如 θ = θ − η ∂ l ∂ θ \theta = \theta - \eta \frac{\partial l}{\partial \theta} θ=θ−η∂θ∂l。
PyTorch 可以使用 backward() 函数直接计算损失函数相对于每个参数 在当前输入值为
x
x
x 时的导数。计算的结果保存在参数的 .grad 属性中,如下展示了对参数求导的过程。
>>> x = torch.arange(4.0, requires_grad=True) #创建张量时指定可以求导
>>> x.grad #默认为 None
>>> y = 2 * torch.dot(x,x) #计算内积
>>> y
tensor(28., grad_fn=<MulBackward0>) #grad_fn 保存 y 的运算信息,表明 y 是由 x 构建的
>>> y.backward()
>>> x.grad
tensor([ 0., 4., 8., 12.])
>>> x.grad == 4 * x
tensor([True, True, True, True])
2. torch.optim 优化器
优化器会使用参数的梯度,通过某种特定的方法对参数进行更新,不同的更新策略构成了不同的优化算法,PyTorch 实现了很多种优化器,包含在 torch.optim 模块中。
常用的优化器包含两个:
其中 params 表示模型中需要更新的参数,lr 表示学习率。可以通过 model.parameters() 将模型中的参数传入优化器,优化器就会根据参数的梯度采用对应的策略更新参数。
由于 PyTorch 会自动累加每次计算的梯度,所以在每次使用优化器更新参数之前,需要使用 optimiter.zero_grad() 将参数中原有的梯度清零。
-
示例:
import torch from torch import nn class sequential_test(nn.Module): def __init__(self): super().__init__() self.seq_layer = nn.Sequential( nn.Linear(100,1) ) def forward(self, input): output = self.seq_layer(input) return output data = torch.randn(10,100) #随机生成数据 label = (2*data).sum(axis = 1).reshape(10,1) #为数据创建对应的真实结果 y = sum(2x) model = sequential_test() #创建模型 loss = nn.MSELoss() #创建损失函数 optimiter = torch.optim.SGD(model.parameters(),lr = 0.01) #创建优化器,模型的参数通过 model.parameters() 传入 for i in range(100): optimiter.zero_grad() #将原有梯度清零 result = model(data) #计算数据通过模型后的结果 l = loss(result, label) #计算预测结果与真实标签之间的损失 l.backward() #计算 loss 函数中参数的梯度 optimiter.step() #使用优化器更新参数 error = model(data) - label print(error) """ tensor([[ 5.2452e-06], [-3.8147e-06], [ 3.8147e-06], [-3.3379e-06], [ 3.8147e-06], [ 0.0000e+00], [ 0.0000e+00], [ 1.9073e-06], [-1.0967e-05], [ 5.7220e-06]], grad_fn=<SubBackward0>) """
4.4 模型的保存与读取
模型的保存与读取主要有两种方法:
-
保存模型结构和其中的参数
直接通过torch.save(model, "model_name")保存整个模型及其参数值,加载模型时候可以通过torch.load("model_name")加载模型。这种情况加载模型时候需要能够访问模型的定义,如果在一个文件中加载另一个文件中的模型文件,需要先导入该模型。
示例:
import torch from torch import nn class Model(nn.Module): def __init__(self): super().__init__() self.conv2d = nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3, stride = 1) def forward(self, input): output = self.conv2d(input) return output model = Model() print("model:\n",model) torch.save(model, "model_file.pth") #保存整个模型和参数 model2 = torch.load("model_file.pth") print("model2:\n",model2) """ model: Model( (conv2d): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)) ) model2: Model( (conv2d): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)) ) """ -
只保存模型参数(官方推荐)
通过
torch.save(model.state_dict(), "model_name")保存模型的参数通过
torch.load("model_name")加载模型的参数文件,再通过model.load_state_dict(model_para)将模型的参数加载到具体的模型中。示例:
import torch from torch import nn class Model(nn.Module): def __init__(self): super().__init__() self.conv2d = nn.Conv2d(in_channels = 3, out_channels = 1, kernel_size = 3, stride = 1) def forward(self, input): output = self.conv2d(input) return output model = Model() print("model:\n",model) torch.save(model.state_dict(), "model_file2.pth") model_para = torch.load("model_file2.pth") print("model_para:\n", model_para) #加载模型参数 model2 = Model() model2.load_state_dict(model_para) #将模型参数赋给具体的模型 print("model2:\n", model2) """ model: Model( (conv2d): Conv2d(3, 1, kernel_size=(3, 3), stride=(1, 1)) ) model_para: OrderedDict([('conv2d.weight', tensor([[[[-0.1574, 0.1389, 0.1706], [-0.0498, -0.0684, 0.1109], [ 0.1661, -0.0899, 0.1369]], [[ 0.1551, 0.1691, -0.0203], [-0.0054, -0.0779, 0.0521], [ 0.1041, 0.1883, 0.1289]], [[-0.1174, 0.1850, 0.1175], [ 0.1216, 0.0134, -0.0097], [-0.0039, -0.0285, 0.1115]]]])), ('conv2d.bias', tensor([-0.1055]))]) model2: Model( (conv2d): Conv2d(3, 1, kernel_size=(3, 3), stride=(1, 1)) ) """
4.5 完整的训练过程
下面给出了使用训练集对模型进行训练,并且在测试集上验证模型的预测能力的代码框架。
有些网络中可能需要在训练开始之前使用 model.train() 将模型设置为训练状态,在测试开始之前使用 model.eval() 将模型设置为验证状态,这是因为有些模型组件,如:BatchNorm 、Dropout 等需要在训练之前对数据进行操作,而对于测试集中不需要进行这些操作(BatchNorm 需使用训练集计算出的均值和方差归一化测试集,并且测试集不需要 Dropout),因此如果网络包含这些组件,需要切换模型的状态。参考这里。
由于pytorch会把对参数做的所有运算计入对该参数 求导的计算图 中,所以在使用测试集验证模型时,将计算过程放入 with torch.no_grad(): 上下文管理器中,以防止将测试集中的一些计算加入计算图。
train_dataloader #训练集
test_dataloader #测试集
epoch = xxxx #指定最大的训练轮次
loss_fn = nn.xxxxLoss() #创建指定类型的损失函数
optimizer = nn.optim.xxx(loss_fn.parameters(), lr = 0.001) #创建指定类型的优化器
#训练模型
for i in range(epoch):
print("----------开始第 {} 轮训练-------------".format(i+1))
model.train() #将网络设置为训练状态
#遍历整个训练集不断更新参数
for data, targets in train_dataloader:
outputs = model(data) #将模型应用到训练集
loss = loss_fn(outputs, targets) #计算预测值与真实值之间的损失
#优化模型
optimizer.zero_grad() #pytorch 会累加每次计算的梯度,所以需要先清零原来的梯度
loss.backward() #计算当前损失的梯度
optimizer.step() #用上面计算的梯度更新每一个参数
#在测试集上测试模型的效果
model.eval() #将网络设置为验证状态
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): #使用 torch.no_grad() 标识这里面的运算不加入求导的计算图中
for data, targets in test_dataloader:
outputs = model(data)
loss = loss_fn(outputs, targets)
accuracy = ((outputs.argmax(1) == targets)).sum() #计算分类时正确的个数
total_test_loss += loss
total_accuracy += accuracy
print("测试集上总的损失为:{}".format(total_test_loss))
print("测试集准确率:{}".format(total_accuracy/test_data_size))
4.6 利用 GPU 机型训练
利用 GPU 训练可以极大的减少训练时间,PyTorch 使用 GPU 训练的基本思想就是将网络模型、损失函数和数据都使用 GPU 处理,具体的实施方法包括两种:
-
.cuda()方法如下所示,如果 torch 可以使用 GUP,可以在模型、损失函数和数据后使用
.cuda()转移到 GPU 中。if torch.cuda.is_available(): model = model.cuda() loss_fn = loss_fn.cuda() data = data.cuda() targets = target.cuda() -
to(device)可以使用
torch.device("cpu")定义 CPU 训练设备,使用torch.device("cuda:0")定义设备为第一个 GPU。#指定设备 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # model 和 loss_fn 可以直接使用 to() 加载到指定设备 model.to(device) loss_fn.to(device) # data 和 targets 必须重新赋值 data = data.to(device) targets = targets.to(device)

















 8483
8483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









