







本文将详细介绍如何在本地部署 DeepSeek 模型,并以图文的形式把操作步骤展示出来,确保即使是初学者也能轻松上手。
一、本地部署的适用场景
有私密数据需要处理,担心泄密:本地部署可以避免数据上传到云端,确保数据安全, 或者保密单位根本就不能上网的。
需要与本地工作交流结合:处理高频任务或复杂任务时,本地部署允许你对模型进行二次开发和定制, 可以提供更高的灵活性和效率。
瓶颈:本地部署需要较强的硬件支持,尤其是GPU需求。
二、部署过程
比较流行的是使用ollama 网址:https://ollama.com/
ollama 可以理解为替换前面的服务器端,在本地作为服务端,可以是别的平台)+ChatBox、Cherry Studio等
步骤1:下载ollama 一步步安装即可
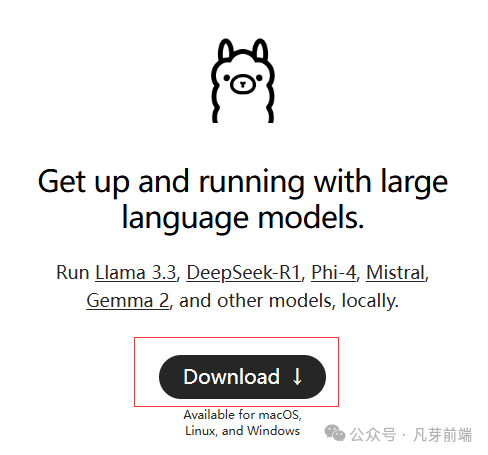
安装成功后,打开命令行(Windows 用户按 Win + R,输入 cmd),输入ollama-v 能查看到ollama版本说明已安装ollama成功
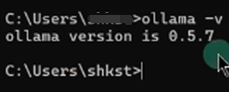
步骤2. 选择并安装模型
打开 Ollama guan网,点击右上角的 Models,选择deepseek-r1
并根据你的电脑性能选择合适的参数版本(如 1.5b、7b、14b 等), 使用满血版:DeepSeek R1 671B全量模型的文件体积高达720GB,对于绝大部分人而言,本地资源有限,很难达到这个配置。
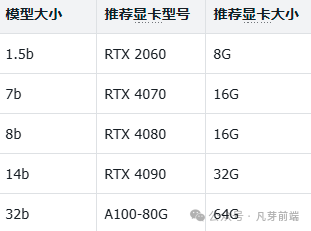
我选择7B,复制命令粘贴到命令窗口,粘贴并运行上述命令,模型将自动下载并安装。
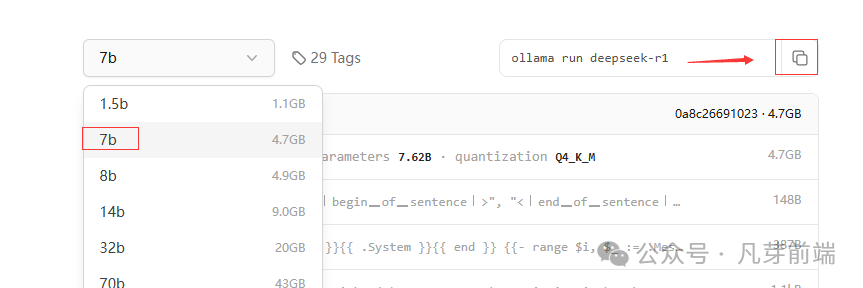

安装成功后输入你的问题,模型会立即给出回答。
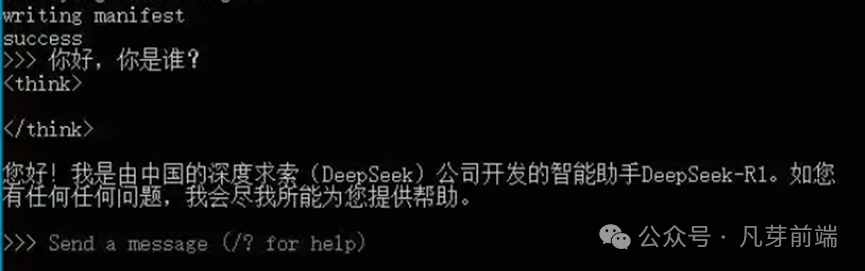
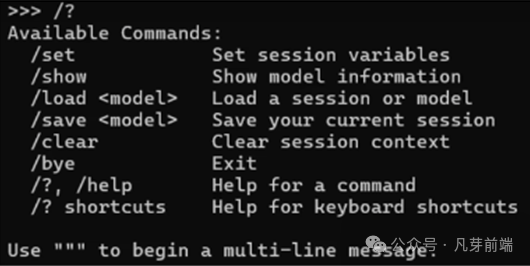
其它命令 /?获取帮助 /bye 退出
步骤3、使用客户端工具
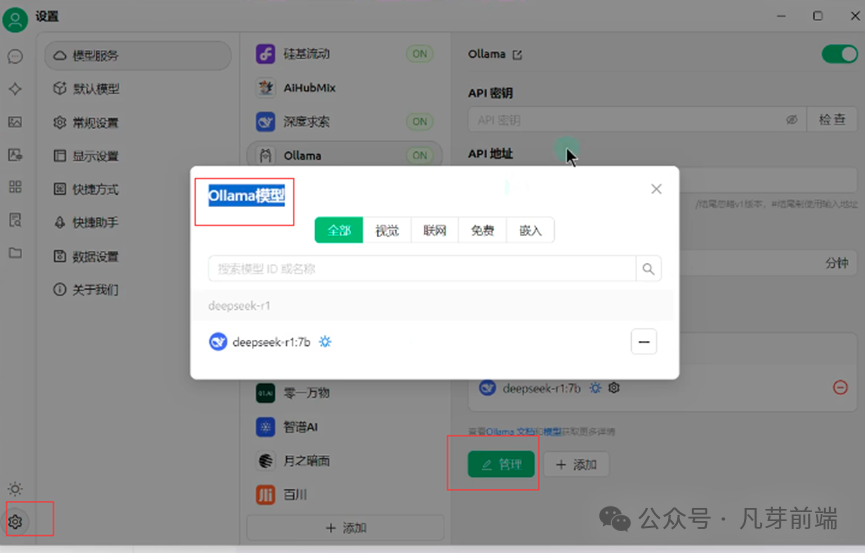
本地部署好模型之后,在命令行操作还是不太方便,我们继续使用一些客户端工具来使用。cherry studio的下载:
cherry Studio的下载地址: https://cherry-ai.com/ 安装后设置ollama为刚才部署的deepseek-r1:7b
步骤4、修改models文件夹路径(可选)
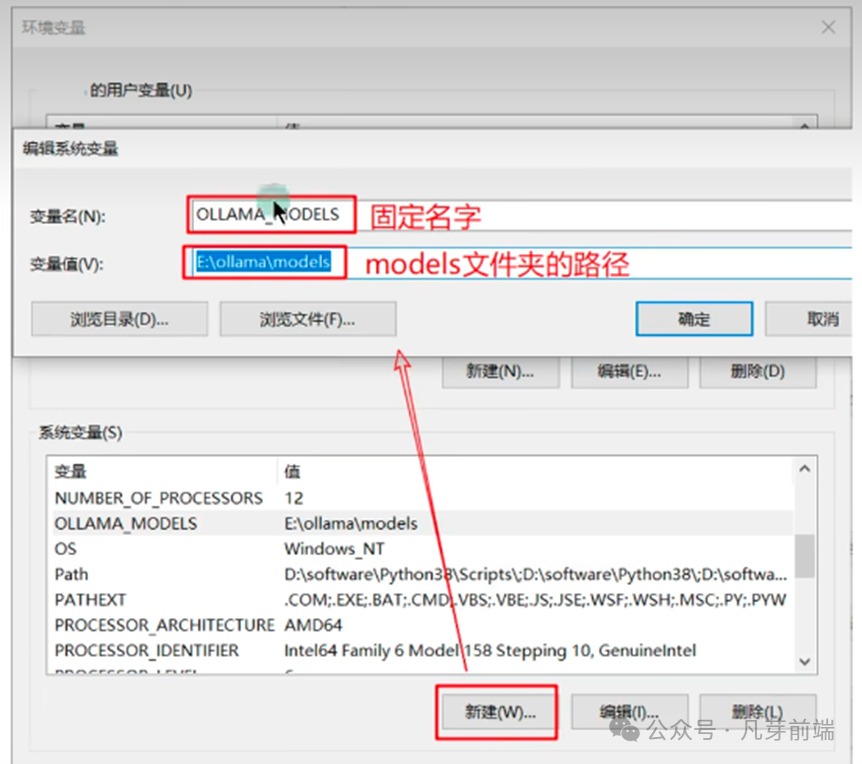
ollama模型默认会下载到:C :\Users\你的用户名\.ollama目录下的models文件夹如果想修改模型的存放位置,做如下配置:
1:拷贝models文件夹到你指定的目录,比如我剪切到E:lollama下
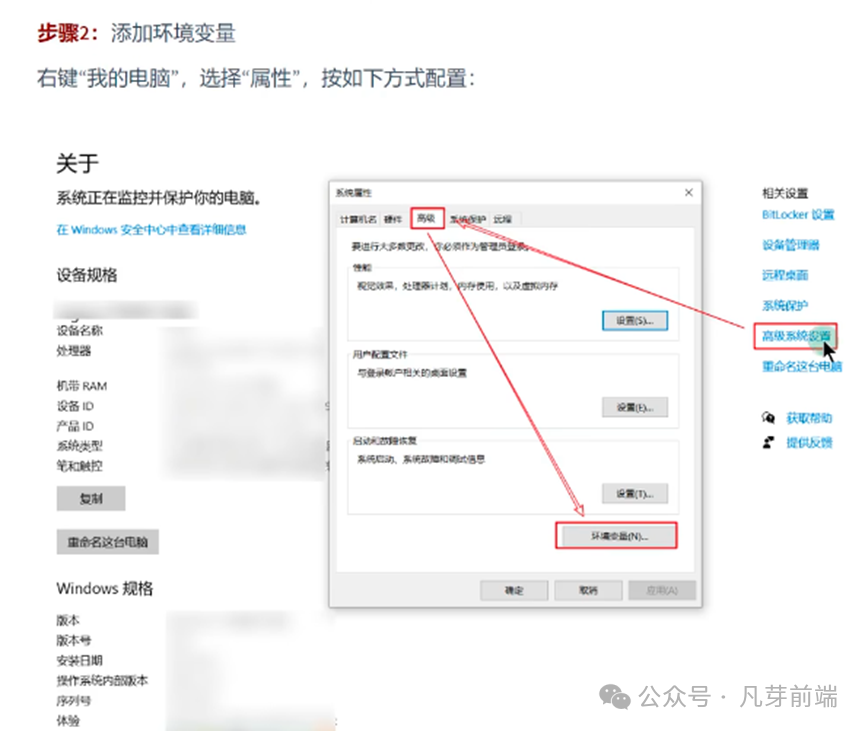
2︰添加环境变量
右键“我的电脑”,选择“属性”,按如下方式配置:
3:重启ollama客户端生效
注意:修改完之后,需要重启ollama客户端,右键图标,选择退出,重新运行ollama
验证是否生效:重新运行ollama之后,重新打开命令行,输入命令ollama list查看:
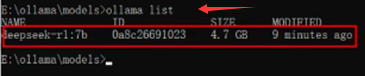
以上本地部署就好了
三,服务器部署(了解)
在企业中,想要私有化部署满血版DeepSeek-R1,即671B版本,需要有更好的硬件配置服务器可以是物理机,也可以是云服务器。
使用ollama提供的经过量化压缩的671B模型的大小是404GB,建议≥500 GB。
根据官方及社区的讨论,满血版R1(671B,且不做量化)需要2台8卡H100,或1台8卡 H20,或1台8卡H200来实现所有模型参数的内存卸载。如果按这种说法,只有预算至少在200万以上的企业级应用才能用上R1本地化部署。因此,UnslothAl社区推出的量化版本R1可以作为使用满血版R1前的"试用装"。——Unsloth:我们探索了如何让更多的本地用户运行它,并设法将DeepSeek的R1 671B参数模型量化为131GB,从原来的720GB减少了80%,同时非常实用。
在实际部署中,不同的动态量化+版本的效果不同:
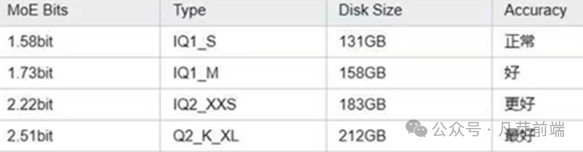
举例几种性价比配置如下:
-
Mac Studio:配备大容量高带宽的统一内存(比如x上的@awnihannun使用了两台192 GB内存的Mac Studio运行3-bit量化的版本)
-
高内存带宽的服务器:比如HuggingFace上的alain401使用了配备了24×16GB DDR5 4800内存的服务器)
-
云GPU服务器:配备2张或更多的80GB显存GPU(如英伟达的H100,租赁价格约2美元/小时/卡)
-
在这些硬件上的运行速度可达到10+ token/秒。
部署流程与个人电脑部署7B的流程没有太大区别,都是以下几个步骤:
1.根据服务器的操作系统,下载对应版本的ollama客户端;
2.运行ollama,执行ollama命令运行671B版本模型;首次执行自动下载模型;
3.使用客户端工具/自己开发页面/代码调用,对接ollama的R1模型;
四,总结
通过以上步骤,你可以轻松在本地部署 DeepSeek 模型。无论是通过手动安装还是使用 Ollama,本地部署都能为你提供更高的灵活性和数据安全性。
阅读原文 关注公众号获取更多干货!


















 3100
3100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











