







文章目录
0. 引言
本文对比介绍几类 BERT 改进版模型: RoBERTa、DistilBERT、ALBERT、ELECTRA 以及 DeBERTa,下面表格是汇总一览:
| 序号 | 名称 | 年份 | 核心思想 |
|---|---|---|---|
| 1 | RoBERTa | 2019 | 增添数据集及训练批次、移除 NSP 目标、采用动态 Masking、采用字节级 BPE 词汇表 |
| 2 | DistilBERT | 2020 | 采用知识蒸馏技术精简 BERT 模型 |
| 3 | ALBERT | 2020 | 通过因子化嵌入参数化和跨层参数共享减少参数、移除 MLM 并增加 SOP |
| 4 | ELECTRA | 2020 | 采用生成器+判别器。生成器生成新的 token、判别器来区分生成的 token |
| 5 | DeBERTa | 2021 | 预训练采用分离注意力机制和增强型掩码解码器,微调阶段采用虚拟对抗训练方法 |
1. RoBERTa
1.1 概览
RoBERTa,来源于2019年论文*《RoBERTa: A Robustly Optimized BERT Pretraining Approach》*,是一种对 BERT 预训练方法的改进。它通过对 BERT 模型的预训练过程进行细致的调整和优化,以提高模型在各种自然语言处理任务上的性能。RoBERTa 的主要目标是通过对关键超参数和训练数据大小的影响进行仔细的测量,从而提出一种改进的 BERT 训练方法,这种方法能够匹配或超过 BERT 模型的性能。
论文:https://arxiv.org/pdf/1907.11692
1.2 改进点
RoBERTa 相对于原始 BERT 模型的改进点主要包括:
1.2.1 数据集
包含 BOOKCORPUS、CC-NEWS、OPENWEBTEXT、STORIES。研究者们收集了一个大型的新数据集 CC-NEWS,这个数据集包含了大量的新闻文章。
1.2.2 更大批次
训练更长时间,使用更大的批次大小,覆盖更多的数据。
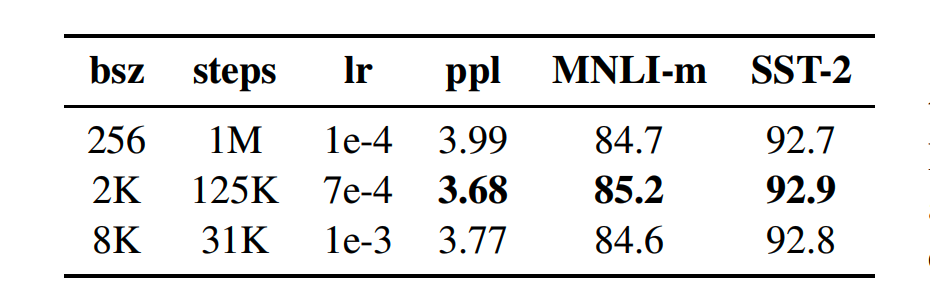
从实验可以看出,大批次训练降低了掩蔽语言建模(masked language modeling)目标的困惑度,以及最终任务的准确性。大批量处理也更容易通过分布式处理进行数据并行训练,RoBERTa 后来的实验中用 8K 序列批量训练。
1.2.3 移除NSP目标
移除了 BERT 的 NSP(Next Sentence Prediction)目标 。
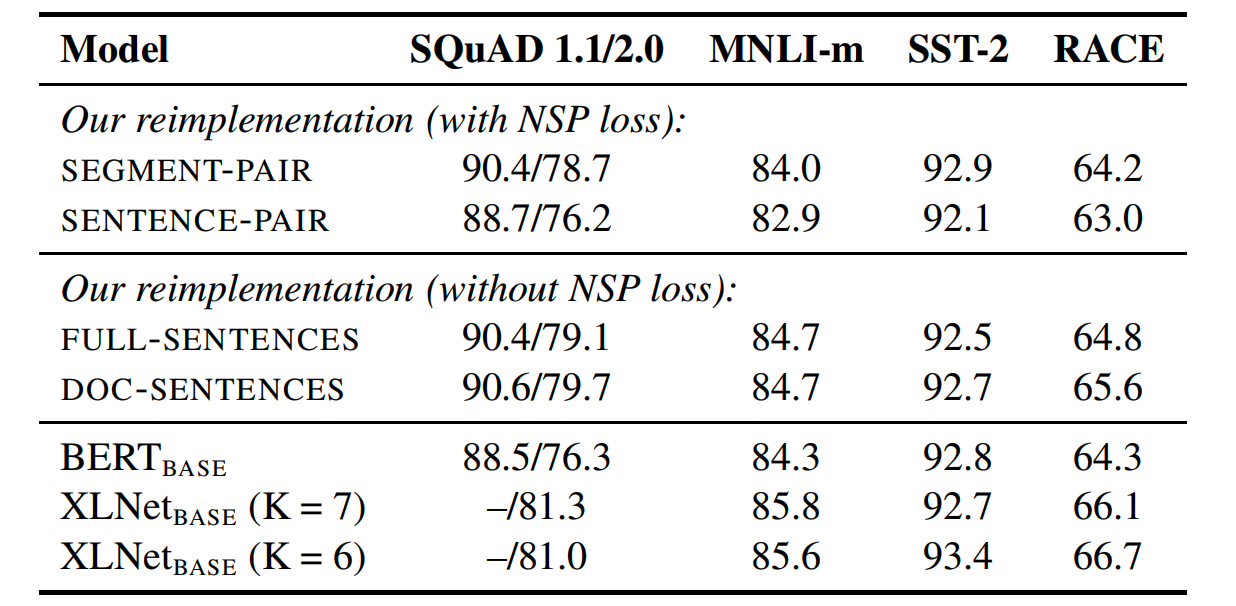
- **SEGMENT-PAIR+NSP:**原始 BERT 使用的输入格式,其中包含两个段落,中间用特殊的分隔符 [SEP] 隔开;
- **SENTENCE-PAIR+NSP:**与 SEGMENT-PAIR+NSP 类似,但输入由一对自然句子组成,而不是段落,句子可以来自同一个文档的连续部分,或者来自不同的文档;
- **FULL-SENTENCES(无 NSP):**输入由完整的句子组成,这些句子连续从一个或多个文档中采样。当达到一个文档的末尾时,模型会开始从下一个文档中采样句子,并在文档之间添加额外的分隔符。这种格式去除了 NSP 目标,因为它假设输入的连续性不再是预测任务的一部分。
**4. DOC-SENTENCES(无 NSP):**与 FULL-SENTENCES 类似,但它限制输入不能跨越文档边界。
从实验可以看出,无 NSP 的模型在 SQuAD 数据集上评测效果表现整体更好,其中 DOC-SENTENCES 输入格式效果则更佳。然而,由于 DOC-SENTENCES 导致批次大小可变,在其余的实验中使用 FULL-SENTENCES,以便于与相关工作进行比较。
1.2.4 采用动态 Masking 模式
训练时采用动态 Masking 模式
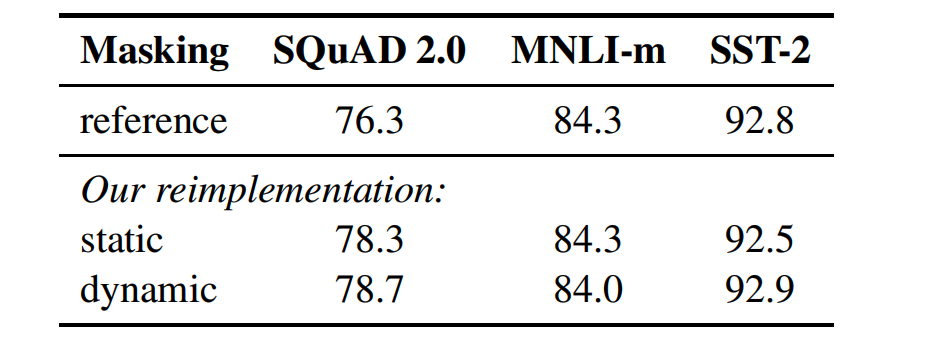
原始 BERT 模型在数据预处理阶段对每个样本只进行一次掩码操作,这可能导致模型在训练过程中多次看到相同的掩码模式。RoBERTa 通过动态改变掩码模式,即每次将数据输入模型时都重新生成掩码,增加了训练数据的多样性,迫使模型学习更加鲁棒的特征。
1.2.5 采用字节级BPE词汇表
使用更大的字节级 BPE (Byte-Pair Encoding)词汇表,而不是基于字符的 BPE 词汇表。
BERT 原始模型使用的是基于字符的 BPE 的 30K 词汇表,这限制了词汇表的大小和覆盖范围。RoBERTa 采用了一个更大的字节级 BPE 50K 词汇表,这允许模型处理更多样化的词汇,包括罕见词和专有名词,而不需要将它们替换为“unknown”标记。
2. DistilBERT
2.1 概览
DistilBERT 来源于2020年论文 《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》,在预训练阶段使用知识蒸馏技术将 BERT 模型精简。DistilBERT 在保持 BER T模型97%的语言理解能力的同时,减少了40%的模型大小,并且在推理速度上提高了60%。DistilBERT 不仅体积更小、速度更快,而且成本更低,更适合在设备上进行计算。
论文:https://arxiv.org/pdf/1910.01108
2.2 改进点
DistilBERT 核心的思想是知识蒸馏,所以这里主要介绍下知识蒸馏的核心流程。
《Distilling the Knowledge in a Neural Network》 是关于知识蒸馏(Knowledge Distillation)技术的重要论文,由 Hinton 等人于2015年提出。这篇论文详细介绍了如何将一个大型的、复杂的机器学习模型(教师模型)的知识转移到一个较小的模型(学生模型)中,从而使小模型能够在保留大部分性能的同时拥有更高的效率。
2.2.1 核心思想
知识蒸馏的核心思想是利用教师模型的软标签(soft labels)来训练学生模型。这里的软标签(soft labels)是指教师模型对输入数据预测的概率分布,传统的硬标签(hard labels)是指真实的分类标签。
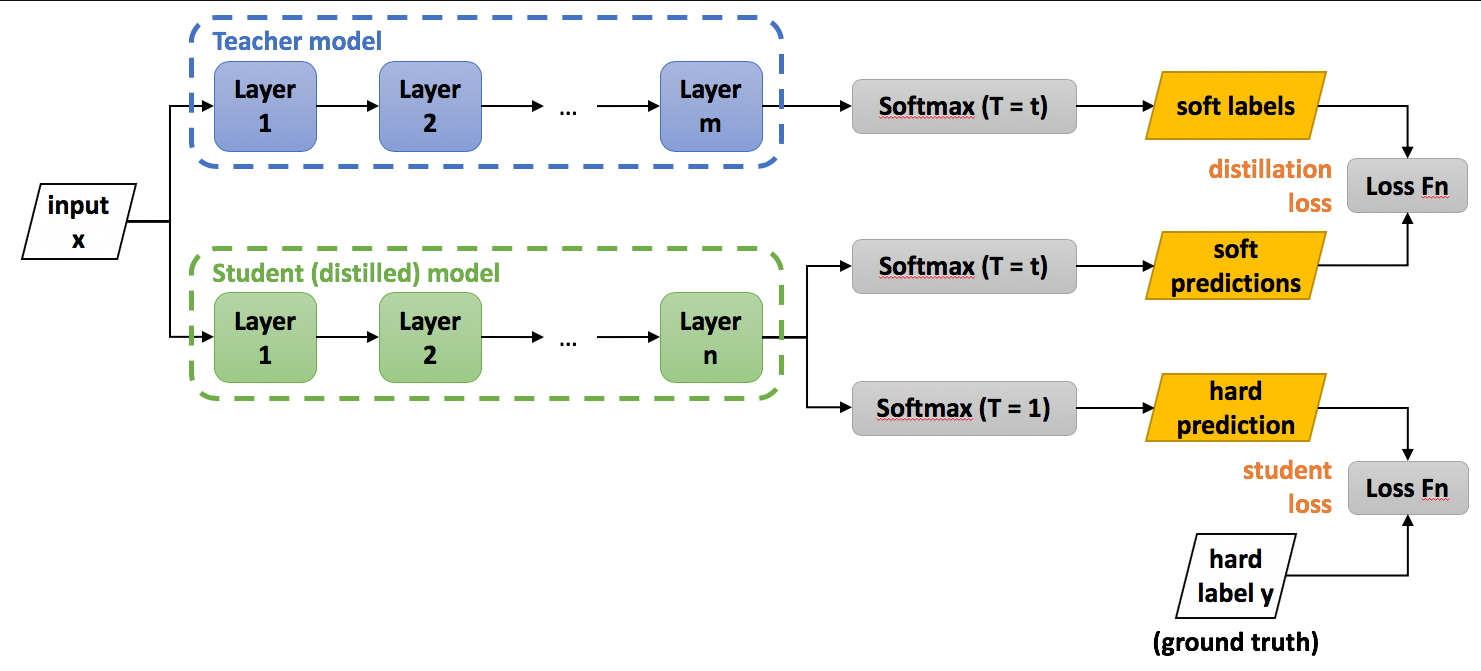
(1)软标签(Soft Labels)
教师模型对输入样本的预测输出是一个概率分布,而不是单一的类别标签。这种概率分布包含了教师模型对于各个类别的置信度,比硬标签提供了更多关于类间关系的信息。
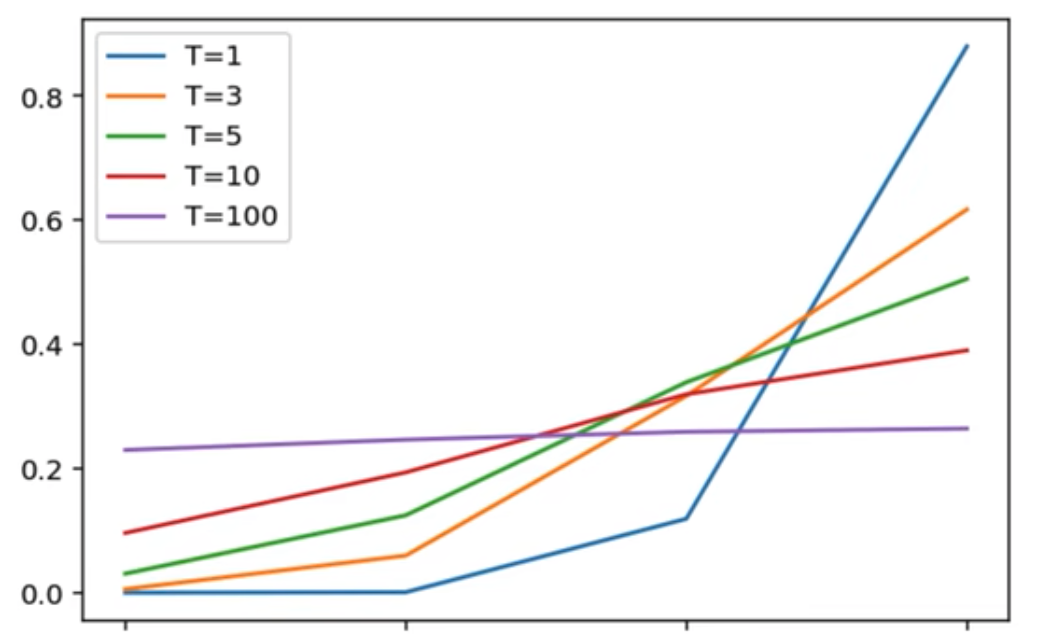
(2)温度参数(Temperature Parameter)
为了使概率分布更加平滑,引入了一个温度参数
T
T
T,它可以放大或缩小教师模型输出的 softmax 函数的值。
q
i
=
e
z
i
T
∑
e
z
i
T
q_i = \frac{e^{\frac{z_i}T}}{\sum e^{\frac{z_i}T}}
qi=∑eTzieTzi
- 较低的温度 T T T 更接近标准的 softmax 输出,当 T = 1 T=1 T=1 是就是标准的 softmax;
- 较高的温度 T T T 会使概率分布更加平滑,更容易被学生模型学习;
(3)损失函数(Loss Function)
在知识蒸馏中,蒸馏的学生模型,既希望能学习到教师模型的概率分布情况(soft labels),又能预测偏向真实情况(hard labels),于是 loss 可以分成两项交叉熵之和:
l
o
s
s
=
α
H
(
t
e
a
c
h
e
r
(
x
)
,
s
t
u
d
e
n
t
(
x
)
)
+
(
1
−
α
)
H
(
t
a
r
g
e
t
,
s
t
u
d
e
n
t
(
x
)
)
loss = \alpha H(teacher(x),student(x)) + (1- \alpha) H(target,student(x))
loss=αH(teacher(x),student(x))+(1−α)H(target,student(x))
其中:
- H ( t e a c h e r ( x ) , s t u d e n t ( x ) ) H(teacher(x),student(x)) H(teacher(x),student(x)) 是教师模型与学生模型的交叉熵
- H ( t a r g e t , s t u d e n t ( x ) ) H(target,student(x)) H(target,student(x)) 是学生模型与真实情况的交叉熵
- α \alpha α 是一个超参数,用来平衡两个损失项的权重
(4)举例
- 教师模型输出的概率结果是: [ 0.1 , 0.4 , 0.5 ] [0.1, 0.4, 0.5] [0.1,0.4,0.5],即是第一项的概率为0.1,第二项的概率为0.4,第三项的概率为0.5
- 学生模型输出的概率结果是: [ 0.11 , 0.43 , 0.46 ] [0.11, 0.43, 0.46] [0.11,0.43,0.46],即是第一项的概率为0.11,第二项的概率为0.43,第三项的概率为0.46
- 真实的结果是: [ 0 , 0 , 1 ] [0,0,1] [0,0,1],即实际情况就是对应第三项
- 假设 α = 0.7 \alpha = 0.7 α=0.7
则:
l
o
s
s
=
−
0.7
∗
(
0.1
∗
l
o
g
(
0.11
)
+
0.4
∗
l
o
g
(
0.43
)
+
0.5
∗
l
o
g
(
0.46
)
)
−
0.3
∗
l
o
g
(
0.46
)
loss = -0.7 * (0.1*log(0.11)+0.4*log(0.43)+0.5*log(0.46))-0.3*log(0.46)
loss=−0.7∗(0.1∗log(0.11)+0.4∗log(0.43)+0.5∗log(0.46))−0.3∗log(0.46)
3. ALBERT
3.1 概览
ALBERT,来源于2020年论文 《ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》,提出了 ALBERT(A Lite BERT),一种用于自监督学习的语言表示模型。ALBERT 通过两种参数减少技术降低了 BERT 模型的内存消耗并提高了训练速度,同时引入了句子顺序预测(SOP)的自监督损失,专注于建模句子间的连贯性。
论文:https://openreview.net/pdf?id=H1eA7AEtvS
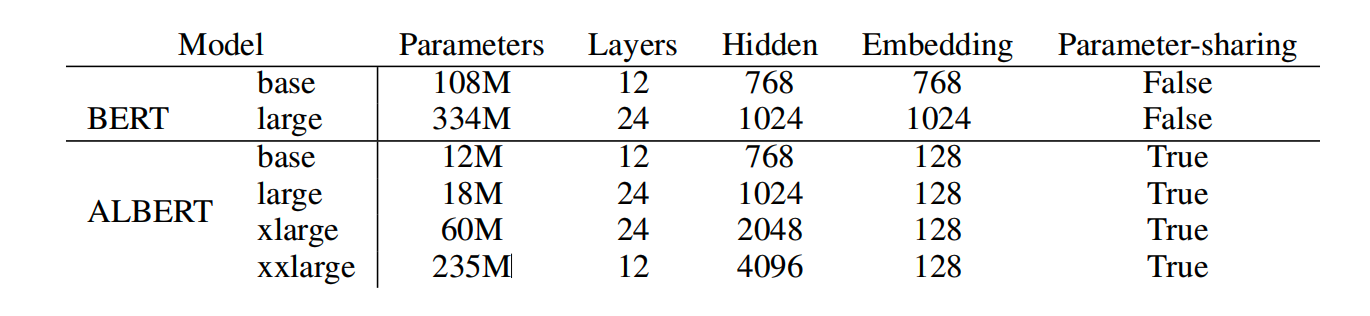
以下是参数对比:
3.2 改进点
3.2.1 因子化嵌入参数化
因子化嵌入参数化(Factorized Embedding Parameterization)。
在 BERT 模型中,词汇嵌入(WordPiece embeddings)的大小与隐藏层(hidden layer)的大小是相等的,即 $E \equiv H$。这种设计在建模和实际应用中存在一些局限性:
-
建模角度: 词汇嵌入旨在学习上下文无关的表示,而隐藏层嵌入旨在学习上下文相关的表示。BERT 的强大之处在于利用上下文信息来学习这些上下文相关的表示。因此,将词汇嵌入大小 $E$ 与隐藏层大小 $H$ 分离,可以更高效地利用模型参数,因为通常 $H$ 远大于 $E$。
-
实际应用角度: 自然语言处理通常需要较大的词汇表。如果 $E \equiv H$,那么增加 $H$ 会增加嵌入矩阵的大小,从而导致模型参数数量急剧增加,这在训练时会导致内存消耗过大。
为了解决这些问题,ALBERT 采用了因子化嵌入参数化技术:
- 将嵌入参数分解为两个较小的矩阵。ALBERT 不是直接将 one-hot 向量投影到大小为 $H$ 的隐藏空间,而是首先将它们投影到一个较低维度的嵌入空间(大小为 $E$),然后再投影到隐藏空间。
- 通过这种分解,嵌入参数从 $O(V \times H)$ 减少到 $O(V \times E + E \times H)$,当 $H$ 远大于 $E$ 时,这种参数减少是显著的。
3.2.2 跨层参数共享
在 ALBERT 模型中,为了进一步提高参数效率并减少模型大小,采用了跨层参数共享(Cross-Layer Parameter Sharing) 技术。这种技术的核心思想是在模型的所有层之间共享相同的参数集,而不是为每一层独立学习一组参数。具体来说,ALBERT 在所有层之间共享以下参数:
-
自注意力层(Self-Attention Layers):在所有层之间共享自注意力机制的参数,包括 q(query)、k(key)、v(value)矩阵以及注意力输出的线性变换矩阵。
-
前馈网络(Feed-Forward Networks, FFN):在所有层之间共享前馈网络的权重矩阵和偏置项。这意味着每一层的前馈网络使用相同的参数集。
这种跨层参数共享策略有几个优势:
-
减少参数数量:通过在所有层之间共享参数,ALBERT 显著减少了模型的总参数数量。一个具有24层的 ALBERT-large 模型,其参数数量远少于具有相同层数的 BERT-large 模型。
-
提高训练效率:由于参数数量的减少, ALBERT 在训练时需要更新的参数更少,这不仅减少了内存占用,还加快了训练速度。
-
稳定训练过程:跨层参数共享作为一种正则化形式,有助于稳定训练过程,因为它减少了过拟合的风险。此外,参数的共享使得模型在不同层之间保持了一致性,这有助于模型更好地泛化。
-
保持表示质量:尽管参数数量减少,但 ALBERT 通过跨层参数共享仍然能够学习到高质量的表示。实验结果表明,ALBERT在多个下游任务上取得了与BERT相当甚至更好的性能。
在 ALBERT 中,跨层参数共享的实现方式是将每一层的参数设置为相同,并在整个网络中重复使用这些参数。这种设计允许模型在保持参数数量可控的同时,捕获不同层次的特征表示,从而在各种自然语言理解任务中取得了优异的性能。
3.2.3 句子顺序预测
在 ALBERT 模型中,除了传统的遮蔽语言模型(Masked Language Modeling, MLM)损失外,还引入了一种新的自监督损失,即**句子顺序预测(Sentence Order Prediction, SOP)**损失。这种损失专注于建模句子间的连贯性,与 BERT 中的下一个句子预测(Next Sentence Prediction, NSP)损失相比,SOP 损失更专注于句子间的逻辑和语义连贯性。
-
改进句子间关系的理解:在许多自然语言处理任务中,理解句子间的逻辑和语义关系至关重要。SOP损失通过预测两个连续文本片段的顺序,迫使模型学习句子间的连贯性。
-
解决 NSP 的局限性:BERT 中的 NSP 损失旨在预测两个句子是否在原始文本中连续出现。然而,后续研究表明 NSP 的预测效果不稳定,且其任务难度相对较低。SOP 损失通过专注于句子间的连贯性,提高了任务的难度和实用性。
SOP 损失的实现方式如下:
-
正例:使用与 BERT 相同的技巧,即从训练语料中选取连续的两个文本片段作为正例。
-
负例:将这两个连续的文本片段顺序颠倒,作为负例。这种设计迫使模型学习区分不同顺序下的文本片段,从而更好地捕捉句子间的连贯性。
-
损失计算:模型需要预测给定的两个文本片段的原始顺序。这可以通过一个二分类任务来实现,其中模型需要判断两个文本片段的顺序是否正确。
4. ELECTRA
4.1 概览
ELECTRA(“Efficiently Learning an Encoder that Classifies Token Replacements Accurately”),来源于2020年论文 《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》,介绍了一种新型预训练文本编码器方法,该方法与传统的基于生成器的预训练方法(如BERT)不同,它采用了一种判别器的视角来进行预训练。ELECTRA 的核心思想是通过替换输入中的某些标记(tokens),而不是将它们掩盖起来,然后训练一个判别模型来预测每个标记是否被替换了。这种方法被称为“替换标记检测”(replaced token detection)。
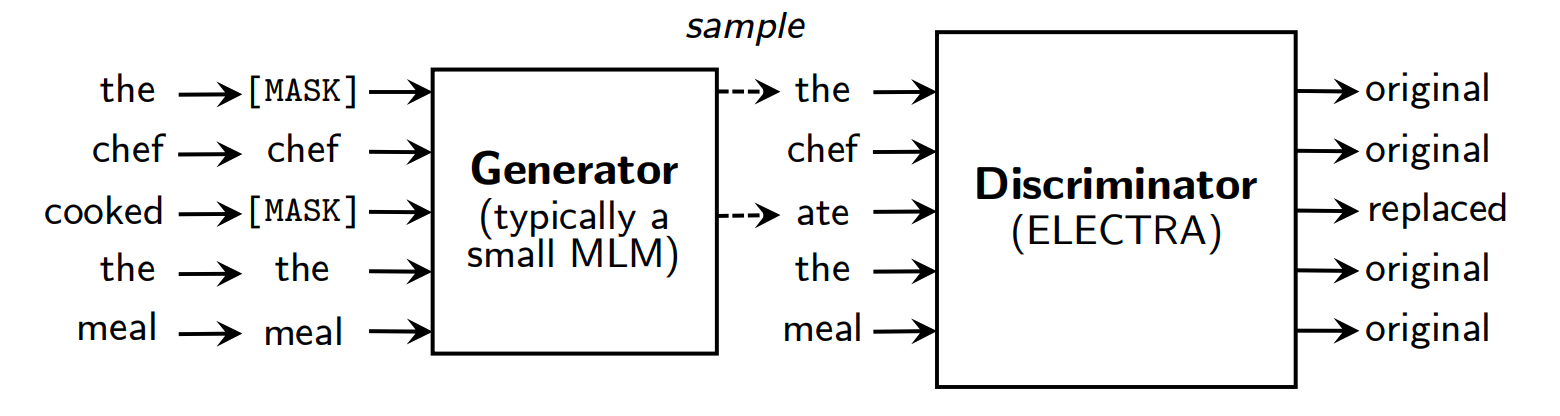
ELECTRA 模型由两个主要部分组成:一个小型的生成器网络和一个判别器网络。生成器负责生成可能的替换标记,而判别器则负责区分原始标记和生成器生成的替换标记。
论文:https://openreview.net/pdf?id=r1xMH1BtvB
4.2 改进点
ELECTRA 相较于传统的 BERT 模型,在多个方面进行了改进,使其在预训练效率和下游任务表现上都有所提升:
-
判别器与生成器的结合:与 BERT 的生成器任务不同,ELECTRA 使用了一个判别器来区分真实的输入标记和生成器生成的假标记。这种判别器任务在计算上更高效,因为它涉及到所有输入标记。
-
更小的模型尺寸和更快的训练速度:文章中提到,即使是较小的 ELECTRA 模型(如 ELECTRA-Small),也能在单个 GPU 上快速训练,并且在 GLUE 基准测试中取得了比 BERT 更好的结果。
-
计算效率的提升:ELECTRA 在计算效率上也有所提升,它可以在使用更少的计算资源的情况下,达到与 RoBERTa 和 XLNet 相当的性能。此外 ELECTRA 在相同的模型大小、数据和计算资源下,其学习到的上下文表示比 BERT 的更好,特别是在小模型上,ELECTRA 的表现尤为突出。
5. DeBERTa
5.1 概览
DeBERTa,来源于2021年论文 《Decoding-enhanced BERT with disentangled attention》。DeBERTa 模型在预训练阶段引入了分离注意力机制和增强型掩码解码器,以及在微调阶段使用了新的虚拟对抗训练方法来提高模型的泛化能力。
论文:https://arxiv.org/pdf/2006.03654
5.2 改进点
-
分离注意力机制(Disentangled Attention):DeBERTa 模型中,每个单词使用两个向量分别编码其内容和位置信息。这种机制考虑了单词对之间的注意力权重不仅取决于它们的内容,还取决于它们的相对位置。
-
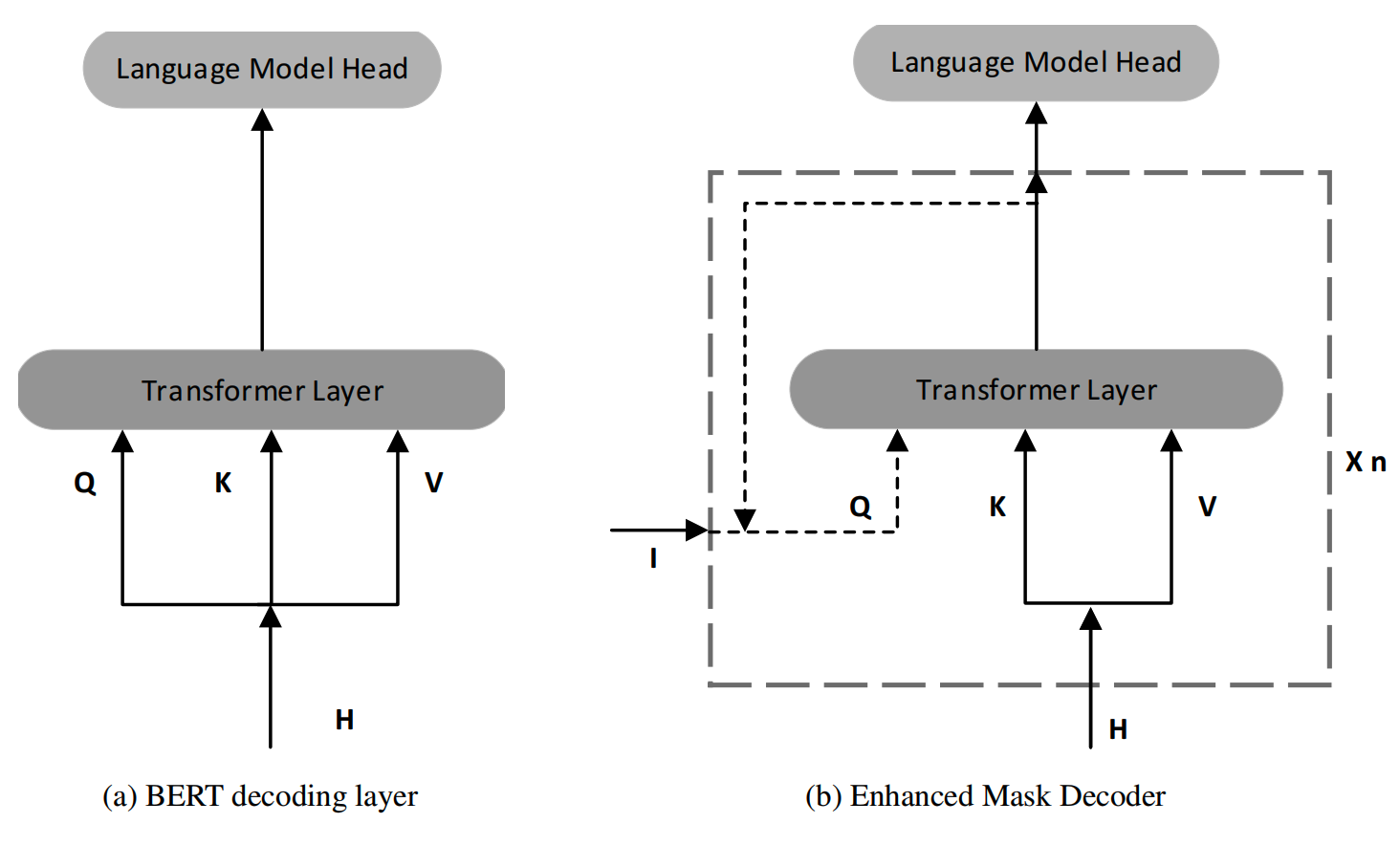
增强型掩码解码器(Enhanced Mask Decoder):DeBERTa 模型在预训练时使用掩码语言模型(MLM),通过周围单词预测被掩码的单词。除了考虑上下文单词的内容和相对位置信息外,DeBERTa 还引入了绝对位置信息,以提高预测的准确性。绝对位置信息在所有 Transformer 层之后和 softmax 层之前被加入,作为解码掩码单词的补充信息。
- 虚拟对抗训练方法(Virtual Adversarial Training):提出了一种新的虚拟对抗训练算法,用于微调预训练语言模型,以提高模型在下游 NLP 任务中的泛化能力。通过在单词嵌入上施加小的扰动来创建对抗性样本,并通过正则化模型使其对这些扰动具有鲁棒性。
参考
[1] https://arxiv.org/pdf/1907.11692
[2] https://arxiv.org/pdf/1910.01108
[3] https://openreview.net/pdf?id=H1eA7AEtvS
[4] https://openreview.net/pdf?id=r1xMH1BtvB
[5] https://arxiv.org/pdf/2006.03654
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











