







文章
R. Li, W. Gong (corresponding author), C. Lu(corresponding author), Self-adaptive multi-objective evolutionary algorithm for flexible job shop scheduling with fuzzy processing time, Computers & Industrial Enginering. 2022, 168, 108099 .(中科院分区T2,IF 5.431).
DOI
文章链接
Matalb sourcecode
研究背景
主要是目前智能制造中,能效问题成为了几年前研究的重点。而柔性作业车间又是很经典的一块学术分支。此外在制造过程中,加工时间的不确定性,有一个方向是用模糊柔性加工时间来对时间约束进行预测。
研究问题
本文研究的是多目标模糊柔性作业车间调度问题,加工时间用三角模糊数表示,然后同时优化最大最小完工时间和最大机器负载。因为我觉得能耗和机器负载有关。但事实上有更加成熟的表达。当时是研一上学期,思考比较欠缺。
模糊柔性作业车间调度问题包含两个子问题:确定一个工序加工顺序和给每个工序选择一个加工机器。除此之外具有以下特性:一共有N个工件,每个工件有Ni个工序,总共有M台机器,每个工序可以在M的子集M‘中选择一台加工机器,每个工序Oij在机器上Mk的加工时间为一个三角模糊数。
三角模糊数的隶属度函数。

加工时间用上下界和中心表示 (t1,t2,t3).
研究动机
在多目标模糊柔性作业车间调度问题中,我发现前人的对于多目标优化问题中缺少一个有效的分布性策略。还有就是多目标的模糊柔性作业车间调度问题研究也很少。所以我采用基于分解的多目标进化算法(MOEA/D)求解。但在实验过程中,发现不同测试集的最优参数不同。所以希望做一个参数自适应策略,让算法自动选择不同大小的邻域,来适应不同的测试问题。
研究方法
算法框架

首先种群初始化。其次计算适应值,然后初始化参考线大小和种群大小相同为Np,随后采用轮盘赌方法为种群中每个个体分配一个邻域大小T,随后是种群采用MOEA/D的框架交叉变异和环境选择,最后对每个个体执行变邻域搜索,然后根据第6步中每个T参数成功更新种群的次数,来为每个T参数重新分配轮盘赌选择概率。
编码和解码
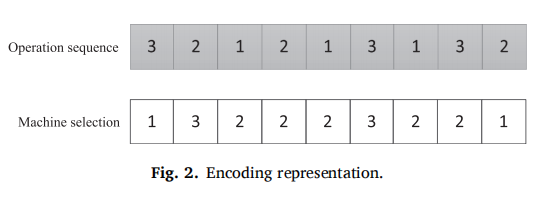
编码长这样,工序顺序是
O
3
,
1
,
O
2
,
1
,
O
1
,
1
,
O
2
,
2
,
O
1
,
2
,
O
3
,
2
,
O
1
,
3
,
O
3
,
3
,
O
2
,
3
.
O_{3,1},O_{2,1},O_{1,1},O_{2,2},O_{1,2}, O_{3,2},O_{1,3},O_{3,3},O_{2,3}.
O3,1,O2,1,O1,1,O2,2,O1,2,O3,2,O1,3,O3,3,O2,3. 机器选择是
M
1
,
M
3
,
M
2
,
M
2
,
M
2
,
M
3
,
M
2
,
M
2
,
M
1
M_1,M_3,M_2,M_2,M_2,M_3,M_2, M_2,M_1
M1,M3,M2,M2,M2,M3,M2,M2,M1. 最后展示出来的是这样工序与机器选择一 一对应。但实际上在编程的时候,机器码排列顺序是按照工序
O
1
,
1
,
O
1
,
2
,
.
.
.
,
O
1
,
N
1
,
O
2
,
1
,
O
2
,
2
,
.
.
.
,
O
2
,
N
2
,
.
.
.
,
O
N
,
1
,
.
.
.
,
O
N
,
N
N
.
O_{1,1},O_{1,2},...,O_{1,N1},O_{2,1},O_{2,2}, ...,O_{2,N2},...,O_{N,1},...,O_{N,NN}.
O1,1,O1,2,...,O1,N1,O2,1,O2,2,...,O2,N2,...,ON,1,...,ON,NN.的顺序排列的。可以理解为一个固定好的表格,只不过每个解里面的数据不一样,所以无论在交叉变异的时候,机器码数值如何变化,和工序都是可以对应上。不会出现不可行解。
混合初始化策略
采用了两个分派规则:
Local processing time minimum rule (LS):每个工序选择当自己的最小加工时间机器
Global machine workload minimum rule (GW):每个工序选择当前调度环境中机器负载最小的机器
混合策略:采用LS和GW分别产生Np/3大小的子种群(向下取整),剩下的用随机初始化补齐。
交叉变异和环境选择

(a)是工序交叉。(b)是机器交叉。
工序变异:随机选择工序码上两个基因交换。
机器变异:随机选择两个工序,它们各自重新选择一个加工机器。
环境选择:采用MOEA/D 的聚合函数,这样可以平衡收敛性和分布性。

聚合函数值为,当前分配的参考向量,每个维度去乘以,当前目标函数值与参考点差的绝对值。参考点的每一维是每个目标函数的最小值。然后在每一维的投影中选择下降空间最大的方向作为聚合函数值。

变邻域局部搜索
设计了五个局部搜索算子来提升收敛性。
LS1:找到当前序列中,最后一个被加工完的工序,替换它的机器。
LS2:随机选择一个工序,然后换它的机器。
LS3:找到当前机器负载最大的机器,将该机器上随机选择一个工序移到其他机器上。
LS4:随机选两个工序,交换它的位置。
LS5:随机选择两个工序,将靠后的工序插入到靠前的工序的前面。
对于每个工序,执行变邻域搜索,如果LS1成功了就跳出,否则执行LS2,如果LS2成功则跳出,否则执行LS3,以此类推,直到五个LS都过完。
参数自适应选择
MOEA/D的性能受邻域大小T影响。所以设置了一个参数池 T = {T1, T2, …, Tn}.
采用轮盘赌的方式为每个个体分配一个Ti。然后经过这一轮迭代,把当前参数的成功次数和失败次数都累计起来存入一个长度为LP的存档中。文中设置为45。

刚开始LP轮次,所有参数的选择概率都是1/n,当进化代数超过了LP,则开始统计过去LP轮次中每个参数的成功次数和失败次数。按列累和起来,那么每个参数的成功率就是成功次数总和除以成功次数总和加失败次数总和。最后将所有参数的成功率归一化。作为下一轮每个参数的选择概率。然后将当前轮次的成功次数统计插入到成功记忆,失败次数统计插入到失败记忆。并且将两个矩阵的第一行记录删掉。

实验结果
实验测试集和指标
选自两个经典的模糊柔性作业车间调度问题。可以在我的主页中下载。
另外由于测试问题太少,我选择了柔性作业车间调度问题的经典测试算例Mk测试集,并采用一定策略将其制作成模糊加工时间。具体方法在文中有提及。最后总共是23个测试问题。
实验指标用HV和GD还有Spread。
对比实验
只贴出来Frideman test的结果。写的太累了偷个懒。
在HV和GD上rank第一,在Spread上rank第二。

HV指标收敛图

PF前沿对比图。

在Lei第四个测试集
最后画出来的最小完工时间的甘特图

总结
总的来说,文章写的不太好,质量还需要提升。继续加油继续进步,后续会持续更新车间调度相关内容。都会附上代码。其他的代码都可以在我的个人主页上去下载。














 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









