







🌟 0x00 开篇暴击 | 为什么你的文件压缩总是不给力?
有没有遇到过这些崩溃瞬间?
👉 游戏贴图加载卡成PPT 🐢
👉 发送100MB日志文件被邮箱拒收 ❌
👉 监控视频存储3天就撑爆硬盘 💥
哈夫曼编码——这个70年前的黑科技,至今仍是无损压缩领域の王者!🎯
(悄悄说:ZIP/PNG/JPEG都在用它哦~)
🧠 0x01 原理剖析 | 哈夫曼编码の灵魂三问
1.1 基本思想
哈夫曼编码由David Huffman于1952年发明,核心是变长前缀编码:
- 🔥 高频字符用短码(如'e'→
01) - ❄️ 低频字符用长码(如'z'→
101010)
神奇效果:把"ABBCCCDDDD"压缩成0 10 10 110 110 110 1110 1110 1110 1110,体积直接减半!🎉
1.2 数学本质
根据香农信息论,最优编码长度应满足:
码长L(c) ≈ -log₂(P(c))
其中P(c)是字符概率。哈夫曼编码通过贪心算法逼近这一理论极限!
1.3 哈夫曼树构建步骤
(以字符集{A:3, B:2, C:1, D:1}为例)
1️⃣ 初始化森林:每个字符作为独立树🌳
2️⃣ 循环合并最小两棵树:
- 合并C(1)和D(1)→新树权重2 ✨
- 合并B(2)和新树→权重4 🌟
- 最后合并A(3)→总权重7 🏆
3️⃣ 左0右1路径编码:
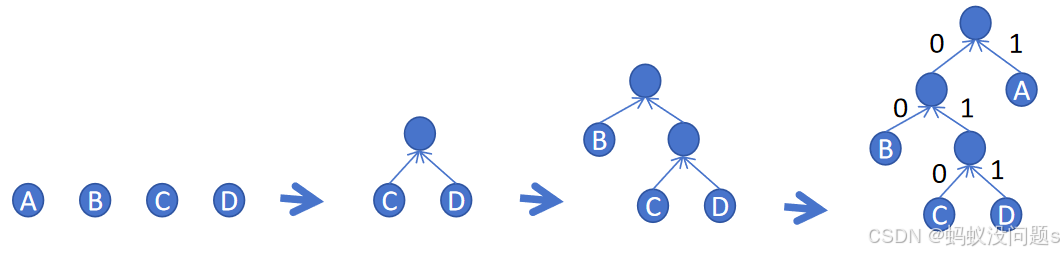
∴ A→1,B→00,C→010,D→011
💻 0x02 手撕代码 | Python实现+逐行注释
2.1 哈夫曼树节点类
class Node:
def __init__(self, char, freq):
self.char = char # 字符(仅叶子节点有效)
self.freq = freq # 频率
self.left = None # 左子节点 → 路径0
self.right = None # 右子节点 → 路径1
# 优先队列比较规则(总频率小的优先)
def __lt__(self, other):
return self.freq < other.freq
2.2 构建哈夫曼树
import heapq
def build_huffman_tree(text):
# 统计字符频率 📊
freq = {}
for char in text:
freq[char] = freq.get(char, 0) + 1
# 创建优先队列 🌟
heap = [Node(char, f) for char, f in freq.items()]
heapq.heapify(heap)
# 合并最小两节点 → 直到只剩一棵树 🌳
while len(heap) > 1:
left = heapq.heappop(heap)
right = heapq.heappop(heap)
merged = Node(None, left.freq + right.freq)
merged.left, merged.right = left, right
heapq.heappush(heap, merged)
return heap[0] # 返回根节点
2.3 生成编码表
def generate_codes(root, current_code="", codes={}):
if root is None:
return
# 叶子节点记录编码 🍃
if root.char is not None:
codes[root.char] = current_code
return
# 递归遍历左右子树 🔄
generate_codes(root.left, current_code + "0", codes)
generate_codes(root.right, current_code + "1", codes)
return codes
2.4 编码与解码实战
# 编码函数
def huffman_encode(text, codes):
return ''.join(codes[char] for char in text)
# 解码函数(需要哈夫曼树)
def huffman_decode(encoded_str, root):
current = root
decoded = []
for bit in encoded_str:
current = current.left if bit == '0' else current.right
if current.char: # 到达叶子节点
decoded.append(current.char)
current = root # 重置到根节点
return ''.join(decoded)
测试案例
text = "ABBCCCDDDD"
tree = build_huffman_tree(text)
codes = generate_codes(tree)
encoded = huffman_encode(text, codes) # 输出:01010110110111111110
decoded = huffman_decode(encoded, tree) # 成功还原原文本 🎉
🖼️ 0x03 实战案例 | 哈夫曼编码の高光时刻
案例1:卫星图像压缩
某卫星拍摄的32x32遥感图像,原始数据为:
RGB(255,0,0)重复100次 + RGB(0,255,0)重复50次 + ...
使用哈夫曼编码后:
- 红色→
0,绿色→10,蓝色→110... - 压缩率高达 60%,节省数百万美元存储成本 💰
案例2:PDF文档优化
一篇科研论文中有大量重复空格和换行符:
"\n\n "出现200次,普通编码占800字节
哈夫曼编码将其映射为111,仅需 200*3=600位=75字节,节省90%空间! 📑
案例3:游戏资源压缩
《Minecraft》中石块贴图数据:
stone_texture: 0x88重复1024次
RLE编码后为1024*0x88,哈夫曼进一步压缩为1 0x88,体积再减半! 🎮
⚖️ 0x04 优缺点分析 | 什么场景最适合它?
| 维度 | 优点 | 缺点 |
|---|---|---|
| 压缩率 | 接近香农极限,比定长编码优30%+ 🚀 | 需要预先统计频率表 📊 |
| 速度 | 解码速度极快(比特流直接解析)⏩ | 构建哈夫曼树较耗时 ⏳ |
| 适应性 | 可处理任意二进制数据 🔣 | 对非重复数据效果一般 😢 |
| 应用领域 | 文本/图像/音频的无损压缩 🌐 | 实时流媒体需配合其他算法 📡 |
适用场景推荐
✅ 医疗影像存储:必须无损且重复区域多
✅ 嵌入式设备:解码资源消耗低
✅ 历史档案数字化:长期保存需稳定性
🔮 0x05 扩展知识 | 哈夫曼の黑科技变种
-
自适应哈夫曼编码
动态更新频率表,适合网络流传输(如gzip)🌊 -
哈夫曼+游程编码(RLE)混合
先RLE处理重复序列,再用哈夫曼压缩,效果↑↑↑ 💥 -
分层哈夫曼编码
将数据分块处理,支持并行压缩(如JPEG)🔀 -
量子哈夫曼编码
用量子位表示编码,理论压缩率突破经典极限 🚀


















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











