







【摘要】我们研究拍卖机制以支持人工智能生成内容的新兴格式。我们特别研究如何以激励兼容的方式聚合多个法学硕士。在这个问题中,每个代理对随机生成的内容的偏好被描述/编码为 LLM。一个关键动机是为人工智能生成的广告创意设计一种拍卖格式,以结合不同广告商的输入。我们认为,这个问题虽然通常属于机制设计的范畴,但具有几个独特的特征。我们提出了一种通用形式主义——代币拍卖模型——来研究这个问题。该模型的一个关键特征是,它在逐个令牌的基础上起作用,并让 LLM 代理通过单维出价影响生成的内容。我们首先探索一种稳健的拍卖设计方法,其中我们假设代理偏好需要结果分布的偏序。我们制定了两个自然激励属性,并证明它们等价于分布聚合的单调性条件。我们还表明,对于此类聚合函数,尽管没有投标人估值函数,但仍可以设计第二价格拍卖。然后,我们通过关注基于 KL 散度(LLM 中常用的损失函数)的特定评估形式来设计具体的聚合函数。福利最大化聚合规则是所有参与者的目标分布的加权(对数空间)凸组合。我们得出支持代币拍卖公式的实验结果。
原文:Mechanism Design for Large Language Models
地址:https://arxiv.org/abs/2310.10826
代码:无
出版: WWW 2024
机构:Google等
1 研究问题
本文研究的核心问题是: 如何设计一个机制,将多个大语言模型(LLMs)生成的内容以激励相容的方式聚合起来,特别是在广告创意生成的场景中。
假设有两家广告商,一家是夏威夷的Stingray度假村,另一家是Maui航空公司。它们各自训练了一个LLM来生成广告词。问题是如何设计一个机制,激励两家广告商据实报告自己的LLM模型,并基于此生成一则同时包含两家元素的创意广告。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
LLM作为生成模型,其偏好隐含在文本概率分布中,难以显式表达和比较。例如有两个LLM分别对三个token (A, B, C)的生成概率分布为(0.5, 0.3, 0.2)和(0.4, 0.4, 0.2)。现在如果聚合结果是(0.6, 0.3, 0.1),我们很难直接判断这个结果对于哪个LLM更有利。虽然第一个LLM对token A的偏好更高,但第二个LLM对token B的偏好更高。由于缺乏一个公共的效用尺度,我们无法简单地说(0.6, 0.3, 0.1)是否比(0.5, 0.4, 0.1)更偏向第一个LLM。
-
LLM生成内容具有随机性,难以用传统的确定性机制设计范式建模。比如LLM在相同的输入下,第一次运行产生了文本"I love apples",第二次运行产生了文本"I like apples"。
-
聚合机制要与LLM的推理特点相适应,不引入额外复杂度。当前主流的LLM如GPT-3采用的是autoregressive的生成方式,即每次根据前面已生成的token序列,预测下一个最可能的token。一个自然的聚合方式是将多个LLM对下一个token的概率预测做加权平均,而不是等到每个LLM生成完整的句子再去聚合,因为后者会引入大量的额外计算。
-
LLM推理成本高,聚合过程要尽量减少对其调用次数。理想的聚合机制应该以最少的LLM调用次数,实现对代理偏好的良好表征和激励相容。
针对这些挑战,本文提出了一种简洁而巧妙的"代币拍卖"思路:
将多个LLM的聚合过程建模为代理在每一步对下一个"token"的条件概率分布进行竞价。首先,这种做法完全符合LLM的autoregressive生成范式,不需要对原有模型做任何修改。其次,通过聚焦每一步的决策,它将整个文本空间的偏好表达问题转化为对单个token的偏好表达,大大简化了偏好的呈现方式。再次,通过引入连续的出价,它将原本离散、高维的概率分布空间映射到了单一的实数空间,为博弈分析提供了便利。最后,通过巧妙的激励相容机制设计,它实现了用最少的偏好询问就能达到激励相容的理想目标。本文理论分析表明,若聚合函数满足一定的单调性条件,再搭配二价格支付规则,就能确保在广义的偏好结构下实现激励相容。进一步地,如果代理的效用函数形式已知(如基于KL散度或强化学习奖励),还可以设计出最大化社会福利的最优聚合方案。
2 研究方法
论文提出了一种名为Token Auction的机制设计方法,用于以激励相容的方式聚合多个大语言模型(LLM)的输出。接下来我们详细介绍该方法的理论基础和关键技术。
2.1 Token Auction模型
Token Auction模型描述了如何将多个LLM生成的token概率分布聚合成一个分布,并确定每个LLM获得的支付。形式化地,假设有 个LLM,第 个LLM的生成函数为 ,将token序列 映射为下一个token的概率分布 。Token Auction机制由两部分组成:
-
聚合函数 将 个LLM的出价 和概率分布 映射为一个聚合分布。
-
支付函数 确定第 个LLM获得的支付金额。
直观上,每个LLM通过出价 来影响聚合函数的输出分布,同时支付一定金额。Token Auction的目标是设计 和 ,使得机制满足一定的激励相容性。
2.2 理想激励属性
为了使Token Auction机制具有良好的激励性质,论文提出了两个理想属性:
-
Payment Monotonicity: 对于同一个LLM,如果出价更高,则当且仅当聚合分布更接近其理想分布时,LLM支付的金额才会更高。形式化地,对任意 ,有
其中 表示LLM 的偏好关系。
-
Consistent Aggregation: 对于同一个LLM,如果在某个出价下聚合分布优于另一个出价,则对其他LLM的任意出价,这一优势关系都成立。形式化地,如果对某个 有 ,则对任意 都有 。
这两个性质保证了LLM无法通过操纵出价获得更优的聚合分布和更低的支付。
2.3 单调聚合函数
论文证明,满足以上两个理想属性的Token Auction机制等价于采用单调聚合函数。单调聚合函数的定义为:对任意 ,有
也就是说,在其他LLM出价不变时,第 个LLM出价越高,聚合分布就越接近其理想分布。论文举例说明,线性加权聚合函数
满足单调性,而log-linear加权聚合函数
不满足单调性。
2.4 稳定采样和二价支付
为了给单调聚合函数设计合适的支付机制,论文引入了稳定采样的概念。直观上,稳定采样将随机变量 和出价 映射为一个确定的token ,且满足:
-
当 较低时总是选择LLM 不太喜欢的token;
-
当 超过某个阈值后就转而选择LLM 更喜欢的token。
形式化地,令 和 分别表示LLM 偏好和不偏好的token集合。如果对任意 都存在 使得
则称映射 是关于聚合函数 的稳定采样。论文证明,任何单调聚合函数都存在一个稳定采样。
基于稳定采样,论文提出了一种类似于二价拍卖的支付机制:当LLM 的出价使得采样从 转变为 时,其支付等于临界出价 ,否则支付为0。该机制具有支付单调性,且支付函数可写为聚合分布 和理想分布 之间总变差距离关于出价 的积分形式:
2.5 基于损失函数的聚合方法
论文进一步探讨了如何基于LLM训练中的损失函数来设计聚合函数 。首先回顾LLM的训练流程,通常包括三个阶段:
-
在通用语料上进行预训练,优化KL散度损失
-
在特定任务数据上进行微调,同样优化KL散度损失。
-
通过人类反馈进行强化学习,优化奖励函数 和KL散度正则项的组合
受预训练阶段优化目标的启发,论文提出了一种基于KL散度的线性加权聚合函数
并证明它最大化了社会福利函数
类似地,基于强化学习阶段的优化目标,论文提出了log-linear加权聚合函数
它最大化了另一个形式的社会福利
值得注意的是,线性加权聚合满足单调性,因此可以搭配2.4节中的二价支付机制,而log-linear加权聚合虽然不满足单调性,但在LLM的偏好与KL散度一致时也是一个合理的选择。
综上,Token Auction机制提供了一套系统的方法来聚合多个LLM的输出,并以激励相容的方式确定对各方的支付。论文在理论上分析了满足理想激励属性的充要条件,提出了稳定采样和二价支付的实现方案,并根据LLM训练中的优化目标设计了两种具体的聚合函数。这些方法对于构建更加通用和高效的LLM应用具有重要的指导意义。
3 实验效果
为了验证所提出的token auction机制,论文通过prompt-tuning一个公开的LLM模型进行了实验。
3.1 实验设置
论文模拟了两个虚构的广告客户,"Alpha Airlines"和"Beta Resort",他们希望围绕"Hawaii"这个共同主题投放广告。为了最小化LLM可能产生的幻觉,论文特意选择了"Alpha"和"Beta"这两个本身并无太多意义的品牌名称。
实验流程如下:首先,对于每个广告客户,论文设计了一个prompt来定制化基础LLM模型。这里的关键是通过改变prompt而非重新训练模型参数来适应不同客户,这大大降低了计算开销。其次,论文实现了第4节提出的线性组合和log-linear组合两种aggregation函数,并将其整合到LLM的推理过程中。最后,通过改变两个广告客户的出价比值λ (λ=b1/(b1+b2))来观察生成文本的变化。
3.2 实验结果
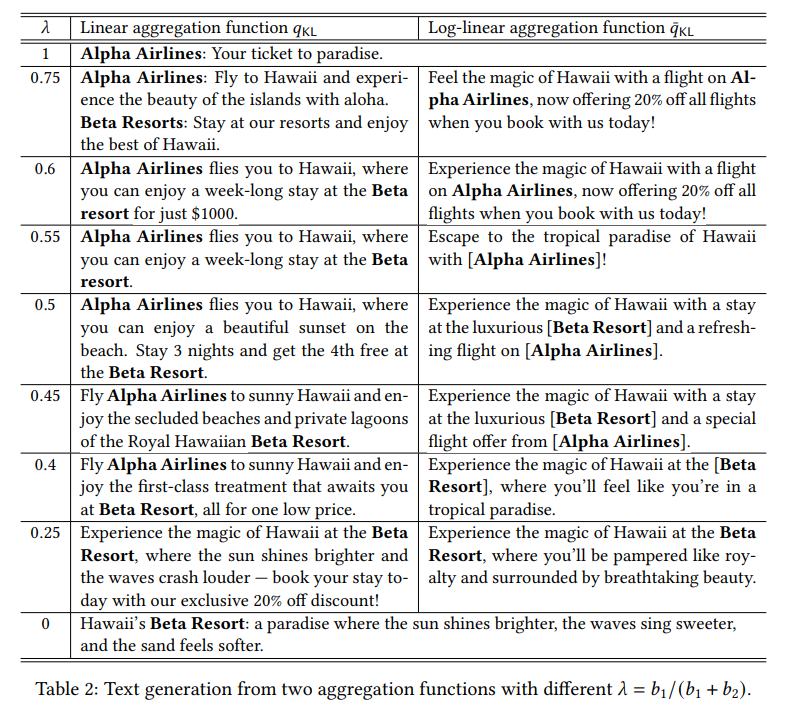
表2展示了两种aggregation方法在不同λ值下的生成文本。可以看到,随着λ从1变化到0,生成文本大致遵循"仅Alpha Airlines → 同时包含两者 → 仅Beta Resort"的变化规律。这符合预期,因为λ从1变化到0对应着b2从0增加到无穷大(或者b1从无穷大减小到0)。值得注意的是,两种aggregation方法的模式转换阈值略有不同。如表2所示,线性组合方法在λ=0.75和λ=0.4时发生转换,而log-linear组合方法的转换点是λ=0.5和λ=0.45。这表明log-linear组合可能对出价比值λ更敏感一些。从生成文本的质量来看,虽然使用的是通用LLM模型,两种方法生成的广告词都是有意义且易于理解的。在合适的λ值下(如0.5左右),模型能够生成高质量的联合广告文案(如表2第5行所示)。这展现了LLM在广告文案生成任务上的强大能力和灵活性。
论文指出,如果针对特定任务进行微调,生成文本的质量还有进一步提升的空间。总的来说,实验结果验证了token auction机制的有效性,为联合广告文案的自动生成提供了一种可能的技术路径。
4 总结后记
本论文针对多个大语言模型(LLM)的激励相容聚合问题,提出了一种基于token的拍卖机制(token auction)。通过线性组合和log-linear组合两种aggregation函数,实现了根据不同广告客户的出价比例生成相应的联合广告文案。实验结果表明,所提机制能够以一种平滑、可解释的方式实现多个LLM的聚合,为自动生成广告创意提供了新的思路。
疑惑和想法
-
除了token-level的建模,是否可以设计出其他粒度(如phrase-level、sentence-level)的机制?
-
除了线性组合和log-linear组合,是否存在其他形式的高效aggregation函数?它们在理论性质和实践效果上有何区别?
-
如何将token auction机制与LLM的微调方法相结合,进一步提升生成质量?
可借鉴的方法点:
-
Token-level的建模和优化方法可以推广到其他需要聚合多个LLM的场景,如对话系统、文本改写等。
-
将机制设计与LLM的推理过程相结合的思想值得借鉴,可以设计出更多形式的"即插即用"机制。
-
通过prompt engineering来适配不同需求,避免重复训练模型的思路可以广泛应用,提高LLM的实用性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









