







原文:Learning Personalized Causally Invariant Representations for Heterogeneous Federated Clients
地址:https://openreview.net/forum?id=8FHWkY0SwF
代码:未知
出版:ICLR 2024
机构: 香港理工大学、香港科技大学
解读:“码农的科研笔记”公众号
1 研究问题
本文研究的核心问题是: 如何在个性化联邦学习中解决捷径学习问题,提高模型在异构联邦客户端上的泛化能力。
::: block-1
假设有一个医疗联邦学习系统,涉及多家医院。每家医院都有自己的本地数据集,但由于各医院的设备、病患群体等因素不同,数据分布存在差异。传统的个性化联邦学习方法可能会学习到一些表面上有效但实际上不可靠的特征(如图像背景),导致模型在面对新的测试数据时表现不佳。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 联邦学习中数据分布异构性与捷径学习问题的结合,使得模型泛化性能下降
- 现有个性化联邦学习方法忽视了捷径陷阱问题,无法保证模型在分布外数据上的表现
- 直接将集中式不变学习方法应用到联邦学习中会消除所有异构特征,包括有用的个性化信息
- 联邦学习中每个客户端的训练环境有限,难以直接应用需要多个环境的不变学习方法
针对这些挑战,本文提出了一种基于因果推断的"联邦捷径发现与移除(FedSDR)"方法:
::: block-1
FedSDR的核心思想是将捷径特征发现和移除分为两个阶段。在第一阶段,利用所有客户端的训练数据协作发现捷径特征。这基于一个因果推断得出的重要发现:捷径特征在给定标签和环境的条件下与客户端指示器独立。这使得即使在异构数据上也能有效识别捷径特征。在第二阶段,每个客户端利用发现的捷径特征来提取最具信息量的不变特征,从而得到最优的个性化不变预测器。这一过程类似于医生在诊断时,首先识别出可能误导判断的表面症状(如由设备引起的伪影),然后专注于真正相关的临床指标,最终根据每个病人的具体情况给出个性化的诊断结果。
:::
2 研究方法
2.1 结构因果模型分析
为了解决个性化联邦学习(PFL)中的捷径陷阱问题,论文首先提出了一个适用于联邦学习环境的结构因果模型(SCM)。这个模型描述了异构客户端的数据生成机制,为后续的捷径发现和移除方法奠定了理论基础。
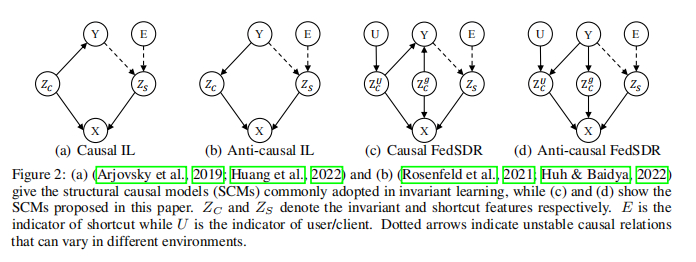
具体来说,论文考虑了因果和反因果两种情况的SCM,如图2©和2(d)所示。在这个模型中, Y Y Y表示标签, Z S Z_S ZS表示捷径特征, Z C U Z_C^U ZCU表示个性化不变特征, Z C g Z_C^g ZCg表示全局共享的不变特征, E E E表示环境指示符, U U U表示用户/客户端指示符, X X X表示观察到的输入。
举个例子,在牛和骆驼的分类任务中, Y Y Y可以是动物类别(牛或骆驼), Z S Z_S ZS可能是背景信息(草地或沙漠), Z C U Z_C^U ZCU可能是某个客户端特有的拍摄角度或光照条件, Z C g Z_C^g ZCg可能是动物的形状特征, E E E可能表示不同的拍摄地点, U U U表示不同的客户端, X X X则是最终观察到的图像。
基于这个SCM,论文导出了两个关键的因果特征:
- Z S ⊥⊥ U ∣ Y , E Z_S ⊥⊥ U | Y, E ZS⊥⊥U∣Y,E : 这意味着捷径特征 Z S Z_S ZS与个性化指标 U U U在给定标签 Y Y Y和环境 E E E的条件下是独立的。
- Z C g ⊥⊥ Z S ∣ Y Z_C^g ⊥⊥ Z_S | Y ZCg⊥⊥ZS∣Y 和 $Z_C^U ⊥⊥ Z_S | Y : 这表示全局不变特征 : 这表示全局不变特征 :这表示全局不变特征Z_Cg$和个性化不变特征$Z_CU 都与捷径特征 都与捷径特征 都与捷径特征Z_S 在给定标签 在给定标签 在给定标签Y$的条件下是独立的。
这两个特征为后续的捷径发现和移除方法提供了理论支持。直觉上,第一个特征告诉我们,即使在异构的客户端环境中,我们仍然可以通过协作的方式发现捷径特征。第二个特征则暗示了我们可以通过消除与捷径特征的依赖关系来获得真正的不变特征。
2.2 可证明的捷径发现方法
基于上述SCM分析,论文设计了一个可证明的捷径发现方法。这个方法的核心思想是通过优化一个特定的目标函数,在联邦学习框架下协作发现完整的捷径特征。具体来说,捷径发现的目标函数如下:
ω Ψ ∗ , Ψ ∗ = arg min Ψ : X → H , ω : H → Y 1 N ∑ u = 1 N { ℓ S D u ( Ψ ; D u ) : = R ( ω ( Ψ ) ; D u ) − λ ℓ d i s ( Ψ ; D u ) } \omega_\Psi^*, \Psi^* = \arg\min_{\Psi:X \rightarrow H, \omega:H\rightarrow Y} \frac{1}{N} \sum_{u=1}^N \{\ell_{SD}^u(\Psi; D^u) := R(\omega(\Psi); D^u) - \lambda \ell_{dis}(\Psi; D^u)\} ωΨ∗,Ψ∗=argΨ:X→H,ω:H→YminN1u=1∑N{ℓSDu(Ψ;Du):=R(ω(Ψ);Du)−λℓdis(Ψ;Du)}
其中, Ψ \Psi Ψ是捷径特征提取器, ω \omega ω是分类器, N N N是客户端数量, D u D^u Du是第 u u u个客户端的数据集, λ \lambda λ是平衡权重。
这个目标函数包含两个主要部分:
- R ( ω ( Ψ ) ; D u ) R(\omega(\Psi); D^u) R(ω(Ψ);Du): 这是一个经验风险项,用于确保提取的特征对分类任务是有用的。
- ℓ d i s ( Ψ ; D u ) \ell_{dis}(\Psi; D^u) ℓdis(Ψ;Du): 这是一个差异项,用于最大化不同环境下特征分布的差异。
具体来说, ℓ d i s \ell_{dis} ℓdis定义如下:
ℓ d i s ( Ψ , D u ) : = E X ∈ D u [ ∑ e i ∈ E t r ∑ e j ∈ E t r K L ( P ω i ∗ ( Y ∣ Ψ ( X ) , e i ) ∣ ∣ P ω j ∗ ( Y ∣ Ψ ( X ) , e j ) ) ] \ell_{dis}(\Psi, D^u) := E_{X\in D^u} [\sum_{e_i \in E_{tr}} \sum_{e_j \in E_{tr}} KL(P_{\omega_i^*}(Y | \Psi(X), e_i) || P_{\omega_j^*}(Y | \Psi(X), e_j))] ℓdis(Ψ,Du):=EX∈Du[ei∈Etr∑ej∈Etr∑KL(Pωi∗(Y∣Ψ(X),ei)∣∣Pωj∗(Y∣Ψ(X),ej))]
这里,KL表示KL散度,用于衡量不同环境下条件分布的差异。
这个设计的直觉是:真正的捷径特征在不同环境下应该表现出显著的差异,而不变特征在不同环境下应该保持相对稳定。
举个例子,在牛和骆驼的分类任务中,如果背景(草地/沙漠)是捷径特征,那么基于背景的分类器在不同环境(如草原环境和沙漠环境)下的表现会有很大差异。相比之下,基于动物形状的分类器在不同环境下的表现应该相对一致。
论文证明,在满足一定条件下(如线性情况和环境数量充足),这个目标函数的最优解 Ψ ∗ \Psi^* Ψ∗恰好能提取出完整的捷径特征。这就是"可证明的捷径发现"的含义。
2.3 个性化不变学习与捷径移除
在发现捷径特征之后,下一步是设计一个方法来移除这些捷径特征,并学习个性化的不变特征。论文提出了以下目标函数:
ω u ∗ ( Φ u ∗ ) = arg min Φ u , ω u ℓ S R u ( ω u ( Φ u ) ; D u ) : = { R ( ω u ( Φ u ) ; D u ) + γ ⋅ I ( Φ u ; Ψ ∗ ∣ Y ) } , ∀ u ∈ [ N ] \omega_u^*(\Phi_u^*) = \arg\min_{\Phi_u, \omega_u} \ell_{SR}^u(\omega_u(\Phi_u); D^u) := \{R(\omega_u(\Phi_u); D^u) + \gamma \cdot I(\Phi_u; \Psi^* | Y)\}, \forall u \in [N] ωu∗(Φu∗)=argΦu,ωuminℓSRu(ωu(Φu);Du):={R(ωu(Φu);Du)+γ⋅I(Φu;Ψ∗∣Y)},∀u∈[N]
这个目标函数包含两个主要部分:
- R ( ω u ( Φ u ) ; D u ) R(\omega_u(\Phi_u); D^u) R(ωu(Φu);Du): 这是一个经验风险项,用于确保学到的特征对分类任务是有用的。
- I ( Φ u ; Ψ ∗ ∣ Y ) I(\Phi_u; \Psi^* | Y) I(Φu;Ψ∗∣Y): 这是一个条件互信息项,用于确保学到的特征 Φ u \Phi_u Φu与捷径特征 Ψ ∗ \Psi^* Ψ∗在给定标签Y的条件下是独立的。
直觉上,这个目标函数试图学习一个既能很好地完成分类任务,又与捷径特征无关的特征表示。举个例子,在牛和骆驼的分类任务中,这个目标函数会鼓励模型学习动物的形状特征(这对分类很有用),同时避免依赖于背景信息(这是之前发现的捷径特征)。
论文证明,当 γ \gamma γ选择适当时,这个目标函数的最优解就是理想的个性化不变预测器。具体来说,它满足以下性质:
- 它是对给定客户端最有信息量的特征(通过最小化经验风险实现)。
- 它与捷径特征无关(通过最小化条件互信息实现)。
- 它在不同环境下是不变的(这是由1和2共同保证的)。
值得注意的是,这个方法允许每个客户端学习自己的个性化不变特征,这比学习一个全局共享的不变特征更灵活,能更好地适应客户端的特定数据分布。
2.4 联邦学习算法设计
为了在联邦学习框架下实现上述方法,论文设计了一个迭代算法,包括服务器更新和客户端更新两个主要步骤。
服务器更新:
- 初始化模型参数。
- 在每轮通信中,选择一部分客户端并向它们发送当前的捷径提取器 Ψ t \Psi^t Ψt和环境分类器 { ω i t } \{\omega_i^t\} {ωit}。
- 接收选中客户端的本地更新。
- 聚合更新,得到新的全局捷径提取器和环境分类器。
客户端更新:
- 初始化个性化不变模型。
- 接收服务器发送的全局模型。
- 更新个性化不变模型:
f θ u t , k + 1 = f θ u t , k − η ∇ ℓ S R u ( f θ u t , k ; D u ) f_{\theta_u}^{t,k+1} = f_{\theta_u}^{t,k} - \eta\nabla\ell_{SR}^u(f_{\theta_u}^{t,k}; D^u) fθut,k+1=fθut,k−η∇ℓSRu(fθut,k;Du) - 更新本地捷径提取器:
Ψ u t , r + 1 = Ψ u t , r − β ∇ ℓ S D u ( Ψ u t , r ; D u ) \Psi_u^{t,r+1} = \Psi_u^{t,r} - \beta\nabla\ell_{SD}^u(\Psi_u^{t,r}; D^u) Ψut,r+1=Ψut,r−β∇ℓSDu(Ψut,r;Du) - 更新本地环境分类器。
- 将更新后的模型参数上传到服务器。
这个算法设计允许客户端在本地数据上学习个性化的不变特征,同时通过服务器的聚合来协作发现全局的捷径特征。这种设计既保证了个性化,又利用了联邦学习的优势。例如,在牛和骆驼的分类任务中,每个客户端可能有不同的拍摄风格或特定的场景。通过这个算法,它们可以学习到适合自己数据分布的不变特征(如特定角度下的动物形状特征),同时通过与其他客户端的协作,共同识别出全局的捷径特征(如背景信息)。
值得注意的是,论文还讨论了如何将这个方法与现有的联邦学习和个性化联邦学习方法结合。例如,可以将捷径移除作为一个正则化项添加到现有方法的目标函数中,从而提高它们在分布外(OOD)数据上的泛化性能。总的来说,这个算法设计巧妙地结合了联邦学习的协作优势和个性化学习的灵活性,为解决联邦学习中的捷径陷阱问题提供了一个有效的框架。
3 实验
3.1 实验场景介绍
本论文提出了一种新的个性化联邦学习方法FedSDR,旨在解决异构联邦客户端中的捷径学习问题。实验主要验证FedSDR在不同数据集上的性能,以及与现有方法的对比。实验场景包括图像分类任务,其中存在捷径特征(如背景颜色或环境),这些特征在训练数据中与标签高度相关,但在测试数据中可能变化。
3.2 实验设置
- Datasets:
- Colored-MNIST (CMNIST)
- Colored Fashion-MNIST (CFMNIST)
- WaterBird
- PACS
- Baselines:
- 联邦学习方法:FedAvg, DRFA, FedSR, FedIIR
- 个性化联邦学习方法:pFedMe, Ditto, FTFA, FedRep, FedRoD, FedPAC
- Implementation details:
- 模型:CMNIST和CFMNIST使用带一个隐藏层的深度神经网络,WaterBird和PACS使用ResNet-18
- 联邦学习设置:8个客户端(PACS使用6个客户端)
- 训练环境:每个客户端只有一个训练环境
- Metrics:
- 最坏情况测试准确率
- 平均测试准确率
- 环境:使用PyTorch实现,在配备NVIDIA GeForce RTX 3090 GPU的深度学习工作站上进行模拟
3.3 实验结果
实验1、性能比较
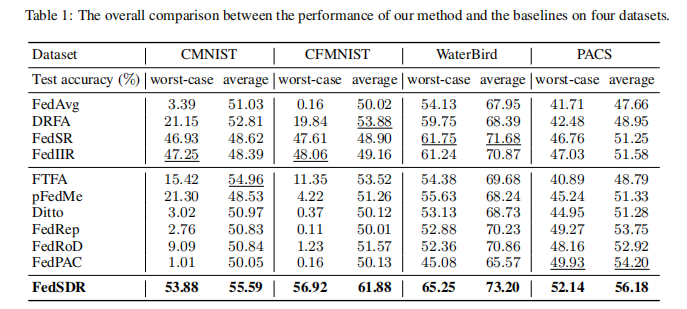
目的:比较FedSDR与其他基线方法在四个数据集上的性能
涉及图表:表1、图3
实验细节概述:在CMNIST, CFMNIST, WaterBird和PACS数据集上评估FedSDR和基线方法的性能,比较最坏情况和平均测试准确率
结果:
- FedSDR在所有数据集上都取得了最佳的最坏情况和平均测试准确率
- 在CMNIST, CFMNIST, WaterBird和PACS上,FedSDR分别比第二好的方法提高了约6.5%, 9%, 3.5%和2%的最坏情况准确率
实验2、捷径特征消除的有效性
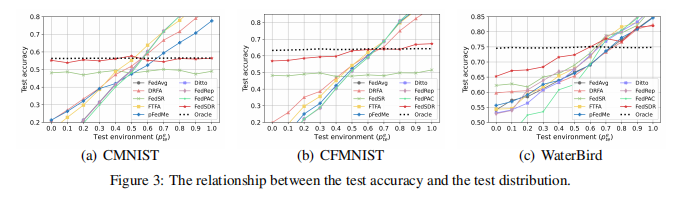
目的:评估FedSDR在消除捷径特征方面的有效性
涉及图表:图3
实验细节概述:在CMNIST, CFMNIST和WaterBird数据集上,分析测试准确率与测试分布之间的关系
结果:
- FedSDR能够有效消除捷径特征,在不同测试分布上保持较为一致的准确率
- 相比大多数FL和PFL方法,FedSDR的测试准确率曲线更接近理想的"Oracle"方法
实验3、捷径发现和消除的必要性
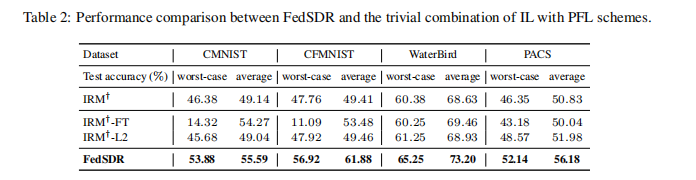
目的:验证简单结合不变学习(IL)和个性化联邦学习(PFL)的方法的局限性
涉及图表:表2
实验细节概述:比较FedSDR与IRM结合微调(IRM†-FT)和L2正则化(IRM†-L2)的性能
结果:
- 简单结合IL和PFL的方法难以提高OOD泛化性能
- 本地微调甚至可能降低性能
- FedSDR在最坏情况和平均测试准确率上都优于这些组合方法
实验4、超参数影响
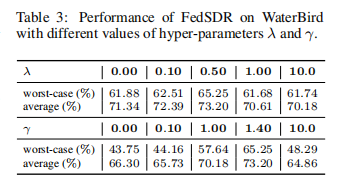
目的:分析超参数λ和γ对FedSDR性能的影响
涉及图表:表3
实验细节概述:在WaterBird数据集上,使用不同的λ和γ值评估FedSDR的性能
结果:
- FedSDR对γ的选择比λ更敏感
- 当λ=0时,捷径特征提取器通过经验风险最小化训练
- 当γ=0时,个性化模型通过本地ERM训练
这些实验结果表明,FedSDR在处理异构联邦客户端中的捷径学习问题上具有显著优势,能够有效提高模型在不同分布上的泛化性能。
根据您的要求,我将对论文进行总结和分析:
4 总结后记
本论文针对个性化联邦学习(PFL)中的捷径陷阱问题,提出了一种联邦捷径发现与消除方法(FedSDR)。通过构建异构客户端的结构因果模型,设计了协作式捷径特征发现和基于个性化因果不变表示的捷径消除方法。实验结果表明,所提方法能有效缓解捷径学习问题,在多个数据集上实现了更好的分布外(OOD)泛化性能。
::: block-2
疑惑和想法:
- 除了线性情况下的理论保证,是否可以扩展到更复杂的非线性场景?
- 在实际应用中,如何平衡捷径消除和保留有用的个性化信息?
- FedSDR方法是否可以与其他先进的联邦学习技术(如差分隐私、安全多方计算等)结合使用?
- 如何处理动态变化的捷径特征,使方法能够适应环境的变化?
:::
::: block-2
可借鉴的方法点:
- 利用结构因果模型分析异构数据生成机制的思路可以推广到其他分布式学习场景。
- 将捷径发现和消除分为两个阶段的设计思路值得借鉴,可以应用到其他需要处理数据偏差的任务中。
- 通过因果不变表示来提高模型的OOD泛化性能的方法可以尝试应用于其他机器学习任务。
- 将不变学习与个性化学习相结合的思路可以启发其他领域的研究,如迁移学习、元学习等。
:::

















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









