







【摘要】推理是语言理解的基本组成部分。最近的提示技术,如思维链,持续改善了逻辑推理硕士在各种推理任务中的表现。然而,在推理阶段是什么触发了逻辑思维模式的推理能力,这一点仍然鲜为人知。在本文中,我们介绍了代码提示,这是一个提示链,可以将自然语言问题转换为代码,并使用生成的代码直接提示LLM,而无需借助外部代码执行。我们假设代码提示可以引出对文本和代码进行训练的LLM的某些推理能力,并利用所提出的方法来改进条件推理,即根据特定条件的满足情况推断不同结论的能力。我们发现,在多个条件推理数据集上,代码提示对多个LLM表现出了高性能提升(在GPT 3.5上提升了22.52个百分点,在Mixtral上提升了7.75个百分点,在Mistral上提升了16.78个百分点)。然后,我们进行了全面的实验,以了解代码提示是如何触发推理能力的,以及哪些能力是在底层模型中引发的。我们对GPT 3.5的分析表明,输入问题的代码格式对性能改进至关重要。此外,代码提示提高了上下文学习的样本效率,并有助于变量或实体的状态跟踪。
原文:Code Prompting Elicits Conditional Reasoning Abilities in Text+Code LLMs
地址:https://arxiv.org/abs/2401.10065
代码:https://github.com/UKPLab/arxiv2024-conditional-reasoning-llms
出版:未知
机构:UKP Lab等
1 研究问题
本文研究的核心问题是:如何使用代码提示(code prompting)来触发大型语言模型(LLMs)中的条件推理能力。
假设我们有一个法律咨询机器人,它使用大型语言模型来回答用户的法律问题。面对一个问题"我丈夫去世了,他的遗产该如何处理?",机器人需要根据多个条件推理出答案,比如是否有遗嘱、是否超过法定继承人范围等。如何通过提示让语言模型更好地进行这种复杂的条件推理,是一个具有实际意义的问题。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
现有的通过文本提示(text prompting)来触发LLMs推理能力的方法在面对复杂的条件推理任务时效果有限。这可能是因为自然语言的表达具有模糊性和歧义性,不利于LLMs清晰地识别出需要进行推理的条件。
-
代码具有语法严谨、逻辑清晰的特点,理论上更有利于触发和引导LLMs进行逻辑推理。然而目前尚无研究系统地探索代码提示在触发LLMs条件推理能力方面的潜力。
-
需要设计一种自然语言到代码的转换方法,在保留原始问题语义的同时,用代码的形式明确表达出隐含的条件逻辑,为后续的条件推理铺平道路。这种语义到逻辑的映射并非易事。
-
希望提出的方法是端到端的,即不依赖外部程序来执行生成的代码,以排除其他因素的干扰,单纯评估代码提示对LLMs推理能力的影响。这就要求生成的代码逻辑清晰、信息完备,能被LLMs"理解"和"执行"。
针对这些挑战,本文提出了一种灵活多变的"代码提示"方法:
它的核心思想是将自然语言问题转化为Python风格的伪代码,然后用这段代码作为提示请LLMs生成最终答案。这段伪代码起到将自然语言映射到编程逻辑的桥梁作用。一方面,代码中的注释部分保留了原始的自然语言描述,确保了语义信息不流失。另一方面,代码的语法结构明确表达了蕴含的条件逻辑,如if语句对应着不同情形下的推理路径。值得一提的是,本文精心设计了代码的表示形式,如用snake case风格的变量名代表问题中的关键实体,布尔类型变量表征命题真假,巧妙地将语言符号和编程符号统一起来。此外,生成的代码不需要是可执行的,因为目的不是让LLMs"运行"代码,而是通过代码形式来引导LLMs进行类似的逻辑推理。这种灵活的设计减轻了对生成代码质量的要求,扩大了方法的适用性。借助少样本学习中的prompt engineering技术,本文用极少的样例就让LLMs学会了这种代码提示范式,可以自动地将新问题转换为对应的代码提示。
2 研究方法

2.1 代码提示的定义与特点
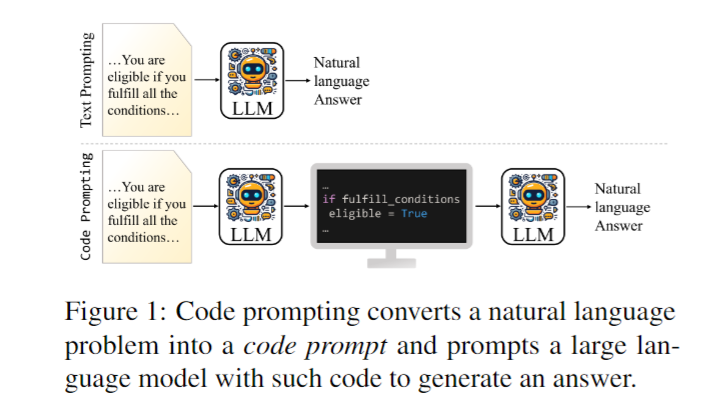
代码提示(Code Prompting)是指将自然语言(NL)问题转化为类似编程语言的伪代码形式,然后将这段代码作为提示输入给语言模型,请其生成最终答案的方法。形式上,代码提示由两部分组成:(1)注释中保留的原始NL描述;(2)代码语句体现的隐含逻辑关系,特别是条件推理逻辑。图1展示了一个NL问题转化为代码提示的例子。
代码提示有以下几个显著特点:
-
巧妙地利用了编程语言的语法结构来明确表达NL问题中暗含的条件逻辑。例如,用if语句来表示不同情形下的推理路径。这种将语义信息映射到代码逻辑的做法,有助于语言模型进行更准确的推理。
-
生成的代码不要求是可执行的,因为其目的是引导语言模型进行类似的逻辑推理过程,而非让模型真正"运行"代码。这一点减轻了对生成代码质量的要求,使得代码提示方法更容易实现和应用。
-
在代码的注释部分最大限度地保留了原始NL问题的语义信息。由于代码的简洁性,一些细节信息难免会在转化过程中丢失。保留NL形式的问题描述,可以帮助语言模型更全面地理解问题,从而给出更准确的答案。
2.2 代码的语法设计
论文在将NL问题转化为代码时,主要用到了以下编程语言元素:
-
变量:论文采用下划线命名法(如
husband_pass_away)来定义变量,每个变量对应于问题中的一个关键实体或命题。 -
布尔类型:论文用布尔类型的变量(
True/False)来表示命题或条件的真假值。 -
If语句:论文用if语句来表达问题中蕴含的条件推理逻辑,不同的if分支对应不同情形下的推理路径。
这些语法元素的选择遵循了以下原则:(1)能清晰地表达问题的逻辑结构;(2)接近自然语言的表达习惯;(3)易于语言模型理解和生成。论文之所以选择类Python语法,正是因为其简洁、易读的特点,且广泛用于人工智能领域。
下面是一个用上述语法元素表示的完整代码提示例子:
# John wants to know if he is eligible for parental leave.
# John's wife Mary passed away 1 year ago.
wife_pass_away = True
wife_pass_away_years = 1
# John and Mary have a child together who is 5 years old.
has_child_together = True
child_age = 5
# To be eligible for parental leave, the child must be under 18
# and the spouse must have passed away within the last 3 years.
if has_child_together and child_age < 18 and wife_pass_away and wife_pass_away_years <= 3:
eligible_parental_leave = True
else:
eligible_parental_leave = False
2.3 训练语言模型进行代码提示
论文在三个条件推理任务数据集上评估了代码提示方法的有效性,分别是:
-
ConditionalQA:含有复杂规则和条件的阅读理解问题。
-
BoardgameQA:棋盘游戏规则的推理问题。
-
ShARC:以对话形式进行规则理解的问答数据集。
实验使用了三种不同规模的语言模型:GPT-3.5(1750亿参数)、Mixtral(47亿参数)和Mistral(70亿参数),它们都在自然语言和代码语料上进行了预训练。
为了让语言模型掌握代码提示的范式,论文采用了prompt engineering的少样本学习方法。具体而言,给定一个新的NL问题,论文构造一个由系统提示(system prompt)和若干演示样例(demonstrations)组成的prompt。其中:
-
系统提示说明了将NL问题转化为代码的任务要求。
-
演示样例提供了3个NL问题转化为代码提示的具体案例。
语言模型在编码新问题时,会参考系统提示和演示样例,模仿其中的转化模式,从而将新问题也表示为合适的代码形式。
论文使用精确匹配(Exact Match)、F1等指标来评估模型生成答案的准确性。同时,论文还考察了代码提示相比传统的文本提示方法能带来多大的性能提升。
3 实验
3.1 实验场景介绍
本文聚焦于如何通过代码提示(code prompting)的方式来触发大型语言模型中的条件推理能力。实验场景主要涉及法律、公共政策等领域的问答任务,需要模型根据给定的背景信息和规则,推理出问题的答案。例如,在ConditionalQA数据集中,有这样一个问题:"我丈夫去世了,他的遗产该如何处理?"。要回答这个问题,模型需要考虑遗嘱、法定继承人等多个条件,进行复杂的推理。
3.2 实验设置
-
Datasets:实验在三个条件推理问答数据集上进行:ConditionalQA、BoardgameQA和ShARC。它们分别含有关于公共政策、棋盘游戏规则、对话式规则等不同领域的推理问题。
-
LLM Setup:实验使用了三种不同规模的语言模型:GPT-3.5(175B)、Mixtral(47B)和Mistral(7B)。它们都在自然语言和代码语料上进行了预训练。
-
Implementation details:论文采用prompt engineering的少样本学习方法。对每个问题,构造一个由系统提示和3个演示样例组成的prompt。性能评估指标为精确匹配(EM)和F1分数。
-
环境:GPT-3.5通过API调用;Mixtral在A100 GPU上使用4位量化;Mistral在A100 GPU上使用FP16。
3.3 实验结果
3.3.1 实验一、代码提示 vs. 文本提示
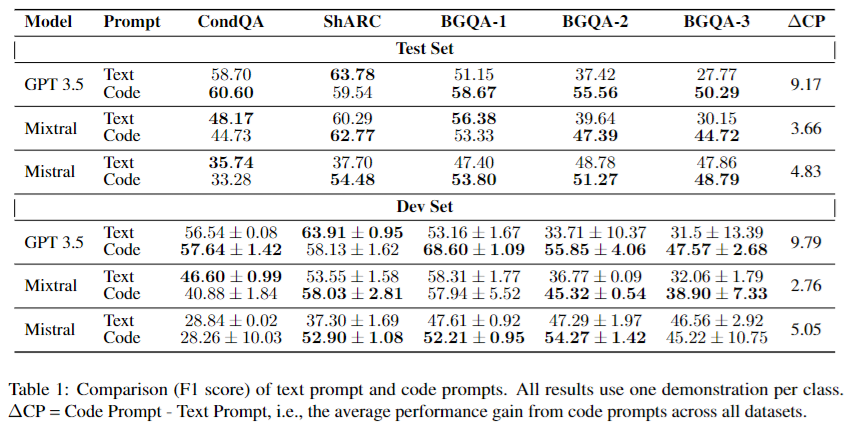
目的:在三个数据集上比较代码提示和文本提示的性能,验证代码提示在触发LLMs条件推理能力上的优势。
涉及图表:表1
实验细节概述:分别用代码提示和文本提示在三个模型(GPT-3.5、Mixtral、Mistral)和三个数据集上进行评测,比较它们的F1分数。
结果:
-
在15组实验中,代码提示有11组优于文本提示。性能提升最大的是GPT-3.5在BGQA-2/3上(>18%)。
-
代码提示在推理难度更大的数据集(如BGQA-2/3)上的优势更加明显。
-
即使在代码提示表现不及文本提示的情况下,其平均下降幅度(3.29%)也远小于代码提示的平均提升幅度(10.48%)。
3.3.2 实验二、代码语法的作用
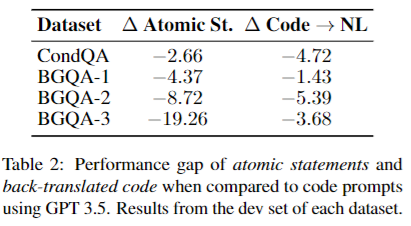
目的:探究代码提示的性能提升是来自于将文本简化为前提,还是代码语法本身具有触发推理的特性。
涉及图表:表2
实验细节概述:设计两组消融实验:(1)将问题转化为原子语句,保留简化的文本形式;(2)将代码提示翻译回接近自然语言的形式。观察性能变化。
结果:
-
无论是原子语句还是翻译回自然语言,都无法达到代码提示的性能,性能下降2.66~19.26个百分点不等。
-
这表明代码提示的优势不仅仅来自于对文本的简化,代码的语法特性本身有助于触发LLMs的推理能力。
3.3.3 实验三、代码语义的重要性
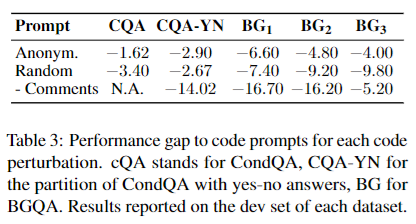
目的:探究代码提示的有效性是否依赖于代码语义与原问题的契合度。
涉及图表:表3
实验细节概述:设计三组消融实验:(1)对代码中的变量和函数进行匿名化处理;(2)用其他问题的代码替换原代码;(3)移除代码中的自然语言注释。
结果:
-
三组实验的性能均显著下降,幅度在1.62~16.70个百分点之间。其中随机代码与移除注释的影响最大。
-
这表明代码语义与原问题的契合度很重要,是代码提示有效性的基础。尤其是自然语言注释不可或缺,它为语义对齐提供了重要线索。
3.3.4 实验四、代码提示的样本效率

目的:探究代码提示相比文本提示在小样本学习中的样本效率。
涉及图表:图3
实验细节概述:固定GPT-3.5模型,改变提示中的演示样例数量(1~3),观察代码提示和文本提示在三个数据集上的性能变化趋势。
结果:
-
当演示样例数量较少时(如1个),代码提示和文本提示的性能差距最大。随着样例数增加,差距逐渐缩小。
-
1个代码样例的性能就能胜过3个文本样例,体现了代码提示的样本效率优势。
-
代码提示以更少的演示样例达到了与文本提示相当甚至更好的效果,证实了其在小样本学习中的高效性。
3.3.5 实验五、代码提示增强变量追踪能力
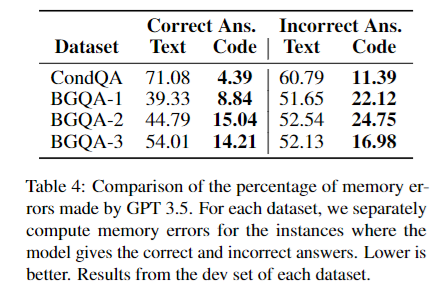
目的:探究代码提示提高LLMs推理性能的原因:是否在于其增强了模型在推理过程中对变量状态的追踪能力?
涉及图表:表4
实验细节概述:在生成过程的不同步骤截断LLM,测试其对关键变量取值的追踪准确率,并比较代码提示和文本提示的差异。
结果:
-
在所有数据集上,文本提示的变量追踪错误率显著高于代码提示,高出30~66个百分点。
-
实验证实,代码提示通过增强LLMs在推理链条上的变量状态追踪能力,从而提高了整体的推理性能。这可能得益于编程语言天然的变量特性。
4 总结后记
本论文针对大语言模型(LLM)在条件推理任务上的不足,提出了一种代码提示(code prompting)的方法。该方法将自然语言问题转化为类Python的伪代码形式,借助编程语言的语法结构来明确表达问题中蕴含的条件逻辑,并辅以自然语言注释来保留原问题的语义信息。在三个条件推理数据集上的实验表明,代码提示能够显著提升GPT-3.5、Mixtral、Mistral等LLM的推理性能,优势在推理难度更大的任务上尤为明显。
疑惑和想法:
-
除了类Python语法,是否可以探索其他编程语言(如Lisp、Prolog)在表征逻辑推理任务上的潜力?不同语言的特性可能带来哪些独特的优势?
-
代码提示能否用于增强LLM在其他类型推理任务(如多跳推理、因果推理)上的表现?需要对现有方法做哪些针对性的改进?
-
能否将代码提示与当前常用的思维链(chain-of-thought)提示方式相结合,进一步提升LLM的推理能力和可解释性?
-
在将自然语言问题转化为代码的过程中,如何更好地平衡信息丢失和逻辑表达之间的trade-off?是否可以借助更先进的语义解析技术?
可借鉴的方法点:
-
利用编程语言的语法和语义特性来增强LLM对任务的理解和建模,这一思想可以拓展到其他需要逻辑推理的NLP任务,如语义解析、程序综合等。
-
在代码中以注释形式保留自然语言问题的做法可以借鉴到其他将形式语言与自然语言相结合的场景,如将知识图谱与文本对齐。这有助于同时利用结构化和非结构化信息。
-
代码提示中将问题转化为可执行逻辑的思路,与当前流行的可执行语义解析(executable semantic parsing)范式不谋而合。这一连接有望带来新的研究机会。
-
利用少样本学习来快速让LLM适应新的提示范式,避免从头训练的方法简单高效,可以用于加速其他形式的提示工程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









