







【摘要】在过去的十年里,机器学习革新了计算机分析文本的能力。由于与书面语言的结构相似性,transformer架构也在一系列多元序列中显示出前景,从蛋白质结构、音乐、电子健康记录到天气预报。我们也可以用一种与语言结构相似的方式来表示人的生活。从一个角度来看,生活就是一系列事件:人出生、看儿科医生、上学、搬家、结婚等等。在这里,我们利用这种相似性来改编自然语言处理的创新,基于详细的事件序列检查人类生活的演变和可预测性。我们利用现存最全面的登记数据,涵盖几十年来超过600万个人。我们的数据包括与健康、教育、职业、收入、住址和工作时间相关的信息,记录时间精度为天。我们在单一向量空间中创建生活事件的嵌入,显示该嵌入空间稳健且高度结构化。我们的模型能够预测从早期死亡率到个性细微差别等各种结果,大幅超越最先进的模型。使用深度学习模型解释的方法,我们探索算法以了解实现预测的因素。我们的框架允许研究人员识别可能影响生活结果的新潜在机制以及相关的个性化干预的可能性。
原文:Using Sequences of Life-events to Predict Human Lives
地址:https://www.nature.com/articles/s43588-023-00573-5
代码:未知
出版:NC
机构: 丹麦技术大学, 宾夕法尼亚大学
1 研究问题
本文研究的核心问题是: 如何利用详细的生活事件序列数据,借助深度学习方法,预测人类生活中的各种结果。
::: block-1
想象一下,有一个人一生中会发生各种事情:出生、就学、工作、搬家、结婚、生病等。如果我们把所有这些事件按时间顺序排列起来,就形成了一个关于此人生活的长序列。那么仅根据这个序列本身,我们能在多大程度上预测这个人未来的命运,比如是否会英年早逝,是外向还是内向?这就是本文要探讨的问题。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 传统的社会人口学研究通常只关注少数几个因素对生活结果的影响,难以全面刻画生活的复杂性。而要建立从生活事件序列到生活结果的端到端预测模型,需要超大规模、高维度、时序性强的数据支持。
- 生活事件序列数据来源广泛,格式多样,如何将它们统一表示成规整的形式,并保留关键信息,是一大挑战。此外,不同事件发生的时间跨度很大,如何平衡建模长期依赖和短期细节也是难题。
- 个人生活事件序列虽然在时间跨度和维度上超过了大多数自然语言文本,但可用于训练的样本数量要少得多。如何在"低资源"情况下,充分利用transformer等强大的语言模型是一个问题。
- 除了预测准确率,如何解释模型学到的表征,揭示生活事件之间有意义的联系,也是一个重要而困难的问题。黑盒模型的可解释性一直是个热点难题。
针对这些挑战,本文提出了一种数据驱动、语言启发的"life2vec"方法:
::: block-1
本文利用丹麦全国人口登记数据,涵盖超过600万人十多年的健康、职业、教育、收入等生活事件,将其统一组织成类似自然语言的序列形式。就像transformer模型可以学习单词的向量表示,捕捉它们之间的关系,life2vec模型可以学习不同生活事件的向量表示,刻画它们之间的联系。采用类似BERT的掩码语言建模和序列排序预测任务,life2vec可以在自监督学习中习得个人生活事件序列的鲁棒且有意义的表征。在此基础上,life2vec可以用于各种下游的生活预测任务,如死亡风险和人格特质预测,并大幅超越传统方法。通过注意力分析等工具,研究人员还可以检视模型学到的事件表征,发现隐含的关联模式,为因果分析和个性化干预提供启发。就像自然语言处理为人工智能注入新动力一样,life2vec展示了将人类生活序列化建模,用数据驱动、语言启发的方法来理解生命奥秘的巨大潜力。
:::
2 研究方法

2.1 数据准备与预处理
本文使用了丹麦的全国人口登记数据,包括从2008年1月1日到2015年12月31日每个居民的事件数据。数据包括与健康、教育、职业、收入、地址和工作时间相关的信息,时间精确到天。
举个例子,一条记录可能包含如下信息:“2012年2月24日,Francisco作为守卫在Elsinore的一个城堡工作,获得2万丹麦克朗的收入。” 另一个例子是:“Hermione在寄宿中学三年级期间选修了5门课程”。这样,一个人的生活就被表示为这些事件组成的序列。
在数据预处理阶段,研究者将原始的时间流数据编码为一种类似于语言的形式。具体来说,离散特征的每个类别以及离散化的连续特征都形成了一个词汇表。这个词汇表连同时间编码,允许我们将每个生活事件(包括其详细的限定信息)表示为由合成词组成的句子。每个事件还附加了两个时间指标:一个指定事件发生时个人的年龄,另一个捕获绝对时间。
2.2 Life2vec模型架构
Life2vec模型基于Transformer架构,主要包括三个组件:嵌入层、类BERT编码器和任务特定的解码器。
嵌入层将生活序列转换为密集表示。给定一个序列,模型在嵌入矩阵中查找token的表示,每一行对应词汇表中的一个token。此外,它还查找段落嵌入。对于年龄和绝对时间位置,它使用Time2Vec方法对时间进行建模。序列中每个token的时间表示是通过对应的token嵌入和句子的时间嵌入求和得到的。
编码器由多个编码器块组成,每个块处理输入表示并将结果传递给下一个编码器。每个块的架构相同,由多头注意力、位置前馈层和两个残差连接组成。多头注意力模块由多个注意力头组成,分别处理输入表示。我们使用Performer风格的注意力头来捕捉全局交互,使用softmax注意力头来建模局部交互。
解码器是全连接的神经网络。对于序列分类任务,我们对最后一层编码器的每个token的上下文表示进行池化,并使用这些token的加权平均值生成序列表示。这个序列表示,即个人摘要向量,通过解码器进行预测。
2.3 模型训练
Life2vec的训练分为两个阶段:学习数据的整体结构(预训练)和特定任务推理(微调)。
在预训练阶段,life2vec通过掩码语言建模(MLM)和序列顺序预测(SOP)任务来学习concept token的嵌入并优化编码器组件的参数。MLM任务迫使模型学习concept token之间的关系,而SOP任务则关注生活序列的时间连贯性。
在微调阶段,我们用预训练阶段优化的参数初始化模型,并为模型分配新的任务(即去掉MLM和SOP编码器),这涉及初始化一个新的解码器网络。我们在两个任务上评估life2vec模型:死亡率预测和个性细微差别预测。对于死亡率预测,我们使用加权平均concept表示的池化注意力解码器。对于个性预测,我们只池化[CLS] token的上下文表示并通过解码器网络进行预测。
直觉上,预训练阶段教会了模型人生事件序列的一般模式,而微调阶段则训练模型从这些模式中提取与特定预测任务相关的信息。这就好比先教会学生基本的语法和词汇,然后再训练他们完成特定的写作任务。
3 实验
3.1 实验场景介绍
该论文提出了一个基于Transformer的life2vec模型,用于处理大规模人口注册数据,并在早期死亡率预测和人格预测两个任务上进行了实验验证。实验主要探究模型预测性能、概念嵌入空间的语义结构以及个体表示向量等方面。
3.2 实验设置
- Datasets:丹麦全国人口注册数据,包含6百万居民10年间的日常生活事件序列,涵盖健康、职业、收入、居住地等多个维度的信息。
- Baseline:
- 早期死亡率预测:寿命表、Logistic回归、前馈神经网络、RNN等
- 人格预测:随机猜测和RNN
- Implementation details:
- 预训练阶段采用掩码语言建模和序列顺序预测任务,30个epoch
- 下游任务微调阶段,不同编码器层使用不同学习率以避免灾难性遗忘,冻结部分参数
- 早期死亡率预测任务采用非对称交叉熵损失函数以处理正样本和未标记数据
- 人格预测任务采用混合的加权交叉熵损失函数
- metric:
- 早期死亡率预测:修正的马修斯相关系数(C-MCC)、Lift曲线下面积(AUL)等
- 人格预测:Cohen’s Quadratic Kappa得分
3.3 实验结果
3.3.1 实验一、life2vec在不同任务上的预测性能
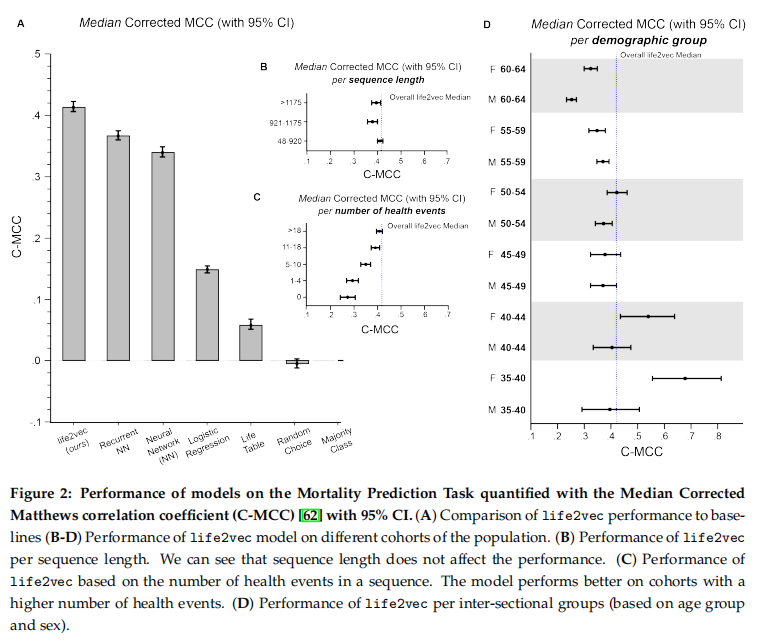
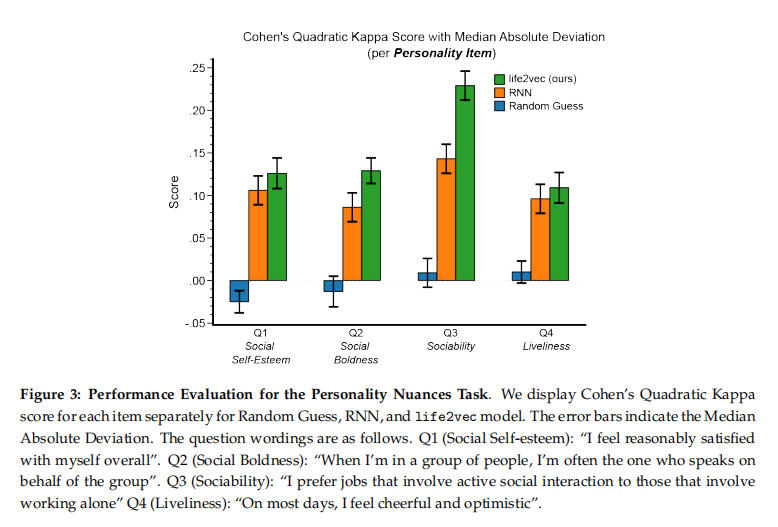
目的:评估life2vec模型在早期死亡率预测和人格细微差别预测任务上的性能,并与基线模型进行对比
涉及图表:图2、图3、表A2、表A3
实验细节概述:
- 早期死亡率预测:预测35-55岁人群在未来4年内的死亡概率,与寿命表、Logistic回归、前馈神经网络、RNN等基线模型对比
- 人格预测:预测个体在Big Five人格量表的外向性维度的多个题目的回答,与随机猜测和RNN模型对比
结果: - 早期死亡率预测:life2vec以0.41的C-MCC分数超过基线模型11%
- 人格预测:life2vec在所有题目上超过RNN模型,在部分题目上显著优于RNN
3.3.2 实验二、概念嵌入空间分析
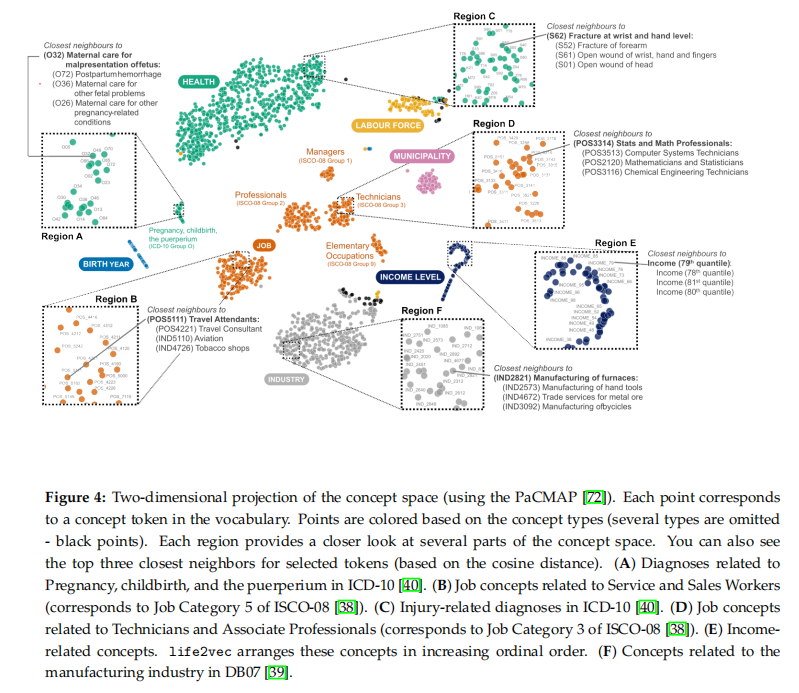
目的:分析life2vec模型学习到的概念嵌入空间,考察其语义结构的合理性
涉及图表:图4
实验细节概述:将280维概念向量投影到二维平面,观察不同类别概念的聚类情况,并分析最近邻概念的相关性
结果:
- 整体上,概念空间按照诊断、职业类型、收入等不同类别有明显的聚类结构
- 局部上,在每个聚类内,最近邻概念在语义上高度相关,如怀孕相关诊断聚在一起
- 跨类别的最近邻概念也有合理的联系,如"旅行社"与"旅游顾问"、"航空业"的概念接近
3.3.3 实验三、个体表示向量分析
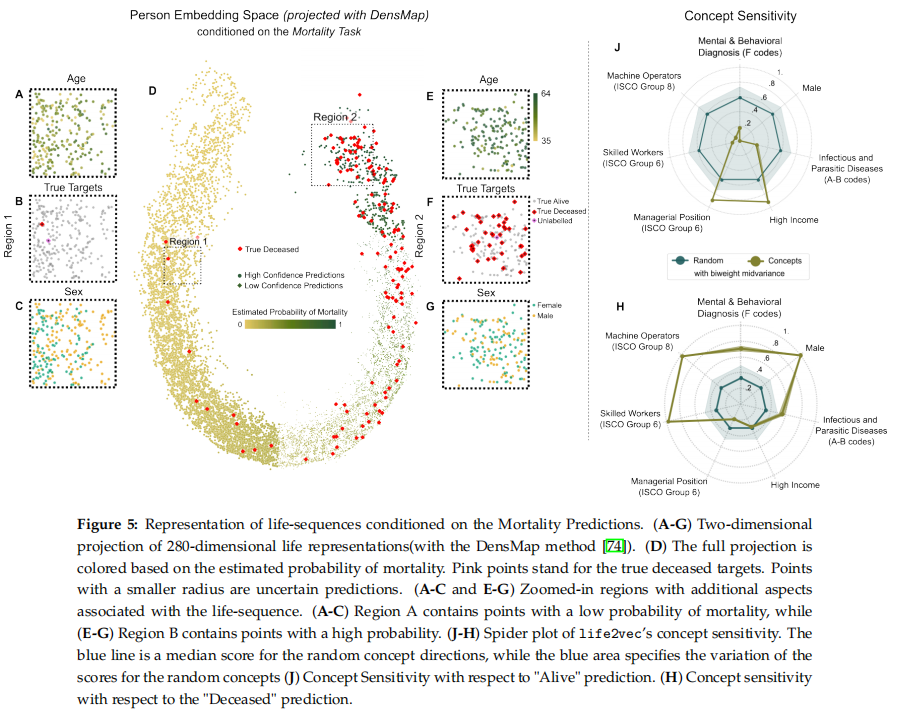
目的:探究life2vec模型为个体生成的表示向量,理解模型如何利用生命序列信息做出预测
涉及图表:图5
实验细节概述:
- 可视化早期死亡率预测任务中个体的表示向量,考察向量空间的结构
- 使用TCAV技术(Testing Concept Activation Vectors)分析表示空间中的方向与模型预测的关系
结果: - 模型可以很好地区分高风险和低风险个体,二者在表示空间中有明显的分布差异
- 管理岗位、高收入等概念方向有利于存活预测,而男性、精神疾病等方向有利于死亡预测
3.3.4 实验四、模型性能的人口统计分析
目的:在不同人口统计属性划分的子群体上评估模型性能,探讨影响模型预测的相关因素
涉及图表:图2、图A.6-A.9
实验细节概述:按年龄、性别等属性对人群做分组,分别评估模型在这些子群体上的预测指标
结果:
- 模型在年轻人群、女性人群上性能更好
- 生命事件序列的长度对模型性能影响不大,但健康相关事件数量较多的人群上模型表现更好
- 死亡时间距离预测时间越近,模型的预测性能越好
- 不同性别和健康事件数量的组合对模型性能有交互影响
4 总结后记
本论文针对利用社会经济和医疗数据预测个人生活轨迹和生活结果的问题,提出了一种基于Transformer的life2vec模型。通过将生活事件序列映射到高维嵌入空间,并利用该嵌入表示进行下游预测任务,该模型在预测早期死亡率和个性细微差别等任务上取得了优于现有最佳方法的效果。此外,所学习的概念嵌入空间和个人嵌入向量具有很好的可解释性,为理解生活事件之间的关系以及个人生活模式提供了新的视角。
疑惑和想法:
- 除了医疗和社会经济数据,是否可以引入其他形式的数据(如社交网络、购物记录等)来进一步丰富个人生活的表示?
- 所提出的life2vec模型能否推广到其他文化和国家的人口数据,在不同的社会背景下是否依然有效?
- 如何利用因果推断等方法来进一步探究关键生活事件对个人生活轨迹的影响机制?能否提供更有针对性的政策建议?
可借鉴的方法点:
- 将生活事件序列映射到嵌入空间的思想可以推广到其他需要对时序数据建模的场景,如疾病预后预测、用户行为预测等。
- 利用预训练模型提取生活事件和个人嵌入表示,再应用于下游任务的范式值得借鉴,可以显著提升特定人群的预测效果。
- 模型的可解释性分析方法(如概念激活向量)可以应用于其他基于深度学习的社会计算问题,加深我们对复杂社会现象的理解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









