






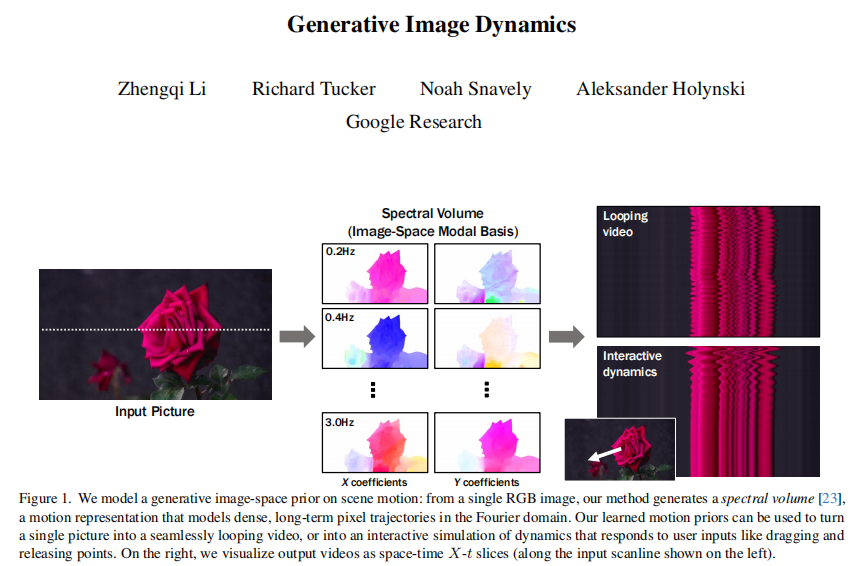
原文:Generative Image Dynamics
地址:https://generative-dynamics.github.io/
代码:未知
出版:CVPR 2024
机构: 谷歌
1 研究问题
本文研究的核心问题是: 如何从单张静止图片生成逼真的长时间动态视频,同时支持用户交互操控。
::: block-1
自然界中的场景往往都处于持续的运动中,比如树叶在风中飘动,烛火在空气中摇曳。一张普通的静止照片虽然定格了瞬间,但人类依然可以轻松想象出其后续的动态变化。如何赋予计算机这种从静止图片构想连续运动的能力,是一个富有挑战和应用价值的研究问题。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 大多数自然运动都有复杂的物理动力学机制,涉及物体的材质特性、外力干扰等因素,很难通过显式建模来还原。
- 要生成连贯、长时间的视频输出,需要对全局的时空演变有整体的把控,而不是单纯地逐帧预测下一帧。
- 用户交互操控要求算法能够灵活适应外部的干预,在保持整体真实感的同时,让指定区域的运动服从用户的意图。
- 从单张图片出发生成动态视频,缺乏显式的运动信息作为监督,需要算法具备强大的先验知识和推理能力。
针对这些挑战,本文提出了一种频域运动先验学习的"生成式图像动力学"方法:
::: block-1
本文的核心思想是从大量真实视频中学习一个频域的运动先验模型,然后用它从单张静止图片生成动态视频。具体来说,作者将视频中每个像素的运动轨迹进行傅立叶变换,得到一种频谱体积(Spectral Volume)的紧致表征。频谱体积可以用很少的参数刻画周期性运动的基本特征。接下来,作者训练一个以静止图片为条件的扩散模型,让它学会生成符合真实场景的频谱体积。生成过程采用了频率协同去噪的策略,即不同频段的参数并不独立预测,而是通过注意力机制相互影响,以确保整体运动的连贯性。最后,作者用一个基于运动的图像渲染模块,将生成的频谱体积还原为连续的视频帧。实验表明,该方法生成的视频不仅视觉质量高,而且可以任意延长,变速,或接受用户交互。同时作者发现,频谱体积还可以当作一种图像空间的模态基,用于模拟物体在不同外力下的响应,实现逼真的交互效果。
:::
2 研究方法
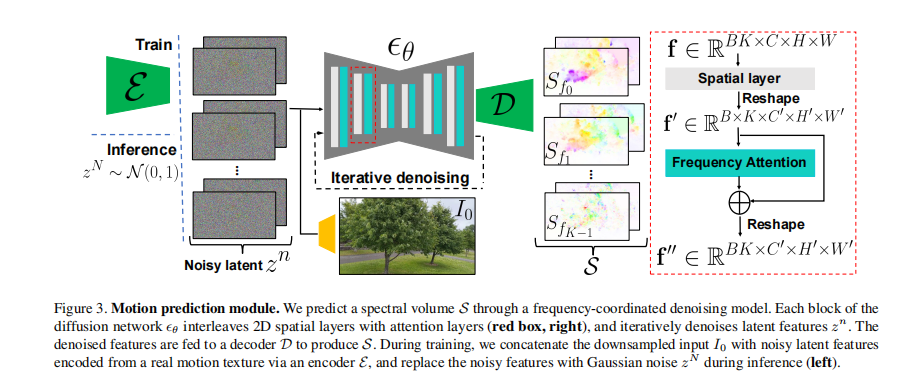
2.1 运动预测
本文的核心是从单幅图像预测未来的运动轨迹。为了高效地建模长期运动,作者将视频中每个像素的运动轨迹
F
(
p
)
=
{
F
t
(
p
)
∣
t
=
1
,
2
,
.
.
.
T
}
F(p) = \{F_t(p)|t=1,2,...T\}
F(p)={Ft(p)∣t=1,2,...T} 表示在频域,即谱体积(spectral volume)
S
(
p
)
=
{
S
f
k
(
p
)
∣
k
=
0
,
1
,
.
.
T
2
−
1
}
S(p) = \{S_{f_k}(p)|k=0,1,..{T\over 2}-1\}
S(p)={Sfk(p)∣k=0,1,..2T−1}。谱体积可以通过对运动轨迹做快速傅里叶变换(FFT)得到:
S
(
p
)
=
F
F
T
(
F
(
p
)
)
S(p) = FFT(F(p))
S(p)=FFT(F(p))
举个例子,一段树叶飘动的视频,我们可以提取出每个像素 p p p 在每一时刻 t t t 的位移向量 F t ( p ) F_t(p) Ft(p),形成一段运动轨迹 F ( p ) F(p) F(p)。将 F ( p ) F(p) F(p) 做FFT就得到了频域表示的谱体积 S ( p ) S(p) S(p)。直觉上, S ( p ) S(p) S(p) 刻画了像素 p p p 振荡运动的频率、振幅和相位信息。
为了预测谱体积,作者训练了一个以图像为条件的latent diffusion model (LDM)。模型的输入是静止图像
I
0
I_0
I0 以及随机噪声,输出是对应的谱体积。训练时,先将视频中提取的真实谱体积
S
S
S 编码为隐空间特征
z
0
=
E
(
S
)
z_0=E(S)
z0=E(S), 然后加入高斯噪声得到
z
n
z_n
zn。接着用U-Net
ϵ
θ
\epsilon_\theta
ϵθ 去噪
z
n
z_n
zn,并用重构损失监督:
L
L
D
M
=
E
n
,
ϵ
n
[
∣
∣
ϵ
n
−
ϵ
θ
(
z
n
;
n
,
c
)
∣
∣
2
]
\mathcal{L}_{LDM} = \mathbb{E}_{n,\epsilon_n}[||\epsilon_n - \epsilon_\theta(z_n;n,c)||^2]
LLDM=En,ϵn[∣∣ϵn−ϵθ(zn;n,c)∣∣2]
其中
c
c
c 是图像
I
0
I_0
I0 的嵌入表征。推理时,先从高斯分布采样噪声
z
N
z_N
zN,然后迭代去噪得到干净的隐空间特征
z
^
0
\hat{z}_0
z^0,最后用解码器重构出预测的谱体积
S
^
=
D
(
z
^
0
)
\hat{S}=D(\hat{z}_0)
S^=D(z^0)。
这就好比我们要还原一副被高斯噪声污染的谱体积,先把它编码到隐空间,然后用去噪器一步步去噪,最终从隐空间解码出干净的谱体积。
具体来说,为了更好地建模不同频率分量之间的关系,作者提出了一种频率协同去噪(frequency-coordinated denoising)策略。即先用一个基础的LDM单独预测每一个频率分量,然后在此基础上插入用于建模不同频率之间关系的注意力层,并进行finetune。
预测得到谱体积
S
^
\hat{S}
S^ 后,应用逆傅里叶变换就可以得到时域的运动纹理
F
^
\hat{F}
F^:
F
^
(
p
)
=
F
F
T
−
1
(
S
^
(
p
)
)
\hat{F}(p) = FFT^{-1}(\hat{S}(p))
F^(p)=FFT−1(S^(p))
2.2 基于图像的渲染
有了运动纹理 F ^ \hat{F} F^,就可以对源图像 I 0 I_0 I0 进行变形,渲染出未来帧。作者采用了一个基于运动场softmax splatting的技术。
具体来说,先用一个特征提取网络对 I 0 I_0 I0 提取出多尺度特征图。然后用预测的运动场 F ^ t \hat{F}_t F^t 对每个尺度的特征图进行softmax splatting,得到time step t t t 的变形特征图。其中运动场 F ^ t \hat{F}_t F^t 的L2范数作为深度的代理指示了前景的运动物体。变形后的多尺度特征图再输入到一个图像合成解码器中,即可得到渲染结果 I ^ t \hat{I}_t I^t。
splatting的过程就像是用运动场 F ^ t \hat{F}_t F^t 在特征图上挪动像素。距离越远的像素权重越小,距离近、L2范数大的像素权重越高,更优先可见。这样经过融合就能得到运动物体在未来时刻的变形结果。
综上所述,本文提出的方法可以从静止图像出发,先预测像素级别的运动轨迹谱体积,再渲染合成未来帧,从而生成逼真的动态视频。这一方法为图像动画合成开辟了一条新思路。
7 实验
7.1 实验场景介绍
本文提出了一种从单幅图像生成自然振荡动态视频的方法,实验部分主要通过定量和定性评估,验证所提出方法生成视频的质量,以及与其他基线方法的对比效果。
7.2 实验设置
- Datasets:从在线来源和自采集视频中收集处理了3015个展示振荡运动的自然场景视频,其中10%作为测试集,其余用于训练。使用光流方法提取每帧相对于起始帧的运动轨迹作为监督信号。最终获得超过15万个图像-运动对作为训练数据。
- Baseline:比较了多个最新的单图像动画生成和视频预测方法,包括:Stochastic-I2V、MCVD、LFDM、DMVFN、Endo et al.、Holynski et al.等。
- Implementation details:
- 采用LDM作为运动预测模块的主干, VAE+2D U-Net进行频谱体积预测,通过频率协调去噪改进
- 图像渲染模块使用ResNet-34作为特征提取器,基于条件图像修复架构设计合成网络
- 推理时以25FPS实时渲染,使用DDIM采样250步生成频谱体积
- metric:
- FID、KID:评估合成帧与真实帧分布的距离
- FVD、DTFVD:评估生成视频的质量和时序一致性
- 滑动窗口FID、DTFVD:评估生成视频质量随时间的退化情况
7.3 实验结果
实验1、在测试集上的定量比较
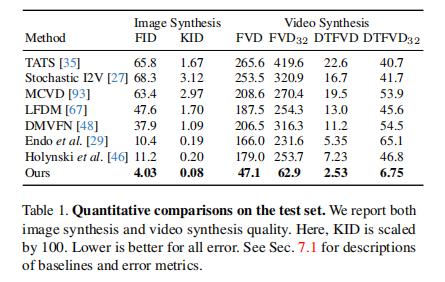
目的:评估本文方法与其他基线在生成帧质量和视频质量上的优劣
涉及图表:表1、图6 \
实验细节概述:在收集的测试集上,使用FID、KID等指标评估生成帧的质量,用FVD、DTFVD等指标评估生成视频的整体质量和时序一致性。
结果:
- 本文方法在所有指标上显著优于现有的单图像动画生成基线方法
- 更低的FVD和DTFVD表明本文生成的视频更加逼真,时序一致性更好
- 滑动窗口指标结果说明,得益于全局的频谱体积表示,本文方法生成的长视频质量不会随时间退化
实验2、定性结果展示

目的:直观展示不同方法生成视频的视觉质量和运动模式
涉及图表:图5
实验细节概述:将生成的视频可视化为时空X-t切片,直观比较不同方法生成视频中的运动模式。 \
结果:
- 本文方法生成的视频动态与真实参考视频的运动模式最为接近
- 其他基线方法要么无法同时建模外观和运动的真实感,要么运动过于平滑、缺乏振荡特性
实验3、消融实验
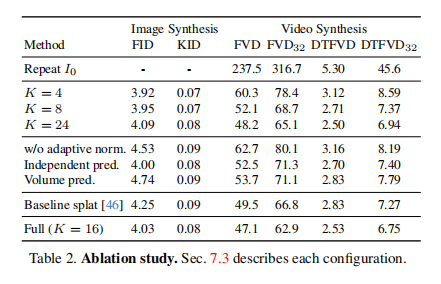
目的:验证关键设计选择对模型性能的影响
涉及图表:表2
实验细节概述:比较不同频率数量K、是否使用频率自适应归一化、频率协调去噪等不同配置下模型的性能表现
结果:
- 频率数量K为16时,在性能和计算效率间取得了较好平衡
- 频率自适应归一化、频率协调去噪等关键设计均有助于提升生成视频的质量
实验4、与大规模视频扩散模型的对比

目的:将本文方法与最新的大规模视频扩散模型进行对比
涉及图表:图7
实验细节概述:随机选取30个测试视频,让用户评估"哪个生成的视频更加逼真"。比较了AnimateDiff、ModelScope、Gen-2等模型。
结果:
- 80.9%的用户更倾向于选择本文方法生成的视频
- 大规模扩散模型要么无法很好地保持输入图像内容,要么生成的视频存在颜色漂移、失真等问题
4 总结后记
本论文针对单图像生成自然运动过程的问题,提出了一种基于频谱体积(spectral volume)表征和扩散模型的运动预测方法。通过预测图像各像素在时域上的Fourier系数,实现了高效、长时间尺度上的图像动画合成。实验结果表明,所提出的方法能够以频率自适应归一化和频率协同去噪等创新点,生成更加真实、连贯的各类自然场景动态视频。
::: block-2
疑惑和想法:
- 除了频谱体积表征,是否存在其他形式的高效时空运动表征方法?不同表征形式的理论性质和实践效果有何区别?
- 在频率协同去噪模块中,不同频率之间的交互机制如何进一步增强,以生成更加真实的复杂运动过程?
- 能否将本文方法与传统的物理引擎相结合,在保证真实感的同时提升可控性和交互性?
:::
::: block-2
可借鉴的方法点: - 频谱体积表征可以推广到其他时空序列建模问题,如音频合成、人体运动合成等。
- 在生成任务中针对不同频率分量设计自适应的归一化和协同去噪方法的思想值得借鉴。
- 利用扩散模型学习自然先验分布,再通过采样实现灵活生成和编辑的范式可以广泛应用到其他条件生成场景中。
:::


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









